
微软最新提出SkillOpt,用训练大模型的方法优化你的Agent Skills
训练大模型这事儿,工程师们心里都清楚——靠一次前向传播就想让模型收敛?想都别想。数据喂养、Batch切分、学习率控制、验证集筛选、优化器状态迭代,哪一步不是反复试错出来的。
可到了Agent Skills这块,当前的工程实践却粗糙得令人摇头:要么手工写一版,要么让LLM单次生成(One-shot),再要么就是Agent执行失败后靠松散的自我修正(Self-revision)追加几条经验。说到底,这还是在“写文档”,根本不是“训练能力”。
为了打破这种脆弱的领域适应现状,来自微软、上海交通大学、同济大学和复旦大学的研究者联合提出了
SKILLOPT

下面拆解这套系统的核心控制流,看看它是如何用纯文本操作复现神经网络训练过程,并最终生成体积不到2000 Token却能够全域迁移的SKILL.md的。
项目地址:https://github.com/microsoft/SkillOpt
SkillOpt的核心概念
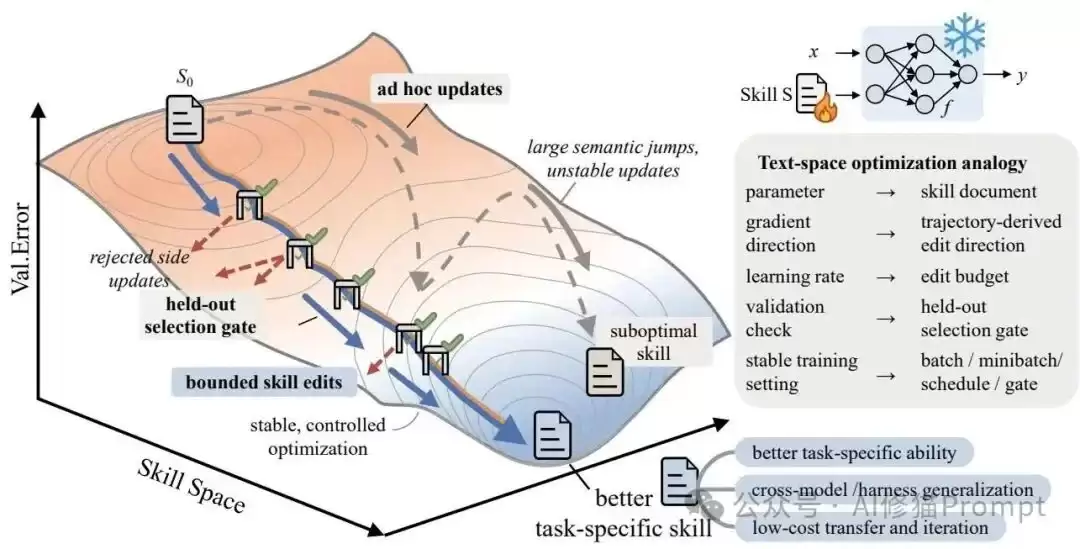
SKILLOPT的核心思想,是建立一个系统化的文本空间优化过程。研究者把深度学习优化中的关键变量一一映射到了自然语言处理层面。这种映射可不是单纯的比喻,而是有实际操作指导意义的系统设计:
- 映射为纯文本的技能文档(Skill Document),也就是部署时用的
参数(Parameter):
best_skill.md。 - 映射为基于轨迹的编辑方向(Trajectory-derived edit direction)。
前向传播与梯度方向(Forward Pass & Gradient):
- 映射为编辑预算(Edit budget),也就是单步允许的最大修改次数。
学习率(Learning Rate):
- 映射为保留的验证选择门(Held-out selection gate)。
验证检查(Validation Check):
- 映射为批处理/微批处理/调度器/门控机制(batch/minibatch/schedule/gate)。
稳定训练设置(Stable Training Setting):
在这种架构下,目标模型(Target Model)及其执行框架(Harness)始终保持冻结,只负责依据当前技能文档执行任务。所有的轨迹分析、编辑提案和合并排序,都由一个独立的优化器模型(Optimizer Model)在离线阶段完成。
SkillOpt系统架构与算法流程解析
SKILLOPT采用了目标执行模型(Target Model)与优化器模型(Optimizer Model)分离的非对称架构。训练阶段,目标模型负责与沙盒环境高频交互提供数据,优化器模型则在后台进行离线反思、合并与精炼,最终输出一份高度浓缩、完全自主可读的最终技能文件(best_skill.md)。
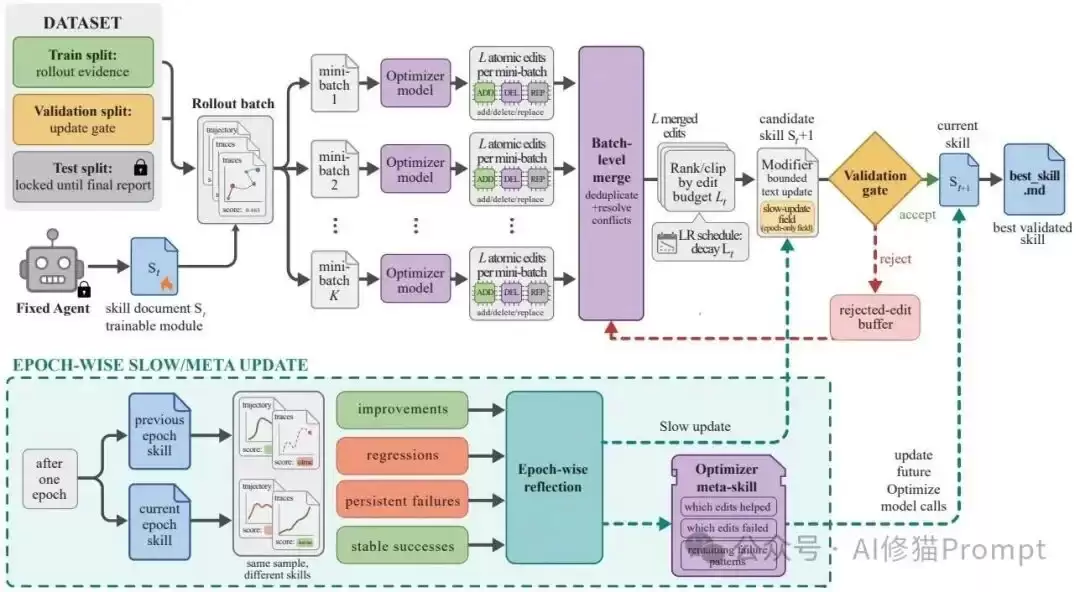
问题定义与数据划分

前向传播:Rollout证据收集
- 每个优化步骤中,目标模型使用当前技能在训练集上运行一个Rollout批次。
- 框架会记录极其详尽的执行上下文,包括任务元数据、消息历史、工具调用、系统观察结果、命令输出、最终答案、验证器反馈,甚至特定基准的上下文(如电子表格预览或代码执行追踪)。
- 批次大小直接控制了更新的噪声水平。系统支持“累积(Accumulation)”机制,允许多个批次独立反思后再合并为一次更新,从而解耦执行吞吐量与更新频率。
反向传播:Minibatch结构化反思
优化器模型并不直接阅读所有轨迹然后输出一段新提示,而是执行结构化的处理:
- 优化器首先把轨迹分成成功和失败两组,再划分为反思微批次(Reflection minibatches)。
成功与失败分离:
- 单个轨迹通常只能产生针对特定用例的修复建议。微批次处理迫使优化器寻找可复用的程序性错误(例如:Agent总是搜索错误的源、输出格式持续错误、或者未能验证工具结果)。失败批次提出缺失规则或纠正规则;成功批次则提取需要保留的有效行为。
寻找通用模式:
- 反思阶段输出的不是自然语言段落,而是严格的JSON补丁(Patch),限定了四种原子操作:
结构化操作定义:
append、insert_after、replace和delete。
分层合并与有界文本更新(学习率机制)
局部提案必须经过分层合并以消除冗余和冲突:

验证门控与拒绝缓冲区

跨周期的慢速/元更新 (Slow/Meta Update)
为了捕获长视野规律,研究者设计了隔离的宏观更新机制:
- 一个Epoch结束时,系统会对比使用上一周期技能与当前技能在相同任务样本上的表现,归类为:改进、退步、持续失败、稳定成功。优化器据此编写一条纵向指导意见,写入技能文档中特定的标记保护区(`` 之间),并同样需要通过验证门控。这保证了快速局部修改无法覆盖长期的程序性经验。
慢速更新(Slow Update):
- 这是一个仅存在于优化器侧的状态。它总结了哪些编辑模式有效、哪些被拒绝、哪些失败在多个Epoch中持续存在。这些指导信息会被注入未来的优化器提示词中,但永远不会随最终工件部署给目标模型,从而实现了“训练记录”与“推理载荷”的解耦。
元技能(Meta Skill):
实验结果与基准测试分析
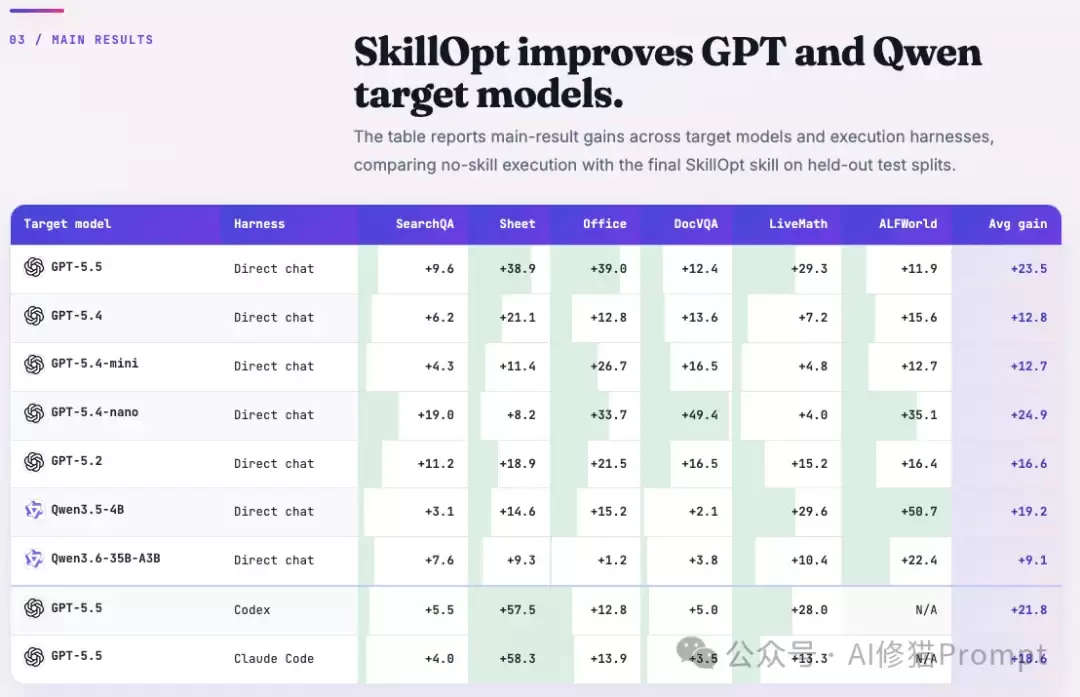
研究者在极其多样化的环境中对SKILLOPT进行了系统性评测。这包括6个基准测试——SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMathematicianBench, ALFWorld;涵盖了单轮问答、高达24次调用的多轮工具循环、复杂代码生成与物理环境状态交互。系统适配了7款模型(从前沿规模的GPT-5.5到4B级别的小模型Qwen3.5-4B)以及3种执行框架(直接对话、Codex、Claude Code)。
核心提升数据
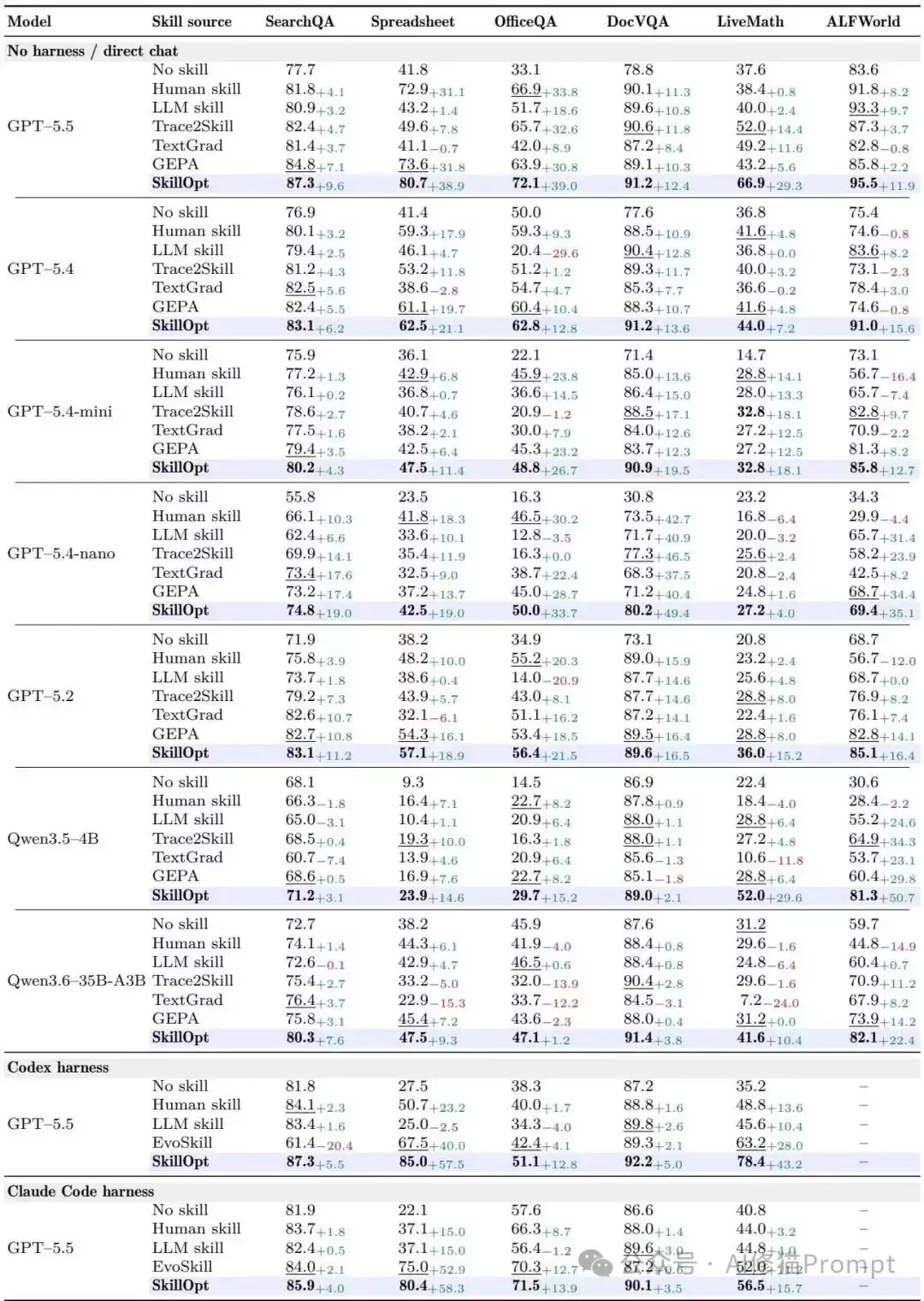
在52个 (模型, 基准, 框架) 的评估单元中,SKILLOPT取得了52项最优或并列最优的成绩。在直接对话、Codex和Claude Code执行环境中,SkillOpt在所有评估单元上取得最优或并列最优结果,且相对无技能基线普遍带来正向提升。
- 在GPT-5.5的直接对话(Direct Chat)场景下,无技能状态的平均得分为58.8,而SKILLOPT将其提升至82.3,绝对值的提升。
+23.5
- 它击败了包括人类专家编写、单次LLM生成、Trace2Skill、TextGrad、GEPA以及EvoSkill在内的所有基准方法,对比各单元内表现最强的竞争对手,仍具备平均 +5.4分的领先优势。
- 对于严苛的程序性工具调用基准,提升幅度极大:GPT-5.5在SpreadsheetBench上从41.8提升至80.7,在OfficeQA上从33.1提升至72.1。
- 小尺寸目标模型的相对收益更高:GPT-5.4-nano在ALFWorld上的得分翻倍(34.3升至69.4)。
工具支持下的执行框架表现
技能作为一种适配层,必须能嵌入现代的CLI或工具沙箱中。
- 在Codex风格的工具循环中,SKILLOPT使得GPT-5.5在五项测试中全面获胜,比无技能基准高出 +24.8分,比此前最强的EvoSkill高出 +14.0分。
- 在Claude Code风格的执行环境中,平均比无技能状态提升 +19.1分。 这些数据证实了文本有界优化能够产生兼容不同执行约束的程序性知识。
消融实验证明的组件必要性
通过剥离关键组件,研究者验证了系统设计的有效性:
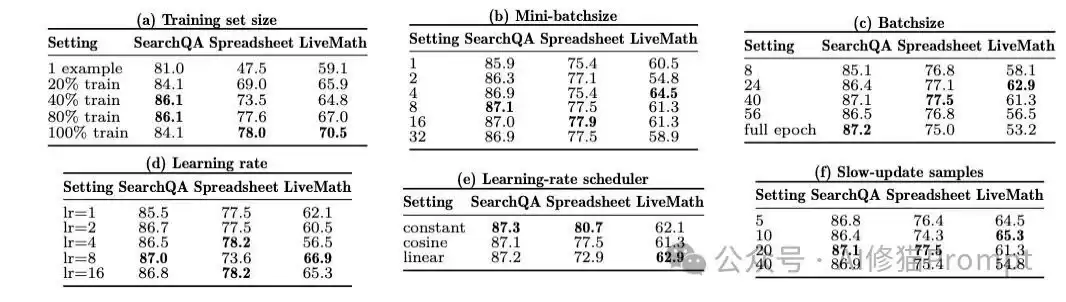
- Rollout批次大小从8增加到全周期,结果变化平缓(SpreadsheetBench稳定在75.0-77.5之间),说明收益不是来自偶然的特定批次调整,而是持续反馈的结果。
证据规模的鲁棒性:
- 当移除文本学习率限制(无边界重写)时,LiveMath的分数从61.3骤降至57.3,SpreadsheetBench从77.5降至75.7。
学习率约束的价值:
- 若同时移除元技能指导和跨周期慢速更新,SpreadsheetBench的得分将从77.5崩盘至55.0(下降 -22.5分),这是所有消融项中最大的性能衰减。这表明长视野证据流和保护区域机制对防止局部过度编辑至关重要。
长期记忆不可或缺:
高价值的工程特性:迁移性与低成本部署
对于资深工程师而言,一项技术的价值不仅在于刷榜,更在于它的工程可用性与边际成本。SKILLOPT导出的文本技能件表现出了极高的通用与复用价值。
跨维度的可迁移性
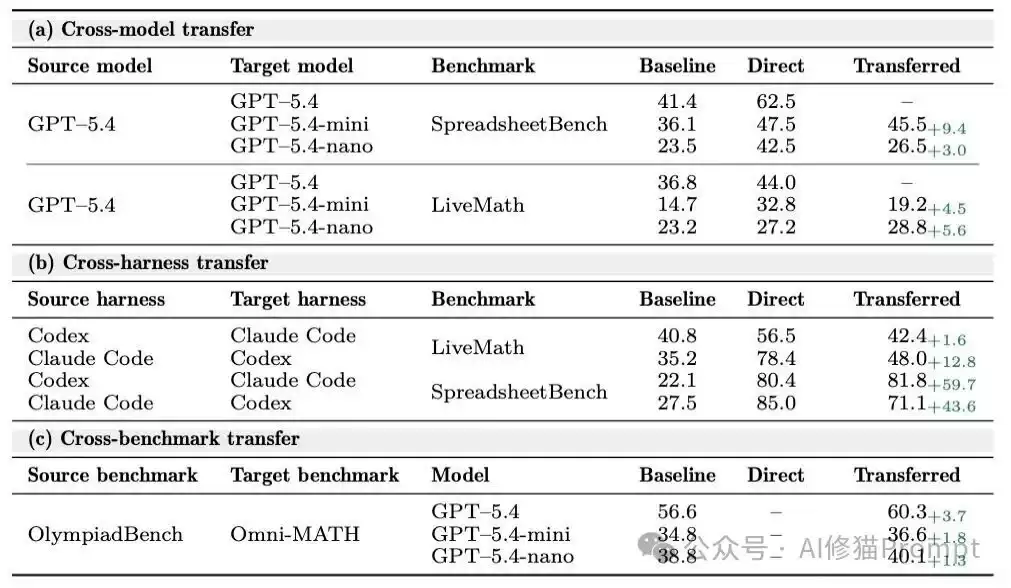
- 在GPT-5.4上训练的SpreadsheetBench技能,直接部署在参数规模更小的GPT-5.4-mini和GPT-5.4-nano上,分别获得了 +9.4和 +3.0的绝对提升。在LiveMath上,迁移的技能在GPT-5.4-nano上甚至超越了原生针对该模型优化的结果(迁移得分28.8对比原生优化27.2)。
跨模型(Cross-model transfer):
- 在Codex环境中优化的电子表格技能被直接投入Claude Code中执行,仍然提供了 +59.7分的绝对增益(从22.1基准分飙升至81.8)。这说明优化器学到的是“先检查工作簿结构、再执行验证”这类深层程序逻辑,而不是特定CLI命令的死记硬背。
跨框架(Cross-harness transfer):
- 在OlympiadBench训练的数学技能迁移至Omni-MATH后,三个模型规模上均取得了正向提升。
跨数据集(Cross-benchmark transfer):
工件分析:紧凑度与成本控制
SKILLOPT证明了高能力的边界模型(作为优化器)可以提炼出低成本推理侧能够完全利用的结晶知识。

- 尽管在四个Epoch中优化器提出了海量编辑方案,但由于严格的Held-out验证门槛,最终被写入
极简的修改次数:
best_skill.md的接受编辑次数仅为(中位数为2.5次)。例如,LiveMath凭借单次被接受的编辑就实现了 +29.3分的提升。1到4次
- 各项基准测试产生的最终技能文件长度介于379 Token(LiveMath)至1995 Token(SpreadsheetBench)之间,中位数约为920 Token。这甚至远小于常见业务系统提示词的预算,工程师几分钟就能读完并审计。
最终形态极其轻量:
- 优化过程的一次性训练Token开销具备极高性价比。对于程序型任务(轨迹较短),每提升1个绝对测试点的成本仅为0.6M到3.6M Token。导出后,推理阶段彻底去除了任何额外的优化器调用与权重更新开销。
训练成本分摊:
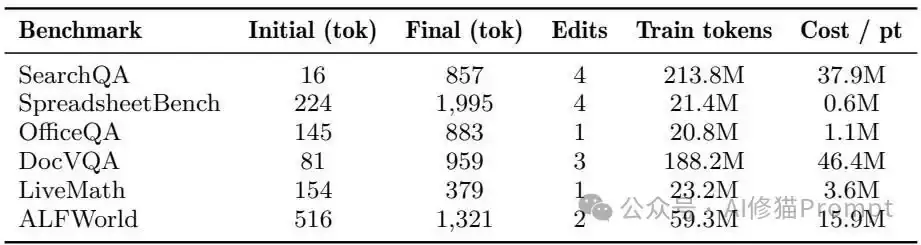
最终技能通常只有数百到约两千Token,且仅由1到4次接受编辑构成;程序型任务的单位测试点训练Token成本最低。
习得技能的语义剖析
分析生成的最终规则能够发现,优化器完全放弃了对具体实例的过拟合,转而生成类似高级工程师总结的最佳实践:

- “先检查工作簿结构和公式,然后将评估出的静态值写入完整的请求目标区域,而不是依赖Excel的自动重新计算。”
SpreadsheetBench:
- “保持一个具备视野感知的已访问/前沿分类账,在遇到同类型重复失败后多样化搜索策略,并在真正拿到目标物体之前避免反复访问目的地。”
ALFWorld:
结语
SKILLOPT最底层的优雅在于对状态读写的严格隔离。优化器侧的元记忆、慢速更新保护区以及拒绝缓冲区均在后台离线完成计算和试错,最终交付给目标模型的,仅仅是一份干净、紧凑的Markdown文件。这种计算前置的设计虽然带来了Rollout阶段的算力消耗,却硬生生将自然语言从不可控的“指令流”,约束成了可验证的“代码逻辑”。正如网络权重需要反向传播来收敛,Agent的底层适应能力也理应拥有这样一套严密的基础设施。SKILLOPT证明了,即便不触碰模型底层的safetensors文件,合理的控制流依然能压榨出极其可观的程序性性能。




