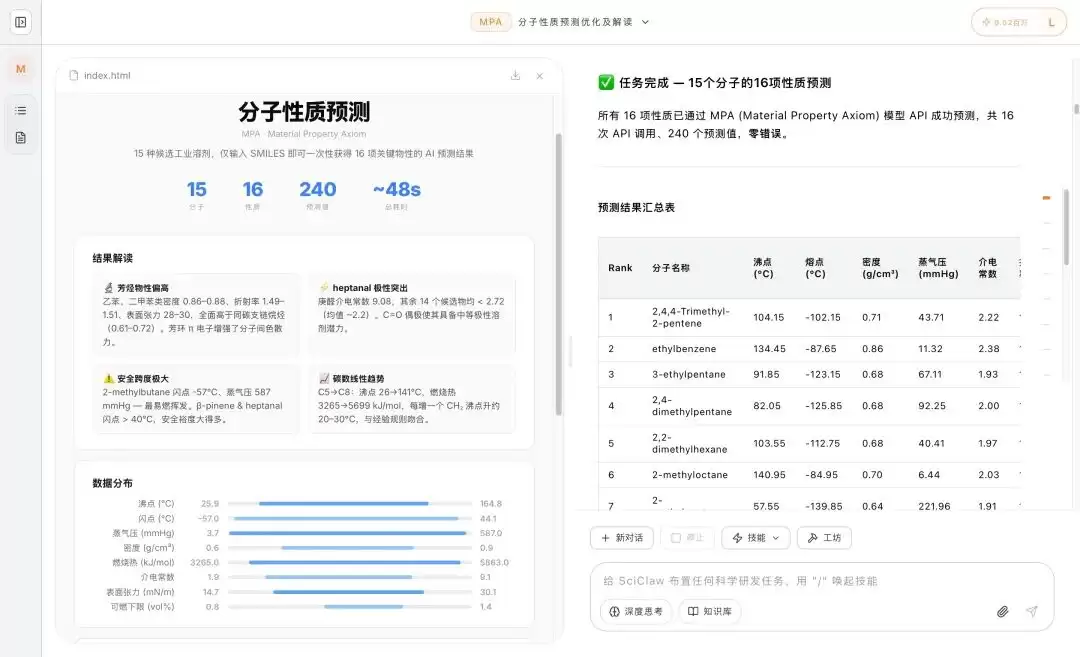
深度原理发布材料基座模型MPA | 以物理对齐提升真实实验性质预测能力
来源:互联网
时间:2026-06-03 07:36:15
从理论计算到真实实验的预测鸿沟
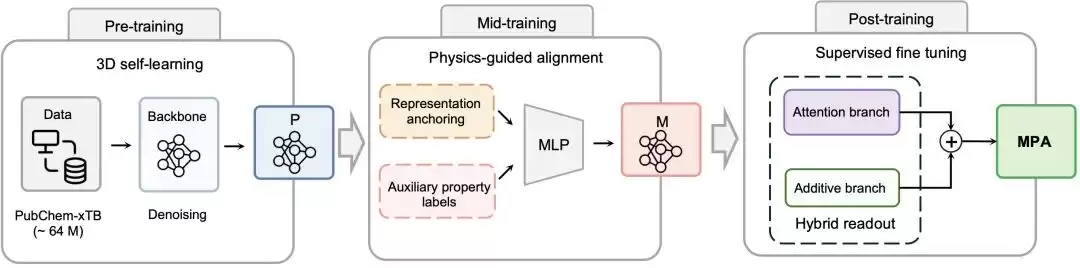
材料性质预测长期绕不开一个核心矛盾:模型在标准基准上考满分,不代表下了考场就能干活。理论计算数据就像教科书,规整、噪声可控,模型能从中学会“结构-性质”的基础知识。但真实实验数据呢?它更像街头实战,充满了各种意外。样品好坏、测试条件偏差、仪器误差……这些因素让数据变得“不干净”,而工业上要预测的性质,也远比单一标准指标更复杂。因此,材料AI模型必须学会“举一反三”,在理论计算和真实实验之间建立稳定的迁移能力。 这正是MPA设计的出发点:通过一套更系统、更讲究的“训练流程”,让模型不光是死记硬背结构特征,更要真正学会与真实性质预测相关的物理规律。借鉴LLM三阶段训练,进行物理对齐
Hybrid Readout:面向实验性质预测的后训练结构
除了训练流程,MPA的另一大亮点在于后训练阶段引入的**混合读出(Hybrid Readout)**。 不同的材料性质,其物理结构也大相径庭。有些性质,比如沸点、生物活性,更依赖材料的整体表征;而另一些,比如生成焓、热容,则有明显的“加和”特征,整体数值由各个原子或局部结构的贡献累积而成。如果对所有性质都用同一种“读法”,模型就得同时学习两套截然不同的规律,难度和所需数据量都会陡增。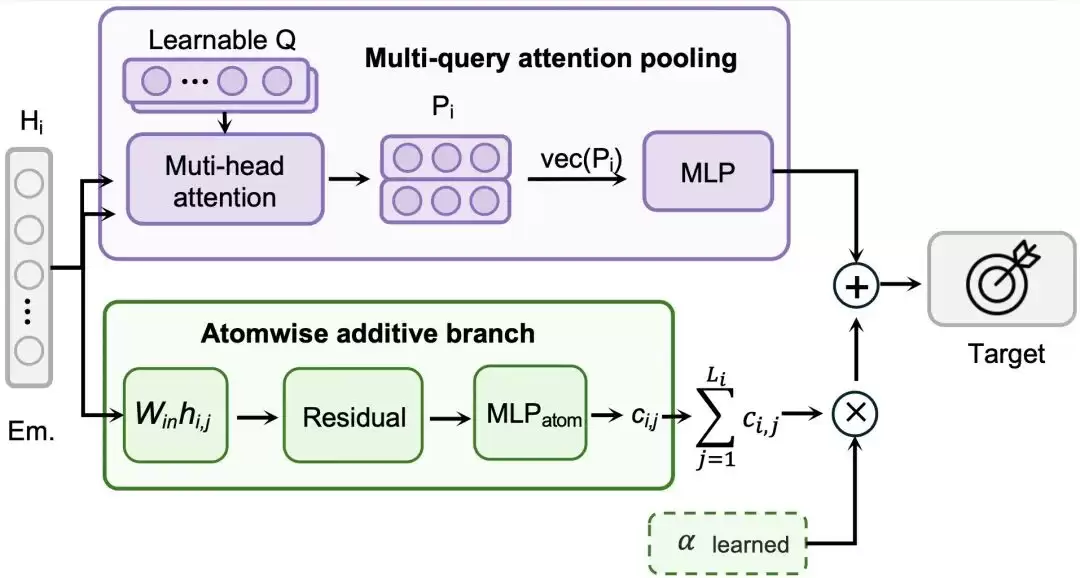
在更接近真实研发的场景中提升更明显
为了验证MPA这套设计是否真的有效,研究团队做了严格的消融实验。对照组使用相同的预训练检查点,但跳过mid-training和Hybrid Readout,直接微调。结果很明显:在40个真实实验性质预测任务中,完整版的MPA在随机划分下有38个任务的预测结果得到提升,平均误差降低了14.0%;而在更具挑战性的骨架划分下,同样有38个任务提升,平均误差降低14.6%。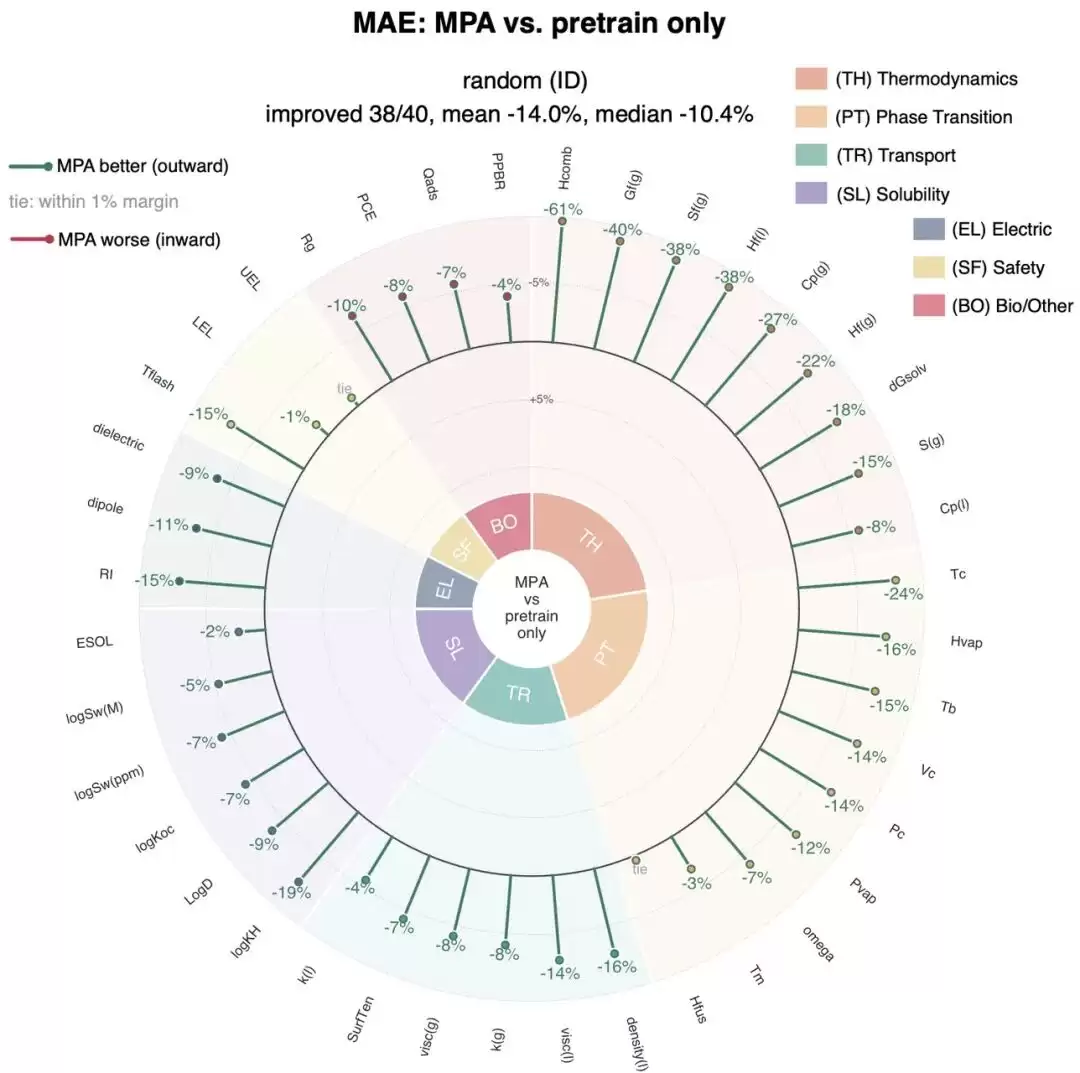

让材料基座模型走向可持续迭代
MPA的意义不止于一个刷榜的模型,它为材料基座模型提供了一条更可持续、更具扩展性的训练路线。过去,不同性质预测任务常常需要各自为战,从模型搭建到数据清洗、参数调优,重复劳动太多,积累的知识也难以沉淀。MPA尝试将第一性原理计算数据、高质量实验数据和面向任务的后训练整合到一个统一的框架里。随着数据和任务类型的增长,模型能通过中期训练和实验反馈不断“自我进化”。 这条路径,与当前LLM的进化史高度一致。能力的跃升,不单单来自预训练规模的扩大,更来自有效的训练、对齐和后训练。 “之前材料基座大模型的scaling效应不明显,很可能就是预训练和复杂下游任务不匹配造成的。” **「深度原理Deep Principle」创始人兼CTO段辰儒**一针见血地指出了问题所在。“现在MPA通过mid-training的物理对齐解决了这个问题。下一步就是扩大模型参数,并收集更大量、更多样的一手数据。” 目前,MPA已经作为一项核心能力,接入了「深度原理Deep Principle」的智能体产品。可以预见,随着计算数据、实验数据和自动化实验能力的不断增长,材料基座模型将从一个单点性质预测工具,逐步进化为支撑整个材料研发闭环的基础设施。