
如何构建可落地的 LLM 测试评估体系
开始之前,有必要先澄清一个认知误区。很多人一上来就急着搭建评估体系,但连最基本的“评估对象”都没想透。
你的系统输出,是确定性的还是概率性的?
这不是一句废话。大多数团队踩坑的根源,就在于把一个概率系统当确定性系统来评估。传统软件测试有个核心假设:相同输入,相同输出。这个假设在 LLM 这儿,彻底不灵了。同一条 prompt,温度参数设成 0.7,跑十次,你会得到十个不同的回答,质量分布可能从 0.6 到 0.95 都有。所以,你评估的不是“这个输出对不对”,而是“这个系统在什么样的概率分布下工作”。
这个认知是整套体系的地基。没有这个认知,后面的一切都是在沙子上建房子。
二、体系的四个层次
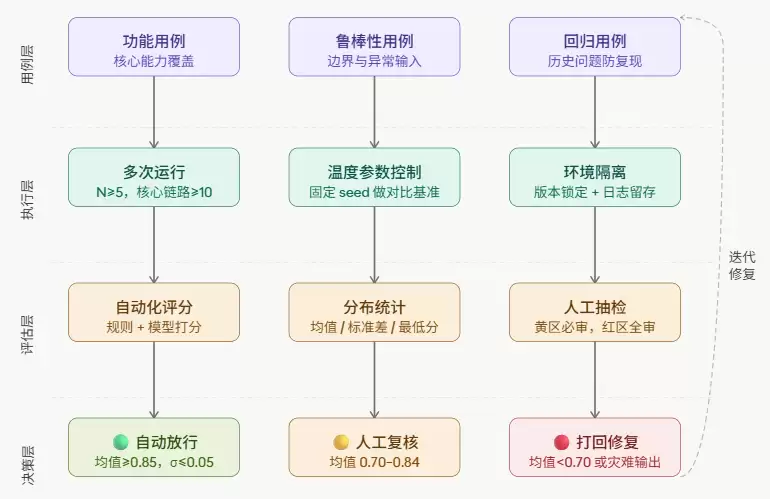
如上面架构图所示,一套完整的 LLM 评估体系由四层构成,缺一不可。下面逐层展开,把每一层的核心设计决策讲清楚。
第一层:用例设计
大多数团队的用例设计,都只覆盖了“正常路径”——给模型一个标准输入,期望它给一个标准输出。这远远不够。
LLM 评估用例需要覆盖三类场景:
功能用例(Happy Path)
鲁棒性用例(Edge Case)
回归用例(Regression)
用例的质量比数量重要。100 条高质量、边界清晰的用例,远胜过 500 条互相重叠的水题。
第二层:执行控制
用例设计好了,怎么跑?这一层的核心原则是:控制变量,留存证据。
关于运行次数
| 场景类型 | 建议运行次数 |
|---|---|
| 普通功能验证 | 5 次 |
| 核心对话链路 | 10 次 |
| 安全 / 合规相关 | 20 次 |
| 上线前全量回归 | 每条用例 ≥ 5 次 |
为什么这么多?因为你需要的不是一个点,而是一条分布。单次结果告诉你的是“今天这一次的运气”,多次运行告诉你的是“这个系统的真实能力区间”。
关于温度参数与 seed
temperature=0(或你生产环境的实际值)来做对比基准测试,排除随机性干扰。评估生产行为时,使用与生产环境完全相同的参数配置,不要在测试里悄悄调低温度。这是最常见的“测试环境比生产环境好”的原因之一。如果 API 支持固定 seed,每次回归测试时对同一批用例使用相同 seed,可以精确追踪版本变化带来的质量差异。关于版本锁定与日志
第三层:评估打分
这一层是整套体系最复杂、分歧最大的部分。核心问题是:谁来判断输出质量?
评估方法从低成本到高成本,大致有三类:
规则评分(Deterministic Scoring)
json.loads()不报错算一分,包含目标字段再加一分。累积分数归一化到 0-1 区间。模型打分(LLM-as-Judge)
人工审核(Human Review)
报告字段标准
{"case_id": "...","runs": 10,"mean_score": 0.82,"std_dev": 0.09,"min_score": 0.61,"max_score": 0.94,"pass_rate": 0.8,"failure_types": ["格式错误×1", "事实偏差×1"]}只写 result: pass 的报告,等于没写报告。
第四层:分层决策
评估结果出来了,如何做决策?这一层把所有信息汇聚成行动。
绿区:自动放行
mean_score ≥ 0.85 且 std_dev ≤ 0.05,连续多版本均值无显著下滑。动作:自动通过,进入下一个流程节点。不需要人工介入。这一档要设计得足够严格——放宽阈值换来的“通过率提升”是虚假的安全感。黄区:人工复核
mean_score 在 0.70–0.84 之间,或 std_dev > 0.10。动作:进入人工复核队列。复核时区分两种失败模式:失败集中在某类输入格式 → 是 prompt 工程问题,修 system prompt 或 few-shot 示例;失败随机分布、无规律 → 可能是模型能力边界,考虑任务拆分或升级模型。红区:打回修复
mean_score < 0.70,或任意一次出现灾难性输出(严重事实错误、有害内容、逻辑完全崩塌)。动作:一票否决,无论均值多好。灾难性失败不能被平均值稀释。打回后进入修复流程,修复完成后重新进入评估体系。红区的失败分析同样要做分治:如果失败原因是模型本身能力不足 → 评估升级模型或缩小任务范围;如果失败原因是测试用例设计有缺陷 → 修用例,不是修系统。三、五个容易踩的坑
体系搭起来之后,运行过程中有几个高频陷阱,提前说清楚。
坑1:用测试环境的好结果代表生产环境
temperature=0,生产时 temperature=0.8。测试时 context 只有 500 tokens,生产时动辄 4000 tokens。这种环境差异会导致测试通过率虚高 20%-40%。解决方式:测试参数必须与生产完全对齐,用生产环境的真实流量做 shadow testing。坑2:只测新功能,不测老功能
坑3:评估维度不够细,定位不了问题
坑4:把 LLM Judge 当作客观标准
坑5:评估体系和产品迭代脱钩
四、最小可行版本
如果你的团队现在什么都没有,从零开始,应该先做哪些?按优先级排序:
第1步(一周内可完成)
第2步(一个月内)
第3步(稳定运行后)
不要等体系“完整了”再开始。20 条用例 × 多次运行 × 分布统计,已经比单次红绿灯强十倍。
五、最后
LLM 评估体系的核心不是技术难度,是认知转变。
从“这次对了”到“它在什么概率区间下稳定”。从“给一个答案”到“把不确定性显式地写进报告”。从“测试是上线前的检查关”到“评估是持续运行的质量雷达”。
这个转变需要时间,也需要一些说服工作。但 LLM 系统已经在你的生产环境里跑了。它每天在产生不确定的输出。你有没有一套体系,能持续感知这种不确定性、管理它、并在它恶化之前发现它——这才是最值得投入的工程能力。




