
只需几个抽象符号替代思维链,就能将推理成本压缩11倍
2026 年,AI 行业正在经历一场悄然发生的费用危机。
在大多数开发者的印象里,AI 模型的成本在过去几年里一路走低。确实,从 2022 年到 2024 年,前沿模型的推理成本下降了超过千倍。这个趋势让许多团队相信,把 AI 部署进产品只是时间问题。
然而,推理模型的出现打破了这一预期。OpenAI 的 o 系列、Anthropic 的 Claude Extended Thinking、DeepSeek R1——这些模型在生成最终回答之前,会先在内部进行大量“思考”,产生数以千计的中间推理步骤,然后再吐出最终答案。这些中间步骤在账单上有个专门的名字:
推理 token(reasoning tokens)
问题在于,你得为这些思考过程买单,即便你根本看不到它们。
根据行业研究机构在 2026 年初的统计,一个复杂的代码审查任务,如果使用推理模型,费用可能是普通模型的 5 到 10 倍。一次多步骤规划任务,内部思考步骤消耗的 token 数量,有时会超过一万个。有团队测试发现,让 Claude Opus 4.6 和 Grok-4 分别回答同一个问题时,两者给出了完全相同的答案,但 Grok-4 消耗的 token 数量是 Claude 的两倍多,成本差距接近 10 倍。这一切,仅仅因为
模型想得太多
换句话说,
AI 正在为了“把话说清楚”而付出巨大代价
而这种代价,在某种程度上是设计使然。现有的主流推理模型,都依赖一种叫做“
思维链(CoT)
就在这个背景下,IBM Research 的一个团队发布了一篇论文。他们提出了一个问题:
如果 AI 根本不需要用人类语言来思考,会怎样?

- 论文标题:Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought
- 论文地址:https://arxiv.org/pdf/2604.22709
抽象推理链:一门人类看不懂的语言
抽象推理链:一门人类看不懂的语言
IBM Research 的论文将这一方法命名为
Abstract Chain-of-Thought(抽象推理链,简称 Abstract-CoT)
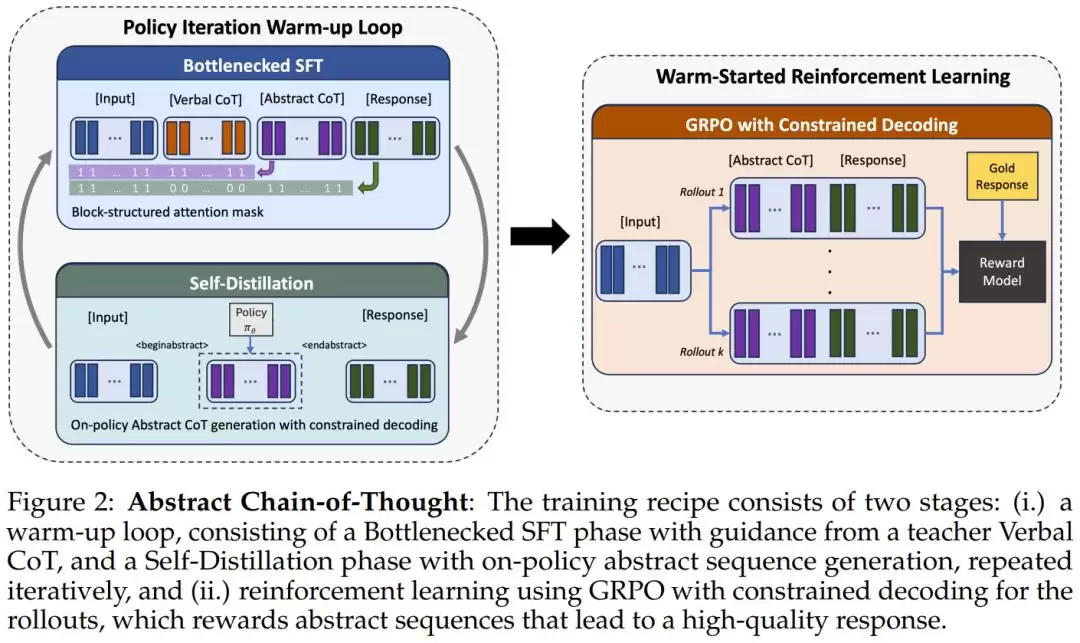
核心思路出人意料地简洁:与其让模型用自然语言写下推理过程,不如给它一套全新的“符号词汇表”,让它用这些符号来思考,然后直接生成答案。
这套词汇表里没有任何一个人类能读懂的单词。它由一组特殊的占位符 token 组成,比如
如果用一个生活中的类比来理解:这有点像一个经验丰富的厨师,不再需要把每一步操作都大声说出来,而是靠一套只有自己理解的手势和记号,在脑子里飞速完成全部计算,然后直接把菜端上桌。对于外人而言,这个过程是不透明的;但结果,一模一样。

在论文展示的一个例子中,一道数学应用题,标准思维链模型需要走完 8 个自然语言步骤才能得出答案;而 Abstract-CoT 版本,只用了 14 个抽象符号,便得出了完全相同的结论。这两个过程都正确,但后者消耗的推理 token 数量,不足前者的十分之一。
两个挑战:冷启动与“学会一门新语言”
两个挑战:冷启动与“学会一门新语言”
这个想法听起来简单,但实现起来面临两个根本性的难题。
第一个难题是
冷启动问题
第二个难题是:
如何让模型学会用这些符号有效地思考,而不只是随机堆砌?
IBM 的研究团队设计了一套两阶段训练方案来应对这两个问题。
第一阶段:策略迭代热启动(Policy Iteration Warm-up)
这个阶段的核心机制,是一种“信息瓶颈”设计。具体来说,训练时,模型会同时看到问题、标准的自然语言推理链(由教师模型提供),以及一段抽象符号序列。但关键在于,最终答案的生成,只被允许“看到”那段抽象符号,而不能直接“看到”自然语言推理链。

这就像是:让一个学生同时拿到完整的解题过程和一段摘要笔记,但考试时只能看笔记作答。久而久之,学生学会了如何把关键信息浓缩进笔记,因为只有笔记够用,才能通过考试。
经过多轮迭代,模型逐渐学会了:如何把推理所需的关键信息,压缩进那些抽象符号里。
第二阶段:热启动强化学习(Warm-started RL)
热启动阶段结束后,研究团队引入了强化学习(GRPO 算法)来进一步优化抽象符号序列的生成策略。模型被要求:只凭借那些抽象符号(不再有任何自然语言推理链辅助),就直接生成高质量的答案。一个生成式奖励模型负责对输出质量打分,反馈信号驱动模型不断改进它的“符号语言”。

实验结果:省了多少,代价是什么
实验结果:省了多少,代价是什么
论文在三个主要基准测试上验证了 Abstract-CoT 的效果:数学推理(MATH-500)、通用指令跟随(AlpacaEval)、以及多跳问答(HotpotQA)。
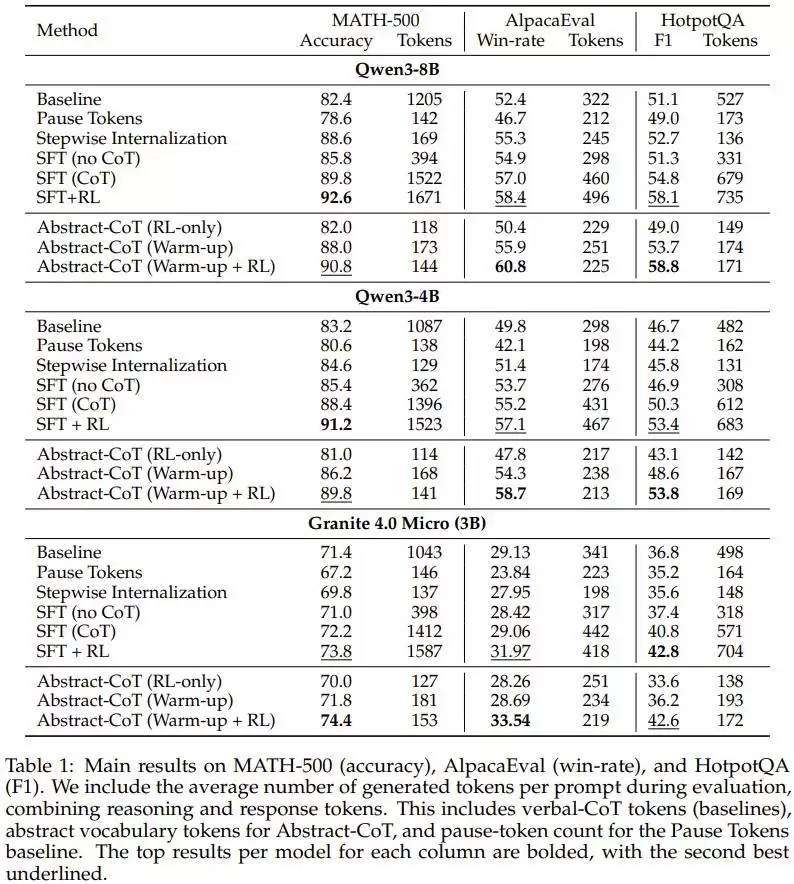
最核心的数据是这两个:
在 MATH-500 数学推理测试中,以 Qwen3-8B 为基础模型,标准的思维链 + 强化学习方法(SFT+RL)平均每道题生成 1671 个 token,准确率为 92.6%。Abstract-CoT(Warm-up + RL)仅生成
144 个 token
11.6 倍
在 AlpacaEval 通用指令测试中,Abstract-CoT 不仅 token 数量从 496 压缩到 225(约 2.2 倍),
胜率反而从 58.4% 提升到了 60.8%
更难的测试也显示了类似趋势。GPQA-Diamond(研究生级别问答)和 AIME'25(数学竞赛题)的结果表明,即便是高难度推理任务,Abstract-CoT 也能实现 2.7 倍到 7.9 倍的 token 压缩,同时性能几乎与全量思维链持平。
有一个细节值得关注:单独使用“冷启动 RL”(不经过热启动阶段,直接用强化学习训练抽象符号)的效果非常差,在多数设置下甚至不如基线模型。这说明,热启动阶段是不可或缺的——模型必须先学会这套“语言”的基本语义,才能在强化学习阶段进一步优化。
意外发现:抽象符号自发形成了“语言规律”
意外发现:抽象符号自发形成了“语言规律”
在实验分析中,研究团队发现了一个他们自己也没有预料到的现象。
经过强化学习训练后,64 个抽象符号的使用频率,
自发地形成了一种幂律分布
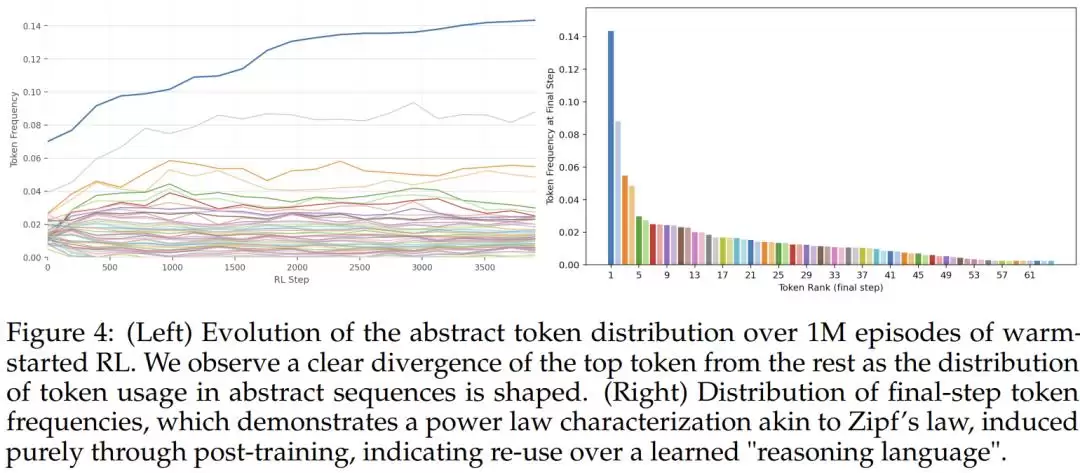
具体而言,一个叫做
这意味着什么?研究者认为,这是模型自发学习出了某种“概念复用”机制。频繁出现的符号,可能对应着跨任务普遍需要的推理步骤(比如“初始化变量”或“验证边界条件”);稀有符号,则可能对应着特定领域的罕见推理模式。
当然,目前还没有办法直接“解读”这些符号的具体语义。这套语言,对人类来说仍然是不透明的。
局限与展望
局限与展望
Abstract-CoT 目前仍有明显的局限性。最直接的一点是:这套抽象推理过程对人类完全不可解读,这意味着在需要可审计性的场景(比如医疗、法律、金融决策辅助)中,它的适用性会受到限制。
此外,这套方法依赖现有的自然语言思维链数据来完成热启动训练。这意味着,Abstract-CoT 目前仍然是“寄生”在语言推理之上的——没有语言推理的先验知识,纯抽象符号的冷启动训练几乎无法奏效。这在某种程度上说明,AI 在“学会不说话”之前,首先必须“学会说话”。
研究团队也在论文中提出了若干未来方向,包括:动态调整抽象符号序列长度(根据问题难度分配不同长度的“思考预算”)、以及构建分层符号结构(让部分符号代表可复用的推理子程序)。
最值得关注的,或许是它为“
AI 推理监控
AI 正在学着“少说废话”
AI 正在学着“少说废话”
过去两年,AI 推理能力的提升,很大程度上是靠“让模型说更多话”实现的——更长的思考链、更多的中间步骤、更详尽的自我验证。这条路走到 2026 年,正在遭遇越来越明显的成本瓶颈。
IBM Research 这篇论文提出的问题,其实是在挑战一个基本假设:
AI 一定要用人类的语言来思考吗?
他们的实验结果表明,答案可能是否定的。一套由 64 个无意义符号组成的“哑语”,在数学推理、通用问答、多跳检索等多个任务上,都能以十分之一的 token 成本,复现出接近自然语言推理链的性能。
这不是碘伏性的革命,也并非没有代价。但它至少说明一点:在 AI 推理的效率之路上,或许还有一条我们此前没有认真探索过的方向:让模型学会“闭嘴思考”。




