
DeepSeek陈德里AI论文第二弹:DeliAutoResearch SKILL又进化了
DeepSeek研究员陈德里(Deli Chen)与AI合作的第二篇论文,正式上线了。
这篇论文的主题,聚焦于
持续学习(continual learning)与自我迭代(self-iteration)


论文地址:https://victorchen96.github.io/continual_learning_survey.pdf
由于arXiv不允许将AI列为作者,陈德里这次只能把实际承担了论文99%工作量的DeepSeek-V4-Pro(负责文字)和GPT-Image-2(负责图像),从作者栏移至脚注说明。
论文的核心判断很明确:未来的AI系统不会长期停留在一组冻结参数的形态,而会逐渐演变为能够持续学习、自我更新、自我迭代的系统。背后的逻辑也很直接——上下文管理和文档化记忆,确实可以在一定程度上帮助模型维持注意力、保留任务经验。但注意力窗口终究会被填满,到了那个时候,就需要把知识和经验参数化,以降低认知负担。
值得一提的是,这不只是一次论文主题上的延伸,也是陈德里搭建的自主科研智能体框架
DeliAutoResearch SKILL
据陈德里介绍,这一轮模拟同行评审分数达到了
8分
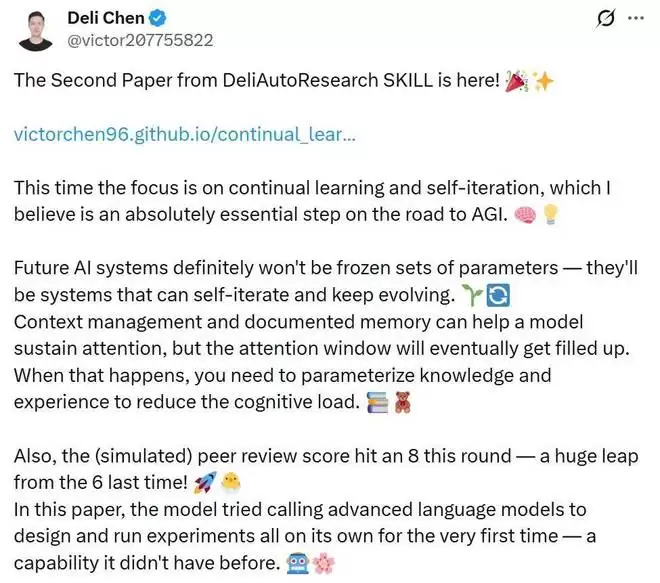
更能体现系统变化的,是论文中披露的生产数据对比。陈德里在第二张图中对比了两篇论文的生成过程:从第一篇到第二篇,随着SKILL本身不断迭代,交互轮数大幅下降,而总token消耗显著上升。这反而是一个非常好的信号——它说明SKILL正在向更高自主性转变。
换句话说,人工介入变少了,系统自己想和做的部分变多了。对一个自动科研工作流来说,这恰恰是走向更高自主性的信号。
陈德里表示,非常期待在不久的将来,DeliAutoResearch SKILL能够真正产出大师级的学术写作。不过,他也坦言,在阅读论文的一些关键部分后,仍能看到不少提升空间。如果完全由自己亲自撰写,论文质量或许会更高,但产出速度也会大幅下降。由于当前的核心目标并不是打磨单篇论文,而是持续迭代DeliAutoResearch SKILL本身,因此他选择保留这篇论文中略显粗糙的部分,将其作为系统继续进化的反馈样本。

来看一看,这篇论文讲了什么。
为什么要统一持续学习和自我改进?
论文提到,在传统研究中,持续学习和自我改进往往被当作两个不同研究方向,但它们面对的是同一个底层问题:模型如何在接收新信息或新目标之后更新自己,同时不破坏已经掌握的能力?
持续学习关注的是模型如何顺序适应新的任务或数据;自我改进关注的是模型如何自主增强能力。但两者的技术难点高度相似:都要在分布变化下稳定优化,都要保留已有表征,都要处理探索与利用之间的权衡,也都要在没有固定测试集的情况下评估进步。
因此,作者认为,下一代LLM训练管线必然会把外部数据流和模型自生成训练信号结合起来,形成紧密耦合的反馈循环。也就意味着,统一研究这两个方向不是方便之举,而是必要之举。
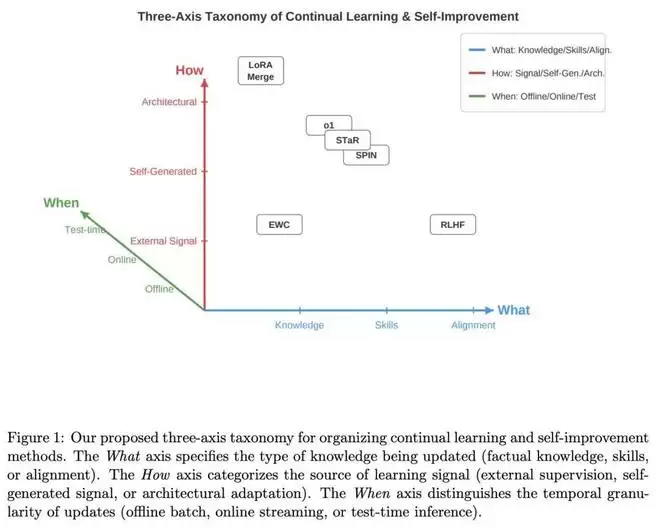
核心贡献一:提出了一个三轴统一分类框架
这篇论文最主要的贡献之一,是提出了首个同时覆盖大语言模型持续学习与自我改进的分类框架,并将其组织在三个相互正交的维度上:
- :即被更新的是知识、技能、对齐能力还是推理能力;
更新什么
- :即采用哪一类方法;
如何更新
- :即更新发生在离线阶段、周期性阶段、在线阶段,还是由特定事件触发。
何时更新
这个三轴框架如下图所示,能够对任何部署后的学习系统进行精确刻画,并揭示不同方法之间此前未被充分认识到的联系。
核心贡献二:对五大方法类别进行了系统分析
论文系统分析了100多篇论文,并将其归纳为五类方法:基于正则化的持续学习、回放与经验管理、参数高效与模块化方法、自我改进与自博弈,以及在线自适应方法。对于每一类方法,都形式化描述了其核心机制,分析了理论性质,并比较了代表性方法。
核心贡献三:形式化刻画了自我改进的收敛条件
论文对迭代式自我改进在什么条件下能够保证收敛而不是发散,进行了形式化分析,并将来自自博弈、迭代蒸馏和Constitutional AI等研究方向中分散的理论结果,统一到同一个框架之下。
论文认为,自我改进代表了一种范式转变:模型能力提升正在从依赖人类监督,转向由模型自主驱动。所提及的方法覆盖了一个很宽的范围:从训练阶段的自博弈,通过多轮迭代修改模型权重;到推理阶段的推理增强,提升每一次单独预测的质量;再到理论分析,划定自我改进究竟能够达到什么边界……
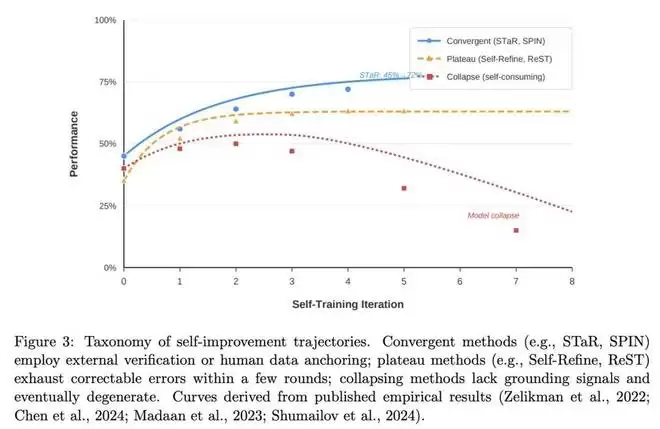
这些方法的共同点在于,它们都需要某种
grounding signal
如下图所示,自我改进的轨迹并不取决于生成机制有多复杂,而取决于评估信号的质量,以及它相对于模型自身的独立性。
核心贡献四:提出六个开放挑战
在论文最后,作者指出了生成式模型持续学习走向成熟过程中,亟待解决的六个关键问题,并基于系统分析所揭示的研究空白,为每个问题提出了未来研究方向。
大模型规模能否解决灾难性遗忘?
自我改进的理论极限。
多模态持续学习。
安全的持续对齐。
部署时“实时学习”。
与Agent框架结合。
论文认为,未来需要层级记忆架构,让Agent同时拥有短期情节记忆和长期参数知识,也需要多智能体持续学习机制,让多个Agent共享并整合经验。
最终,论文的核心判断是:
持续学习和自我改进正在走向融合。
简言之就是,不只是训练得更大,而是能不能在不遗忘、不失控的前提下,持续学习、持续对齐、持续自我进化……




