
Hy-Memory - 腾讯混元推出的 Agent 记忆插件
来源:互联网
时间:2026-05-29 20:14:57
Hy-Memory是什么
咱们先聊一个让所有Agent开发者都头疼的问题:记忆。对话一长,Agent就“失忆”,聊完即忘,更别提跨Session的长期协作。腾讯混元这次拿出的Hy-Memory,正是冲着这个痛点来的。它不是简单加个记忆库,而是用一套6层记忆框架,搭配 System1/System2 双系统,再加上演化链三层架构,试图让Agent真正做到“记得住、记得对、记得轻、还更懂你”。效果如何?在LongMemEval和PersonaMem两大权威评测中,它都拿下了同类框架的第一名。更直观的数据是:记忆数量降低了70%以上,信息密度提升了45%,写入速度更是达到了同类产品的8倍。这组数字,足以说明其设计思路的独特性和有效性。
Hy-Memory的主要功能
- :把记忆拆成原始痕迹、原子事实、身份画像、会话摘要、心智模型、前瞻意图六个层次,每一层都有自己的职责和检索权重,互不干扰。
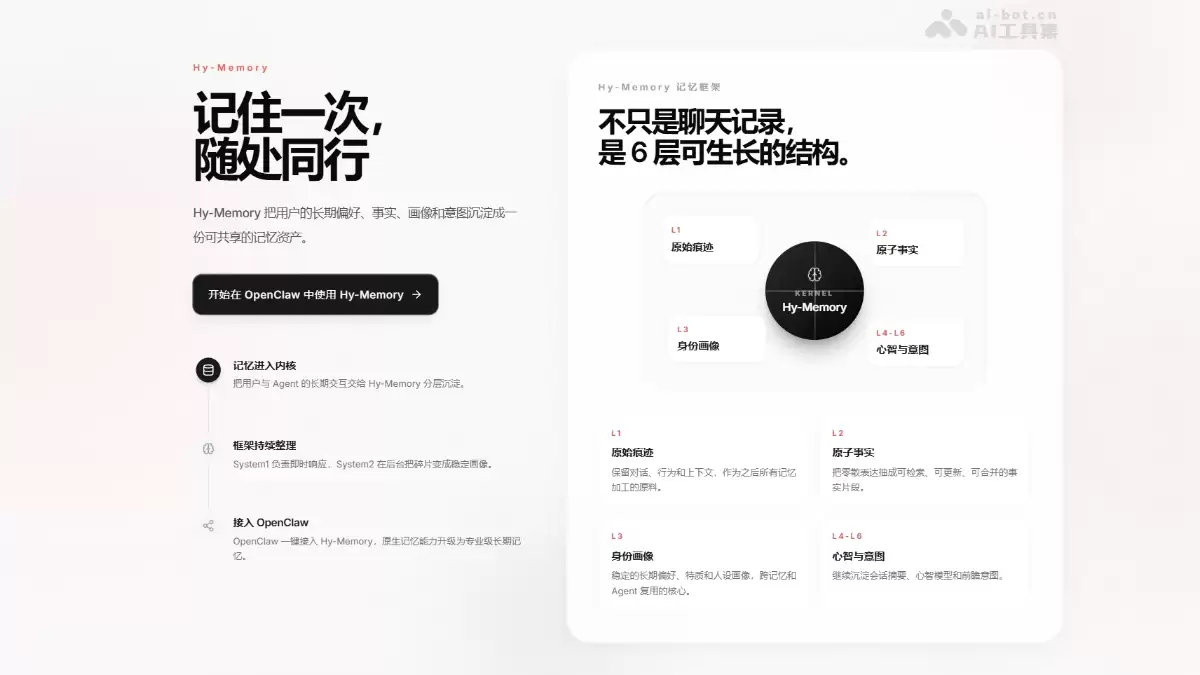
六层记忆框架
- :System1 负责毫秒级实时处理L1到L4的记忆写入,System2 则在后台异步沉淀L5和L6的高阶认知,分工明确。
System1/System2 双系统
- :通过supersedes指针把记忆串成一条因果链,只要命中链上的任意节点,就能自动展开完整的态度演变过程,不再是孤立的信息点。
演化链机制
- :同类事实会自动归并,冲突的偏好也会自动刷新,避免了新旧记忆并存形成“噪声库”的尴尬。
记忆合并去重
- :昨天关闭的对话,今天能无缝接上,Agent能保持长期任务上下文的连贯性。
跨Session连续记忆
Hy-Memory的技术原理
- :L1原始对话、L2原子事实、L3身份画像、L4会话摘要、L5心智模型、L6前瞻意图,每层采用不同的加工策略,各司其职。
分层存储架构
- :用户发送消息的那一刻,实时完成原始痕迹写入、事实抽取、画像更新、会话摘要压缩,整个过程毫秒级闭环,不拖慢对话响应。
System1快路径
- :后台异步运行,从行为中抽象出心智模型、预测前瞻意图,耗时从秒到分钟级别,但不影响主交互。
System2慢路径
- :新记忆写入时,通过supersedes指针指向旧记忆,形成双向可遍历的因果链,让记忆有了时间维度和逻辑关系。
演化链指针结构
- :在System1中设置注意力判断,决定哪些信息值得进一步加工写入深层记忆,避免无关信息浪费存储空间。
注意力闸门机制
如何使用Hy-Memory
- :通过OpenClaw一键接入Hy-Memory,原生记忆能力即可升级为专业级长期记忆,门槛很低。
接入方式
- :只做写入和检索,完全不消耗LLM成本,接入速度最快。适合那些“先让Agent记得住,理解能力后面再说”的场景。
Lite模式
- :加入MemAgent同步进行抽取、摘要、反思,但没有后台worker。适合希望记忆能自己整理、但暂时不需要深度认知的业务。
Pro模式
- :完整运行System1+System2内核,异步慢路径持续回放归纳。这是力求“越用越像用户”的终极模式,需要更长时间沉淀。
Ultra模式
Hy-Memory的核心优势
- :单条信息密度达到130.5 token/条,是mem0的2.5倍,比Graphiti也高出1.5倍。
记忆密度更高
- :平均每个用户只需82.3条记忆,仅为mem0和Graphiti的约四分之一,有效解决了记忆碎片化问题。
记忆数量更少
- :12.3 s/k tokens,速度是Graphiti的八分之一,完全不会拖慢主链路的响应速度。
写入速度更快
- :LongMemEval得分85.20%,PersonaMem得分76.91%,两项均位列同类框架第一。
评测成绩领先
- :演化链保留了完整的态度演变路径,避免了“覆盖派”只记最新、或“堆积派”召回不全的两难困境。
因果演化完整
Hy-Memory的同类竞品对比
Hy-Memory的应用场景
- :跨数周跟进复杂项目,Agent能记住每一次决策的原因和排除过的方案。
长期项目协作
- :沉淀用户的工作习惯和决策心智模型,越用越了解用户的偏好。
个人知识管理
- :记录用户对训练方式的态度演变,避免推荐用户已经踩过坑的方案。
健身/健康规划
- :追踪创作者对发行渠道的态度变化,给出符合其价值观的建议。
创作辅助
- :记住学生的学习进度、知识薄弱点和理解方式,提供真正连续性的指导。
学习辅导




