
Curosr:请大家再爱我一次
曾几何时,AI编程领域最被看好的故事,是“原生模型+原生应用”的闭环优势。逻辑似乎无懈可击:像Claude Code这样背靠Anthropic的产品,能最早用上最强的Claude模型,从模型能力、上下文窗口到工具调用,都可以进行端到端的深度优化。训练数据、推理参数、工具协议,每一层都能为编程场景量身定制,无需迁就任何第三方API的限制。
相比之下,Cursor这类产品,无论体验做得多么出色,也容易被贴上“套壳”的标签。一个普遍的担忧是:一旦原生团队将模型优势完全释放,或者为了抢占市场而调整第三方API的价格策略,应用层的产品很可能面临生存危机。
然而,市场正在给出不同的答案。这个看似坚固的判断,正在悄然失效。
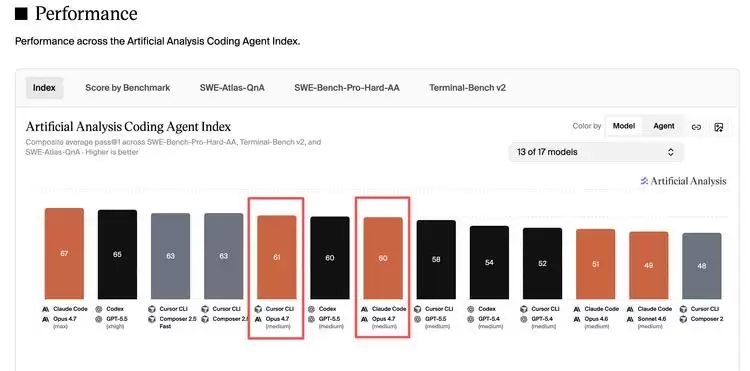
近期Artificial Analysis更新的榜单显示,Cursor CLI与Claude Code同样使用Claude Opus 4.7(medium)模型,综合得分分别为61和60。分数本身的高低并非关键,重要的是这个结果揭示了一个趋势:所谓“原生”带来的性能加成,正在被应用层扎实的工程积累所追赶甚至抵消。
同款模型,接近的结果。Cursor用“套壳”的方式,做出了不输原生的实际体验。这,恰恰为它打开了反击的窗口。
把模型变成可替换的零件
把模型变成可替换的零件
Cursor应对“套壳”质疑的策略,并非去证明自己的模型更强,而是从根本上让模型变得不那么“致命”。它的核心思路是:在模型外围,构建一套足够高效、独立于单一模型的工作系统。
这套系统关注的是上下文管理、代码库理解、IDE与CLI的深度协同……这些要素不依附于任何特定模型,却直接决定了智能体(Agent)能否真正理解任务、可靠执行。今年4月发布的Cursor 3,将“Agents Window”提到了核心位置。开发者可以在同一界面内调度多个Agent,让它们分别运行在本地、工作区、云端、远程SSH乃至不同的代码仓库中。
随后的更新沿着这个方向层层推进。Cursor SDK将Agent运行时环境开放给开发者,方便企业将Agent接入内部工具链;Cloud Agents增加了多仓库支持和审计日志功能,直击企业用户在安全与合规上的痛点。
更有意思的是,Cursor正试图将任务入口从传统的IDE中解放出来。未来的开发任务,起点可能是一个模糊的想法、一条简短的对话消息。Cursor要做的,是让这些分散的入口自动汇入其Agent系统,最终以代码差异(diff)、测试结果或合并请求(PR)的形式,呈现在开发者面前。
从一款AI编程工具,演进为一个以Agent为核心驱动力的工程系统,这才是Cursor本轮更新的真正野心。当这套系统稳固建立,模型本身便成了一个可替换的标准化零件。
Claude表现强势?那就接入Claude。GPT效果更好?切换至GPT。开源模型变得实用?同样可以纳入统一的工作流。更何况,随着顶级模型的能力天花板逐渐趋近,在许多实际开发任务中,使用Claude Opus 4.7与使用GPT 5.5的体验差距正在弥合。
当“谁家的模型更强”不再是决定性因素,用户的选择逻辑就发生了根本转变。他们不再被绑定于某一家模型供应商,而是更看重谁能将不同模型的能力调度得更高效、更稳定。过去被轻视的、所谓“套壳”的那一层应用,正在成为用户决策的核心考量。
不体面,但有效
不体面,但有效
解决了“被替代”的生存危机,Cursor还面临着另一个更基础的困境:如何赚钱。它的商业模式天生带着一个尴尬的螺旋:工具越好用,用户调用越频繁,背后所依赖的第三方模型API成本就越高昂。
而编程智能体(Coding Agent)恰恰是典型的高Token消耗、高工具调用、高重试率的场景。与许多依赖第三方模型的AI编程创业公司一样,Cursor直到不久前仍处于负毛利状态。根据The Information的披露,截至2026年1月的季度,Cursor的毛利率约为-23%,此后情况才勉强转正。

转折点来自于Cursor自研的Composer系列模型。它的思路非常务实:并非从零开始打造一个全能的基础模型,而是用自有模型接管大量常规的、对推理能力要求不高的编程任务,从而大幅减少对昂贵上游API的依赖。
那些不需要前沿推理能力的场景——比如常规的代码补全、格式化、简单重构——交由Composer处理;而将宝贵的API调用配额,留给真正需要顶尖模型出马的复杂问题。这套策略效果立竿见影,Cursor的大型企业账户已实现正毛利,个人开发者账户虽仍有亏损,但整体成本结构已显著改善。
最新的Composer 2.5模型,正是这一逻辑的延续。Cursor坦承其基于Kimi K2.5底座,针对长周期编程任务进行了专项训练,所使用的合成数据量达到了上一代的25倍。

选择开源底座而非完全自研,专注于专项微调而非追求全能,每一步都在竭力压低成本。最终,Cursor形成了一套可接受的成本结构:最复杂的需求交给Claude、GPT这类前沿模型;最频繁、最标准化的中间地带,则由自家的Composer模型覆盖。
更重要的是,这套机制与Cursor自身的系统形成了正向循环。用户需求越具体,专用模型的训练和优化空间就越大,对上游通用模型的依赖也就随之降低。
重新被评价的资格
重新被评价的资格
某种意义上,Cursor正在做的,是以一种不太“体面”的方式,完成一件颇具尊严的事。它没有执着于在“我的模型比你强”的战场上正面硬刚,也没有试图在基础研究层面与Anthropic、OpenAI展开竞争。它清醒地接受了自己在生态中的位置,然后在这个位置上,将应用层能做的事情做到了极致。
当前,AI基础模型领域正从“赢家通吃”走向“多极并立”。当没有哪一家模型能在所有场景下形成绝对碾压时,应用层的工程能力——谁能把有限的模型能力用得更充分、更稳定、更经济——就成了决定用户去留的关键变量。
当然,这场竞争远未结束。Claude Code绝不会坐以待毙,模型能力的上限仍在不断提升,原生团队在工具调用和上下文优化上的投入也在加速。Cursor打开的这扇窗口能持续多久,取决于两件事:其应用层的工程积累能否持续保持领先,以及它能否在成本结构实现完全健康之前,等到市场格局真正稳定下来。
但至少现在,它凭借扎实的进展,重新赢回了市场的审视与信任。在瞬息万变的AI行业里,能够活到被市场重新评价的那一天,本身就已经是一种难得的胜利。




