
双榜SOTA!微软ACL2026新作重新定义AI长记忆
随着大语言模型在各类应用中加速落地,一个核心技术瓶颈日益凸显——AI始终缺乏真正的长期记忆能力。当前主流的
RAG(检索增强生成)方案
但“语义相似”并不等于“真正相关”
为应对上述挑战,微软研究团队提出了全新的
AI记忆框架Mnemis
“快速检索”
“审慎推理”
被ACL2026主会议接收
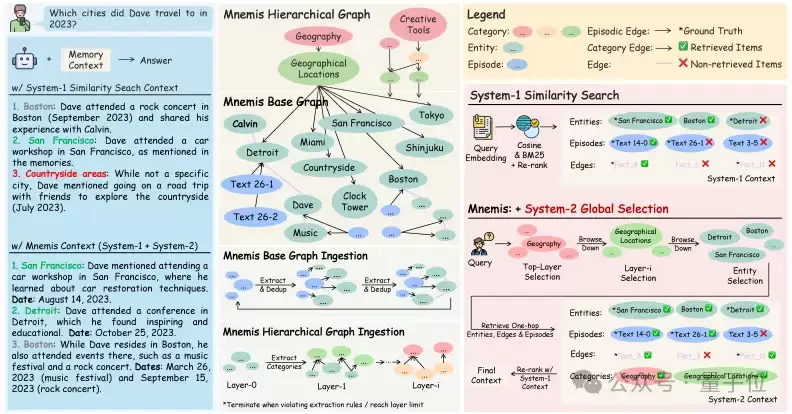
△图 1:Mnemis框架总览——层级图索引+双路径检索
RAG的“近视眼”困境
设想这样一个场景:用户问“Da ve在2023年去过哪些城市?”,正确答案是San Francisco和Detroit。传统RAG将查询转为向量,在历史对话中寻找语义最相似的片段。结果它找到了Boston和San Francisco,却完全遗漏了Detroit——因为“attended a conference in Detroit”被埋藏在一条长消息中,与“去过哪些城市”的语义相似度不够高。同时,RAG也无法判断Boston是居住城市而非旅行目的地。
这暴露了传统RAG的三个根本局限:
- ——每条记忆独立与查询比较,忽略记忆之间的关系;
孤立评分
- ——向量相似度偏爱字面匹配,对间接相关的信息天然不敏感;
语义偏见
- ——系统不了解对话历史中存在哪些话题及其相互关系。
无法推理
打个比方,RAG就像根据书名关键词找书,而有经验的图书馆员会先查阅分类目录,从结构上系统性地定位所有相关书籍。
Mnemis的核心设计:建构式索引+双系统检索
Mnemis的名字源自希腊神话中的记忆女神,其设计分为
索引
检索
在
索引阶段
保存主义
建构主义
Mnemis正是建构主义的计算实现:
它将碎片化对话组织成自适应的层级图,而非扁平的向量库
具体来说,第一层是
Base Graph(知识图谱)
第二层是
Hierarchical Graph(层级图)
层级图的构建遵循三个核心原则:
最小概念抽象(MCA)
多对多映射(M2M)
压缩效率约束(CEC)
在
检索阶段
System-2(慢思考)
最终,System-1确保语义直接匹配的记忆不遗漏,System-2确保结构相关但语义距离较远的记忆被覆盖,两者
融合互补
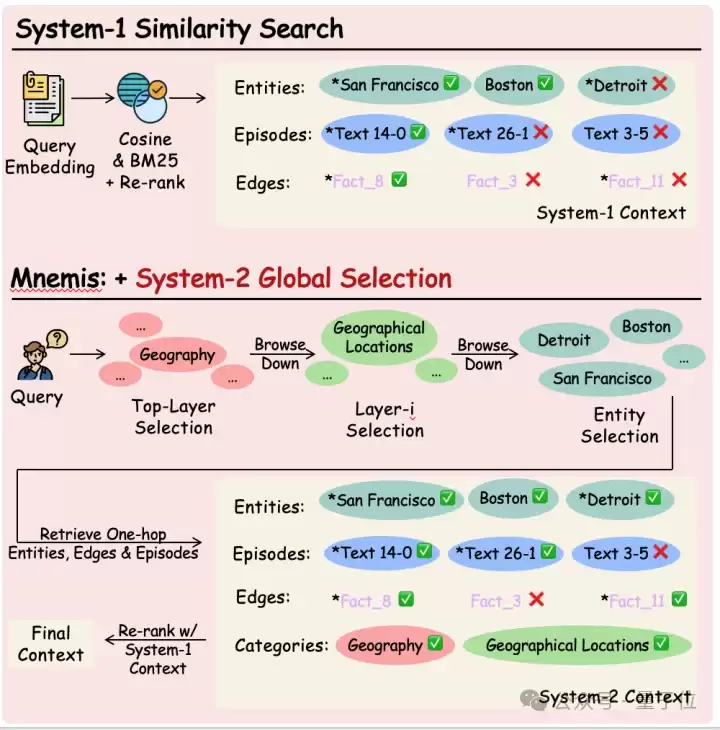
△图 2:Mnemis的双路径检索范式
效果验证:双基准SOTA
Mnemis在两个主流长期记忆基准上进行了全面评估。在
LoCoMo基准
LongMemEval-S基准
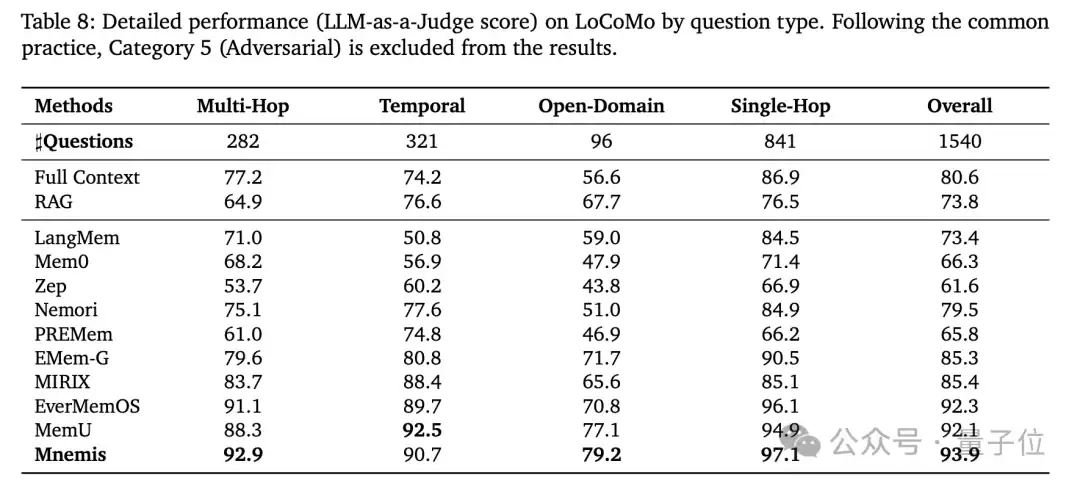
△图3:LoCoMo基准实验结果
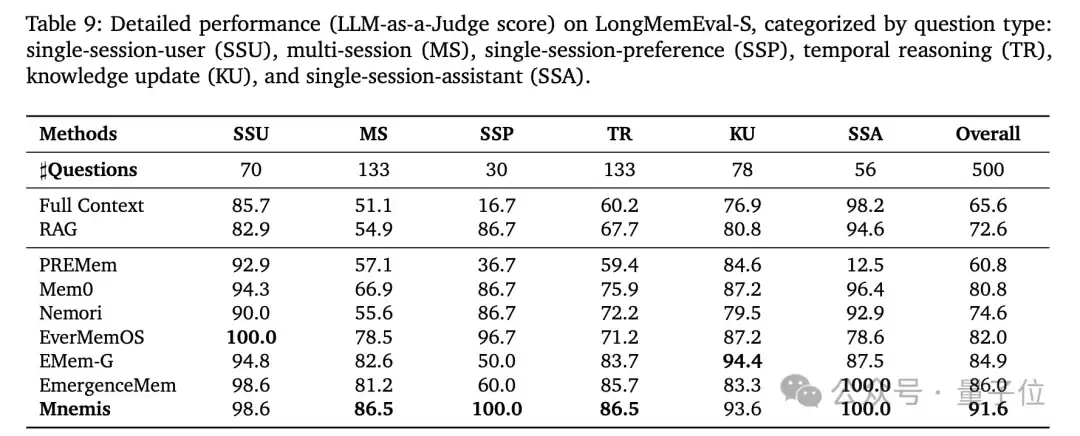
△图 4:LongMemEval-S基准实验结果
案例分析
回到开头的案例。面对“Da ve在2023年去过哪些城市”这一查询,System-1通过语义匹配找到了Boston和San Francisco,但遗漏了Detroit。System-2则从层级图顶部出发,依次定位到Geography→Geographical Locations,触发Shortcut直接获取所有城市实体,成功检索到Detroit。两条路径融合后,模型进一步推理判断Boston为居住城市而非旅行目的地,最终给出完整正确的答案。
△图5:案例分析——System-1与System-2的互补
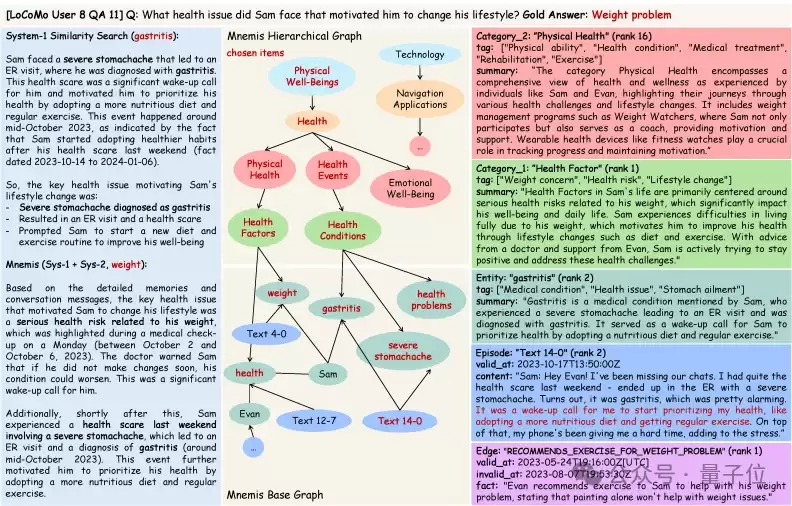
另一个典型案例是“Sam遇到了什么健康问题促使他改变生活方式”。System-1被“health issue”等关键词吸引,检索到胃炎这一急性事件;而System-2通过层级结构定位到Physical Well-Being→Health→Health Factors,聚合多条记忆后发现,真正驱动Sam长期改变生活方式的核心因素是体重问题而非单次胃炎事件。这体现了System-2在抽象归因和长期动机分析上的独特价值。
思考与展望
Mnemis揭示了一个重要洞察:
记忆系统的质量,很大程度上取决于“存储时做了什么”,而不仅仅是“检索时怎么找”。
传统RAG将所有智能都放在检索阶段,而索引阶段几乎是无加工的分块向量化。Mnemis的设计理念是在索引阶段就进行深度语义建构,使检索阶段能同时利用快速匹配和结构遍历——这恰好对应人类记忆的两个关键特征:
存储时的建构性和提取时的双模式。
论文链接:https://arxiv.org/abs/2602.15313
GitHub:https://github.com/microsoft/Mnemis




