
音频创作迎来新突破!Stability_AI_发布_Stable_Audio_3:长音频秒级生成
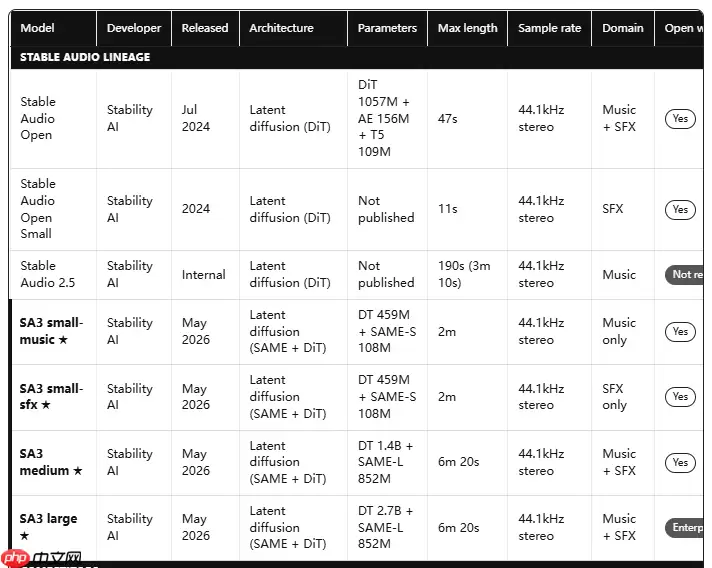
人工智能领域最近又迎来一个重磅发布。知名公司Stability AI正式推出了新一代音频大模型——Stable Audio 3,并同步开源了部分模型参数。这款基于潜扩散架构的模型,专为音频生成与精细化编辑而生,不仅支持高保真立体声输出,更在推理效率上实现了关键突破。
此次发布的模型系列覆盖了从轻量级到高性能的多个版本,能够灵活适配音乐制作、影视音效设计乃至互动媒体开发等多样化的应用场景。最引人注目的是,它原生支持生成任意时长的音频,并集成了基于“内补成像”原理的智能音频编辑功能,这无疑极大地拓展了内容创作的边界与精度。
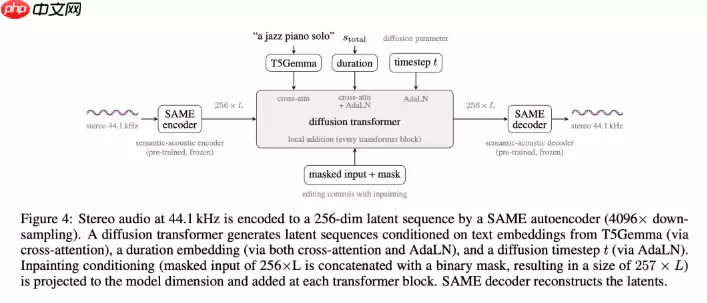
架构革新突破算力瓶颈
Stable Audio 3的成功,核心在于其创新的双模块协同设计:一个语义声学自编码器(SAME)与一个高效的扩散变换器。其中,SAME编码器实现了高达4096倍的音频信号压缩比,将原始音频序列长度大幅压缩至潜在空间。
正是得益于这种高密度的压缩机制,模型得以在主流消费级硬件上,稳定地完成长时间、高复杂度的音频合成任务。这不仅显著降低了专业级音频内容生产的硬件门槛,也让独立创作者在普通的工作环境中,产出广播级音质的作品成为可能。
毫秒级响应重塑创作流程
为了进一步提升效率,新模型采用了可变长度动态建模技术。它能根据用户指定的音频时长,实时调节计算资源的分配,从而有效规避了传统固定长度模型中常见的冗余运算问题。实测数据相当亮眼:在高端GPU环境下,生成一段20秒的高质量音频仅需约0.62秒;而合成一首长达380秒的完整乐曲,也仅仅耗时1.31秒。
与此同时,通过独创的三阶段渐进式训练范式,Stable Audio 3在推理阶段彻底摆脱了对经典“无分类器引导”技术的依赖,实现了单步前向传播即可输出结果的极速体验。目前,面向公众开放的小型与中型模型权重已正式登陆Hugging Face平台。至于功能更全面、性能更卓越的大型商用版本,则将通过授权方式提供。


