
大模型也需要睡觉,让AI打个盹,醒来更聪明
7×24小时连轴转,别说人了,AI也扛不住。
最近,卡内基梅隆大学和马里兰大学的研究人员发表了一篇有趣的论文,标题就叫《语言模型需要睡眠》。核心观点很直接:大模型在处理长上下文任务时,如果硬撑着不“休息”,性能真的会下降,就像人累傻了似的。

这项研究的灵感,恰恰来自于我们最熟悉的生物体——人脑。
我们都知道,人在睡眠时,海马体会将白天的短期记忆反复“回放”,最终巩固进大脑皮层的突触连接中,转化为长期知识。研究团队认为,这个机制完全可以借鉴到AI模型上。他们设计了一套“睡眠机制”,让大模型在上下文窗口快满的时候别硬撑了,而是“打个盹”,把最近的上下文信息反复咀嚼几遍,压缩进长期权重,然后清空缓存,醒来后轻装上阵,继续工作。

测试结果证实了这个想法的有效性。合理增加“睡眠”的迭代轮次,能显著提升模型在深度推理类任务上的表现。尤其是那些需要环环相扣、逐步推导的复杂难题,任务越复杂,模型似乎就越需要多“睡”一会儿。
这背后到底是什么原理?
大模型到底怎么了,非要睡觉
大模型到底怎么了,非要睡觉
要理解这个问题,得从Transformer架构的核心——注意力机制说起。注意力机制有个天生的短板:上下文越长,计算量呈平方级增长,存储历史信息的KV缓存也会线性膨胀。
这意味着,同样是执行推理任务,一个8K上下文窗口的模型和一个128K上下文窗口的模型,其算力成本天差地别。多出来的算力,基本都消耗在了对海量历史信息的关联计算上。
目前业界主要有两种应对思路:
第一种是“硬扛”。缓存满了就把老信息踢出去,但踢出去的信息对模型而言就等于从未发生过,这显然会损害任务的连贯性。
第二种是近年来流行的
SSM(状态空间模型)与Attention的混合架构

混合架构提供了一种折中方案:将不那么紧急的历史信息压缩进“快速权重”(Fast Weight)中,不占用宝贵的KV缓存,同时保留随时调用的能力。这确实缓解了内存压力,但研究团队发现,即便快速权重容量充足,当推理步骤变得极其冗长、逻辑链条非常复杂时,模型依然会出现性能衰退。
这说明,当下的瓶颈
可能已经不是信息存储能力不足,而是深度推理能力跟不上
关键在于,历史信息在被移出KV缓存之前,模型通常只有一次前向传播的机会来完成信息的“内化”。对于简单的信息提取,一次处理或许足够;但对于需要拆解、重组、多步推导的复杂逻辑,单次处理就显得力不从心了。
这个现象其实和人脑非常相似。你白天经历了一连串复杂事件,并不是当场就能完全消化理解的。大脑的策略是,等你晚上睡着、外部刺激暂停后,再调动资源进行深度处理。
睡眠期间,海马体会对白天的关键片段进行一遍又一遍的“回放”,通过这种反复的神经活动,将短期记忆巩固为皮层中的长期知识。这个过程必须是
离线的
模型的睡眠长什么样
模型的睡眠长什么样
研究团队正是将人脑的这一整套“睡眠-记忆巩固”逻辑,搬到了大模型上。
他们的设计方案很直观:当模型的上下文窗口即将填满时,不让它硬撑,而是主动触发“睡眠”状态。
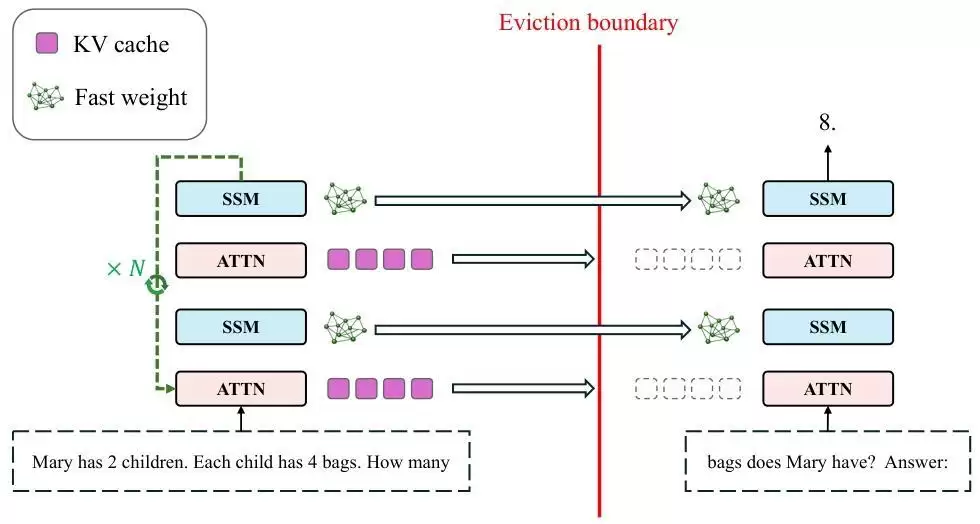
这里的“睡眠”,指的是
暂停接收新的输入token,进入纯离线状态,然后对已经积累的全部上下文,执行多轮递归式的前向传播
在这个过程中,模型依靠可学习的内部规则,反复对已有信息进行提炼、整合和关联,逐步更新SSM模块内的快速权重,从而完成信息的深度压缩与消化。等“消化”得差不多了,就清空KV缓存,带着更新后、蕴含了更多知识的权重“醒来”,继续处理后续任务。

从计算资源分配来看,
所有额外的计算开销都被集中在了“睡眠”阶段
所谓的“睡眠时长”,本质上就是信息迭代处理的轮次。轮次越多,意味着模型对上下文内容的梳理和打磨越充分。
为了验证效果,团队选择了元胞自动机演化、多跳图关系检索以及GSM-Infinite无限数学推理这三类任务进行测试。这几类任务的共同特点是,可以精确控制
推理深度
记忆负载
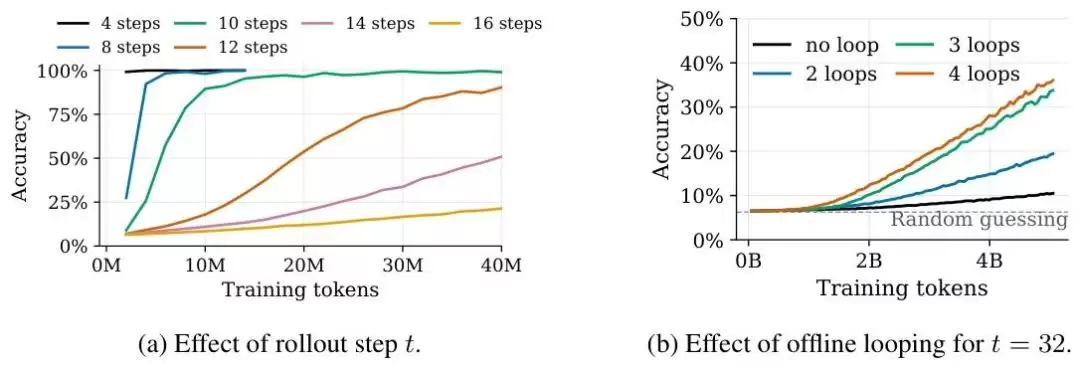
测试结果清晰地印证了假设:随着睡眠迭代轮次的增加,模型的整体性能稳步提升。更重要的是,这种性能提升主要体现在高难度的深度推理任务上。对于简单问题,模型“醒着”就能快速解决;而对于复杂难题,它确实需要“睡一觉”,经过多轮内部梳理,才能理清思路,找到答案。
看来,适当的“休息”确实是提升效率的妙招,有时候停下来,反而能更好地思考。这个发现不仅有趣,也为优化大模型的长上下文处理能力,提供了一条颇具生物启发性的新路径。
论文地址:https://arxiv.org/abs/2605.26099




