
双榜SOTA,微软ACL2026新作重新定义AI长记忆
大语言模型的应用浪潮正席卷而来,但一个核心的瓶颈也越来越清晰:AI始终缺乏真正的长期记忆。目前主流的解决方案——
检索增强生成(RAG)
“语义相似”不等于“真正相关”
为了突破这个瓶颈,微软研究团队提出了一个全新的
AI记忆框架Mnemis
“快速检索”
“审慎推理”
ACL 2026主会议接收
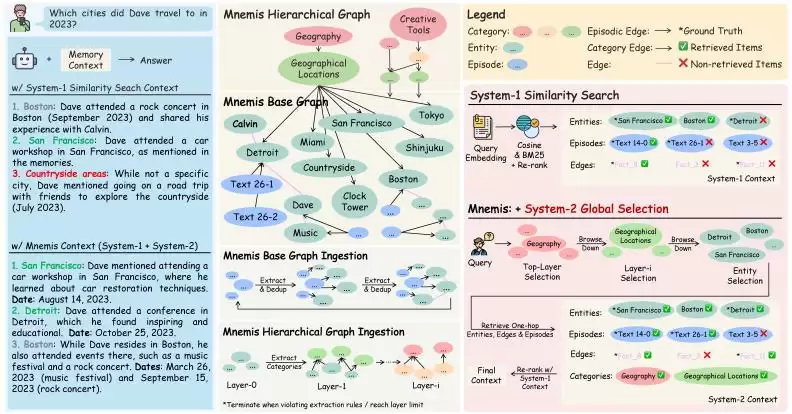
△ Mnemis框架概览
RAG的“近视眼”困境
RAG的“近视眼”困境
想象这样一个场景:用户问“Da ve在2023年去过哪些城市?”,正确答案是旧金山和底特律。传统的RAG会把问题转化为向量,然后在历史对话里寻找语义最相似的片段。结果呢?它可能找到了“波士顿”和“旧金山”,却完全漏掉了“底特律”——因为“在底特律参加了一场会议”这条信息,可能埋藏在一段很长的消息里,和“去过哪些城市”这个问题的字面语义相似度不够高。更麻烦的是,RAG也无法判断“波士顿”是Da ve的居住城市,而非旅行目的地。
这个例子暴露了传统RAG的三个根本局限:
孤立评分
语义偏见
无法推理
打个比方,RAG就像只根据书名里的关键词在图书馆里找书;而一位有经验的图书管理员,会先去查阅分类目录,从整个知识体系的结构出发,系统性地定位所有相关书籍。
Mnemis的核心设计:建构式索引+双系统检索
Mnemis的核心设计:建构式索引+双系统检索
Mnemis的名字源自希腊神话中的记忆女神,其设计清晰地分为
索引
检索
在
索引阶段
保存主义
建构主义
Mnemis正是建构主义的计算实现:
它将碎片化的对话,组织成一个自适应的层级图,而不是一个扁平的向量库
具体来说,它构建了两层结构:
第一层是
基础图谱(Base Graph)
第二层是
层级图(Hierarchical Graph)
构建这个层级图遵循三个核心原则:
最小概念抽象(MCA)
多对多映射(M2M)
压缩效率约束(CEC)
到了
检索阶段
系统一(快思考)
系统二(慢思考)
最终,系统一确保语义直接匹配的记忆不被遗漏,系统二确保那些结构相关但语义距离较远的记忆也能被覆盖,两者
融合互补
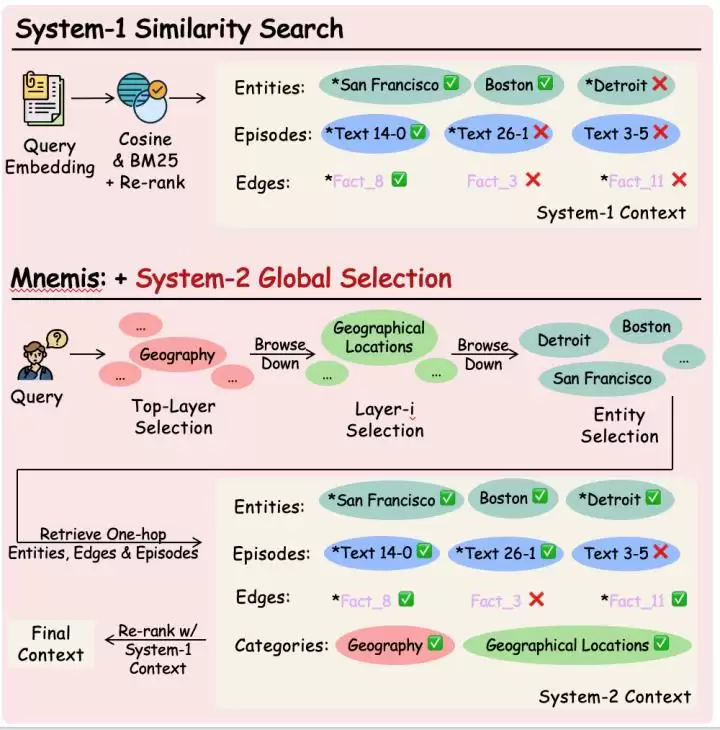
△ 双系统检索流程示意图
效果验证:双基准SOTA
效果验证:双基准SOTA
研究团队在两个主流的长期记忆基准上对Mnemis进行了全面评估。在
LoCoMo基准
LongMemEval-S基准
值得注意的是,以上优异结果仅使用了GPT-4.1-mini作为底层模型,这充分证明了Mnemis框架设计本身的有效性,而非单纯依赖大模型的强大能力。
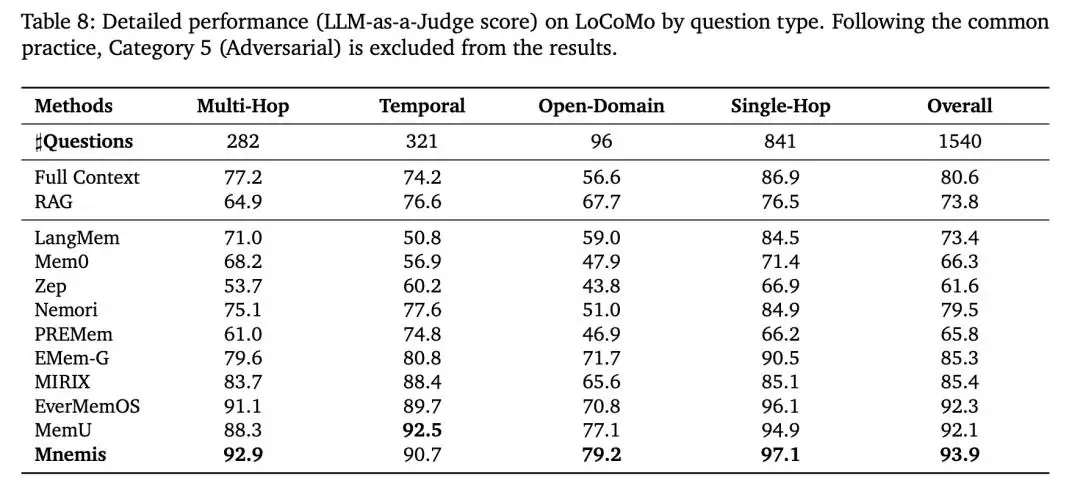
△ 在LoCoMo基准上的性能对比
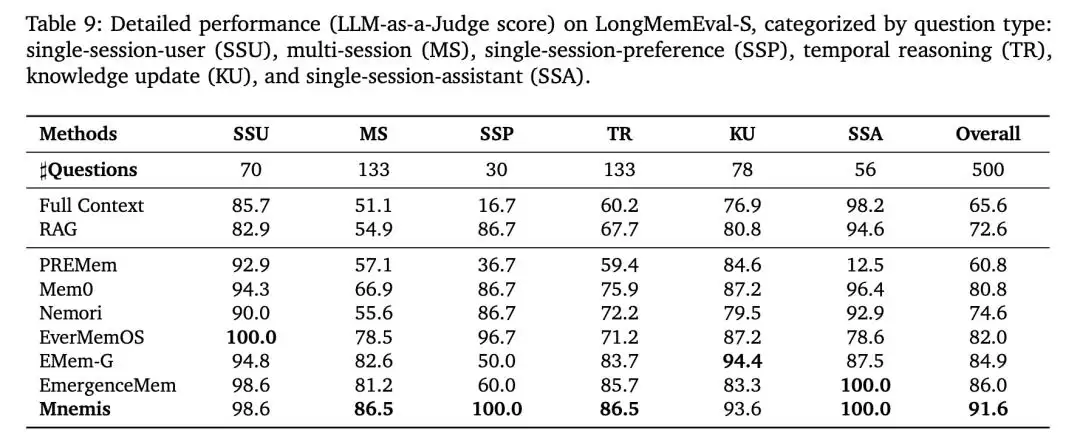
△ 在LongMemEval-S基准上的性能对比
案例分析
案例分析
让我们回到开头的案例。面对“Da ve在2023年去过哪些城市”的查询,系统一通过语义匹配找到了“波士顿”和“旧金山”,但漏掉了“底特律”。系统二则从层级图顶部出发,依次定位到“地理”→“地理位置”类别,触发“捷径”机制直接获取该类别下的所有城市实体,从而成功检索到“底特律”。两条路径的结果融合后,模型还能进一步推理,判断出“波士顿”是居住城市而非旅行目的地,最终给出完整且正确的答案。
△ 案例一检索过程解析
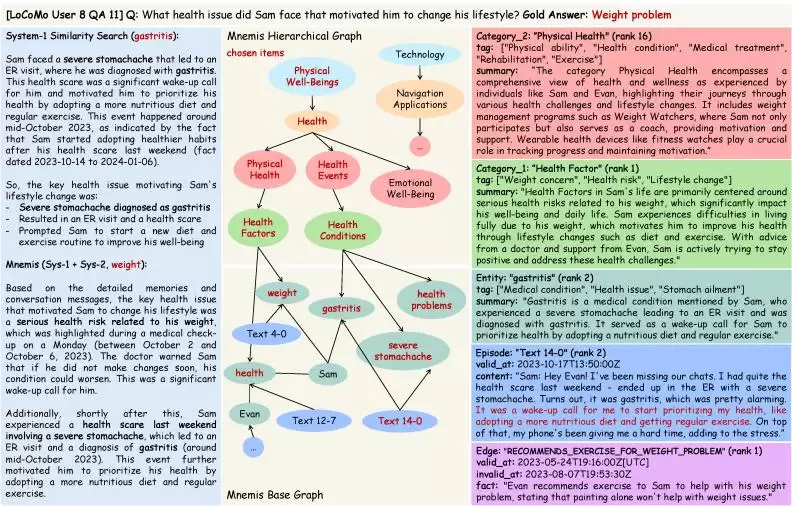
另一个典型案例是:“Sam遇到了什么健康问题促使他改变生活方式?”系统一被“健康问题”等关键词吸引,检索到了“胃炎”这一急性事件。而系统二通过层级结构,定位到“身体健康”→“健康”→“健康因素”这条路径,聚合了多条记忆后发现,真正驱动Sam长期改变生活方式的核心因素,其实是“体重问题”,而非单次的胃炎事件。这体现了系统二在抽象归因和长期动机分析上的独特价值。
思考与展望
思考与展望
Mnemis揭示了一个至关重要的洞察:
记忆系统的质量,很大程度上取决于“存储时做了什么”,而不仅仅是“检索时怎么找”。
传统RAG几乎把所有智能都押注在检索阶段,索引阶段只是简单地进行分块和向量化,近乎无加工。Mnemis的设计理念则反其道而行之:在索引阶段就进行深度的语义建构,使得检索阶段能够同时利用快速匹配和结构遍历两种模式——这恰好对应了人类记忆的两个关键特征:
存储时的建构性,和提取时的双模式。
可以说,真正有价值的AI记忆,应当是有组织的、可推理的、双模式的,并且能够持续进化。Mnemis正是朝着这个方向迈出的重要一步。




