图解强化学习 |手算GRPO
来源:互联网
时间:2026-05-27 08:02:13
在强化学习与大语言模型对齐的领域,PPO算法因其稳定性和有效性而广为人知。然而,其复杂的双网络架构(Actor-Critic)也带来了不小的计算开销和调参难度。今天,我们来深入探讨一种旨在解决这些痛点的算法——GRPO(Group Relative Policy Optimization,分组相对策略优化)。
GRPO 算法的基础认识
GRPO,全称Group Relative Policy Optimization,可以理解为PPO算法的一个“极简主义”版本。它的核心思路非常清晰:
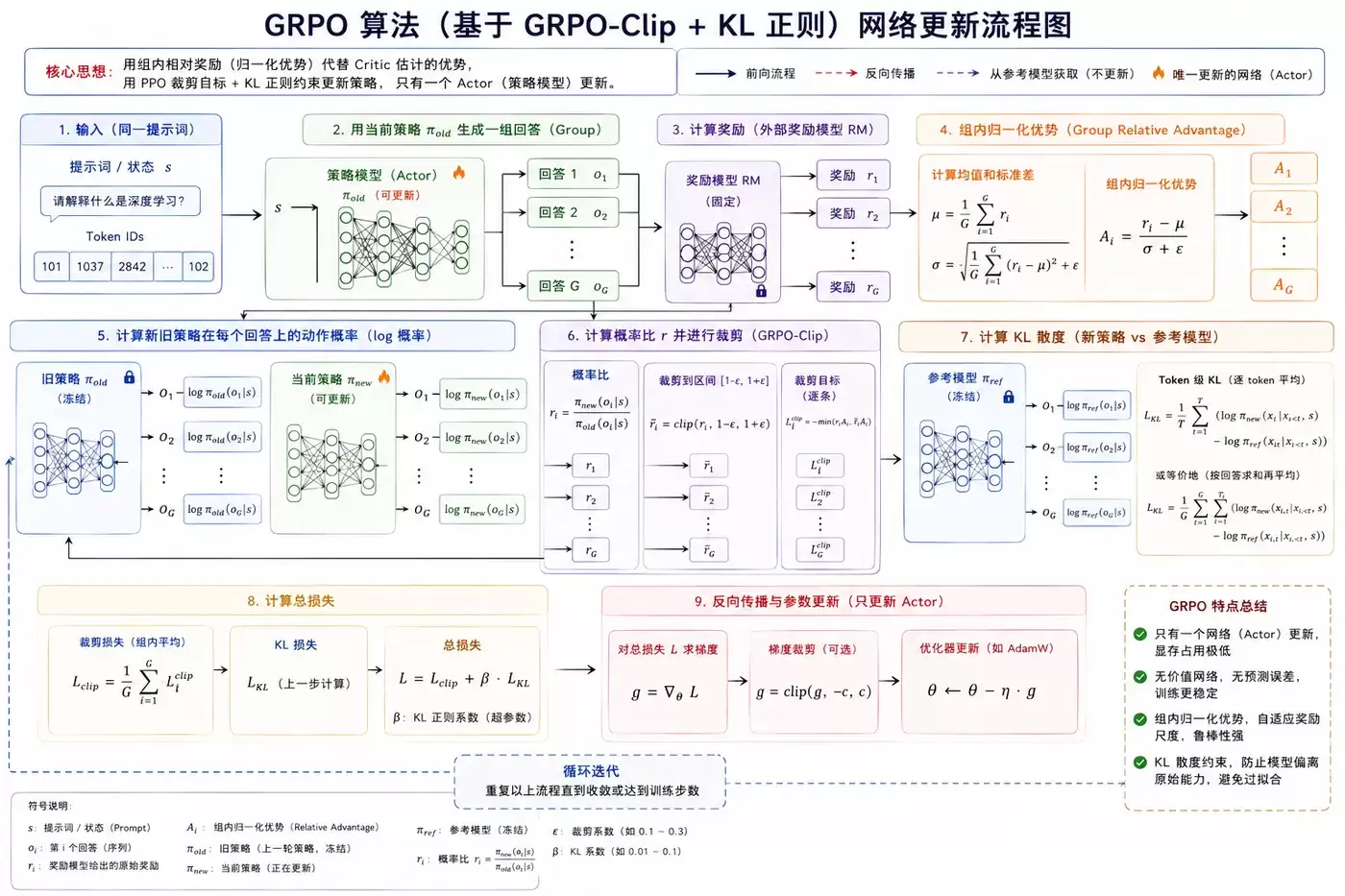
不再额外训练一个价值网络(Critic)来评估状态好坏,而是通过同一组候选回答之间的相对奖励比较,来替代PPO中优势函数的估计。
具体来说,对于同一个提示词,模型会生成多个回答,并获取各自的奖励分数。GRPO利用这些分数在组内的相对关系(比如通过归一化处理)来判断哪个回答更好,从而指导策略更新。同时,它完整保留了PPO的裁剪(Clipping)机制,以限制每次策略更新的幅度,确保训练稳定性。此外,算法还加入了KL散度正则项,
防止模型在优化过程中过度偏离原始策略,从而保住基础能力不退化。
因此,GRPO的核心目标很明确:在保持甚至提升训练稳定性和长链推理能力的同时,显著降低LLM-RLHF训练所需的显存与计算成本。
GRPO 算法的网络结构
GRPO的网络结构是其“简化”思想的直接体现。
Actor网络
唯一的主角:
输入输出:
核心作用:
这里有几点需要特别说明:
首先,GRPO的设计极其精简。它摒弃了传统的Q网络、价值网络、目标网络,甚至没有可学习的温度参数。整个架构干净利落。
其次,训练中会引入一个
参考模型
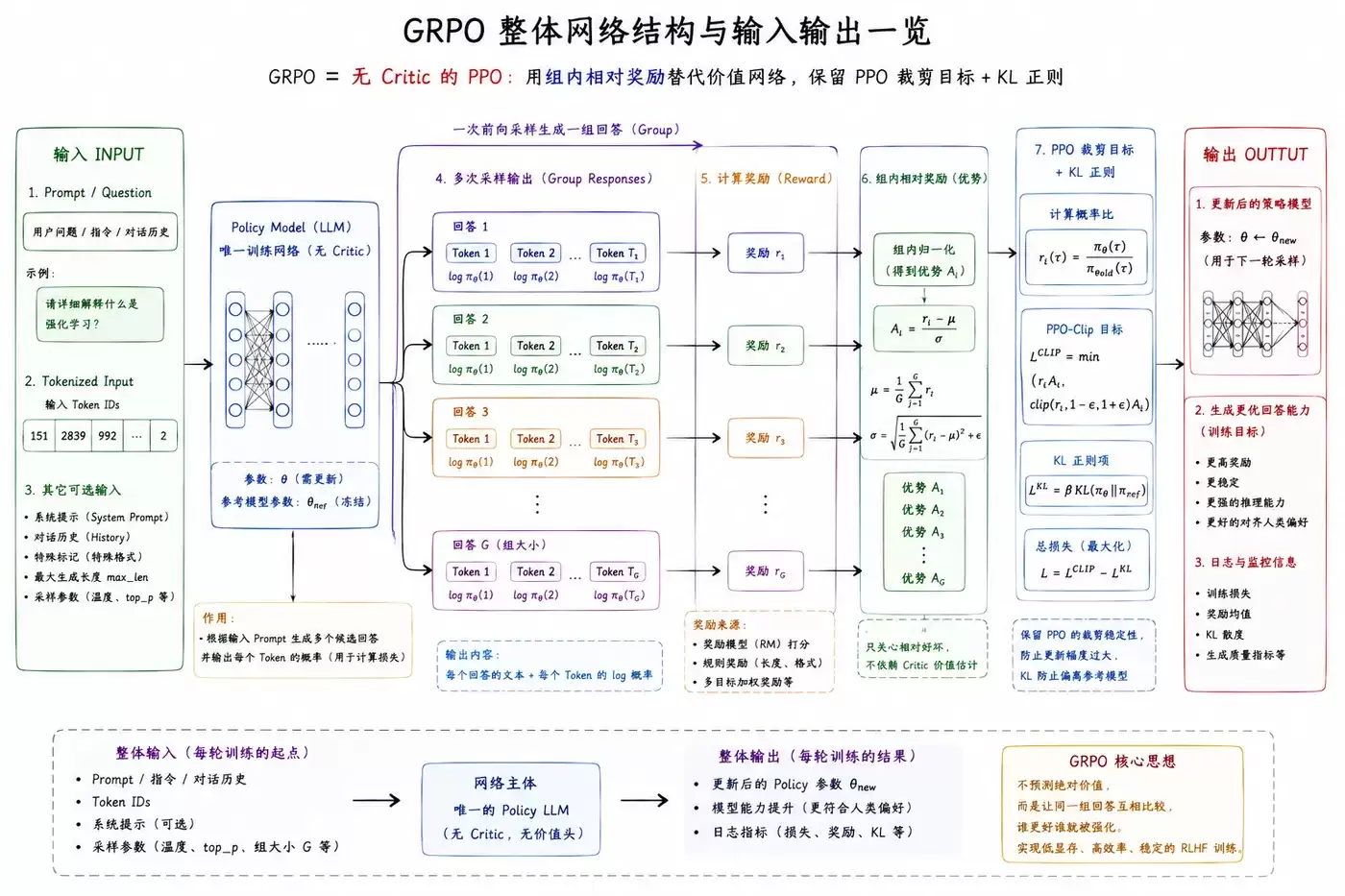
网络更新
GRPO的更新机制融合了PPO的精华并加以创新。
使用的损失函数:
根本目的:
更新流程与输入:
每一次更新需要以下输入:
- 状态/提示词 (s)
- 旧策略的动作概率 (π_old)
- 新策略的动作概率 (π_new)
- 组内归一化优势 (A),这来源于对同一提示词多个回答的奖励进行组内计算和归一化。
- 参考模型的概率 (π_ref),用于计算KL散度。
计算步骤可以概括为:
- 计算新旧策略的概率比:r = π_new / π_old。
- 将这个比率裁剪到一个安全的区间内,例如 [1-ε, 1+ε]。
- 通过公式 min(r*A, clip(r)*A) 计算得到裁剪损失项。
- 计算当前策略与参考模型之间的KL散度。
- 总损失 = 裁剪损失 + β * KL散度(β是正则化系数)。
- 最后,通过反向传播,更新唯一的Actor网络参数。

这种设计带来了几个显著特点:
- 只更新一个网络,大大节约了显存。
显存占用极低:
- 因为没有价值网络,也就避免了价值函数估计不准带来的误差和波动。
训练极其稳定:
- KL散度约束像一根“安全带”,确保模型在优化特定目标时,不会忘记原有的知识和能力。
防止模型退化:
- 组内归一化的优势计算方式,使得算法对奖励的绝对数值大小不敏感,减少了超参数调整的负担。
免于奖励尺度调参: