
让莘莘学子夜不能寐的AIGC检测,到底是什么
“长亭外,古道边,芳草碧连天。问君此去几时来,来时莫徘徊。”又到一年毕业季,但对于2026年的许多应届生而言,离愁别绪之外,更添了一份实实在在的焦虑——如何应对毕业论文的AIGC检测。今年高校的各类群聊里,一个话题被反复刷屏:“AIGC检测,到底要怎么过?”

说起来,当下拥抱AI最积极的群体,或许并非担心被取代的职场人,而是象牙塔里的学生。甚至有戏言称,大学课堂里的新“内卷”,已经从比拼谁更努力,转向了比拼谁的提示词工程更精湛。
在生成式人工智能(AIGC)浪潮席卷的第四个年头,高校的应对措施已从观望转为行动。将AIGC检测纳入毕业论文审核流程,不再是“可能”,而是“必须”。
例如,四川大学明确要求,文科类毕业论文AI生成内容占比不得超过20%,理工医科类则不超过15%。广西师范大学、南京航空航天大学等高校也划定了红线,规定AIGC内容比例不高于40%。更关键的是,处罚措施已升级:一旦检测不合格,面临的往往不是“退回修改”,而是“延期答辩”。
AIGC检测的“罗生门”:从学生吐槽到经典“中招”
如今,在小红书、微博、抖音等社交平台搜索“AIGC检测”,满屏都是应届生的焦虑与吐槽。围绕“AI率过高”这个核心痛点,甚至衍生出了一条灰色产业链:分享所谓的“降AI率邪修秘籍”、推销各种降重工具,以及对检测技术本身的广泛质疑。
一位小红书用户的经历颇具代表性。TA的论文在维普AIGC检测中显示AI率高达48%。尝试了各种修改,甚至付费使用工具后,AI率也仅下降几个百分点。无奈之下,TA做了一个看似荒诞的操作:将全文的逗号一键替换为句号,其他内容一字未改。结果令人瞠目——AI率骤降至11.51%。
这并非孤例。更令人啼笑皆非的是,当人们将经典文学作品投入检测工具时,结果更是荒诞。朱自清的《荷塘月色》被判定为62.88%由AI生成;刘慈欣的《流浪地球》AI率超过50%;而千古名篇《滕王阁序》,甚至被标注了100%的AI率。
此类乱象,最终引来了央视的关注,专门探讨AIGC检测技术的科学性问题。那么,问题究竟出在哪里?为何检测结果时而显得如此“随机”?要回答这个问题,还得从它的底层原理说起。
原理拆解:AI如何“看”文章?
目前市面上主流的AIGC检测工具,其核心算法大多围绕两个关键指标:“困惑度”和“突发性”。简单说,就是通过衡量词语的可预测性和文本节奏的频率变化,来判断内容是否具有AI生成的特征。
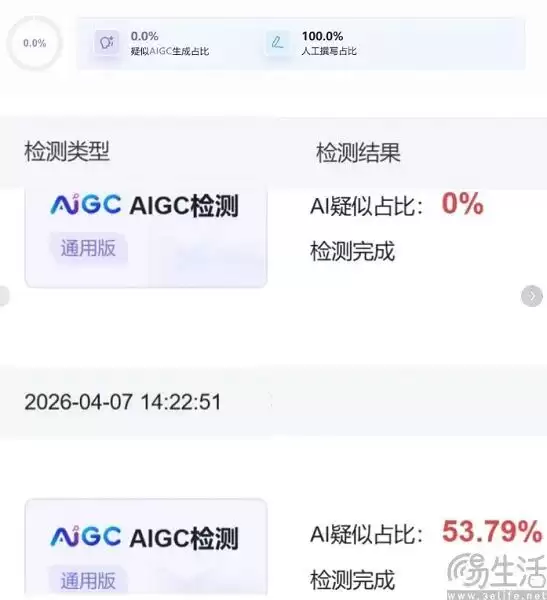
在我们人类的认知里,文字是承载语义和逻辑的。但在基于Transformer架构的AI大模型眼中,世界被“降维”处理,变成了一个个“词元”。模型的工作原理,是通过计算上下文,预测下一个最可能出现的词元是什么,并依此生成文本。这本质上是一个统计概率游戏,而非AI真正理解了文字的含义。
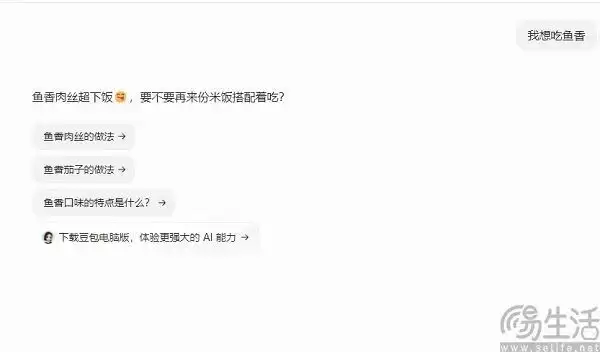
举个例子,当AI接收到上文“我想吃鱼香”时,它会基于海量数据计算出,接下来出现概率最高的词元很可能是“肉丝”。一些更“聪明”的模型,甚至会顺势生成一份菜谱。正因为AI在写作时倾向于选择概率最高的路径,导致其产出的文本,在专门训练过的检测AI看来,“困惑度”很低——即过于 predictable(可预测)。
“突发性”则关乎文章的结构与节奏。如果一篇文章的句式过于工整、逻辑过于严密、用词过于标准,就会呈现出高“突发性”。这解释了为何《滕王阁序》会被判100% AI率。并非因为它真是AI写的,而是其作为“千古第一骈文”的极致特性——声律调谐、对仗工整——在AI检测模型看来,完美得“不像真人写的”。
说到底,AIGC检测的底层逻辑是一种“相似度猜测”:猜测你的文本与AI大模型的典型输出模式有多像。这倒不是开发者不努力,实在是“道高一尺,魔高一丈”。AI大模型本身在飞速进化,让“用AI检测AI”这件事,变得越来越像一句空话。
行业困境:为何没有“可靠”的检测器?
一个残酷的事实是,迄今为止,整个AI业界都未能推出一款公认可靠、准确的AI文本内容检测工具。当前的普遍思路,已经从“事后检测”转向了“源头标记”,即AI数字水印技术。
具体做法是,在生成式AI输出图片、视频时,于元数据中嵌入不可见的溯源水印。为此,微软、谷歌、Adobe、OpenAI、Meta等巨头联合成立了“内容来源和真实性联盟”。目前,ChatGPT、Gemini等主流AI工具生成的部分内容,已开始集成此类凭证。
然而,C2PA标准也有其明显的局限性。它在图像、视频领域效果尚可,但在文本领域却几乎失灵——因为纯文本太容易被复制、粘贴和篡改,水印信息无法留存。
于是,我们便面对这样一个尴尬的现实:市面上根本不存在100%准确的AIGC文本检测工具。这些工具给出的所谓“AI率”,更准确的解读是“内容带有AI风格特征的概率”,而非“内容直接由AI创作的概率”。
应对策略:如何与不完美的检测系统“周旋”?
困境在于,检测工具不靠谱是事实,但高校将其作为硬性考核标准也是事实。学生们别无选择,只能想方设法让报告上的数字“达标”。不过,花钱购买专门的“AI降重”工具,在当下可能已是徒劳。
那些付费工具惯用的“打乱句式”、“替换同义词”等套路,对于2026年已迭代多次的检测算法来说,早已失效。如今,简单地将“重要”改为“关键”,把“因此”换成“故而”,依然会被精准识别。真正有效的方法,是进行语义层面的深度重构。

针对“突发性”过高的问题,一个实用的技巧是:刻意调整行文节奏。交替使用长句与短句,避免句式过于单一;同时,有意识地减少“然而”、“但是”、“因此”这类转折词的密度,让文章的流动感更接近人类随性的思考痕迹。
而对于更棘手的“困惑度”问题,则有一些更深入的“心法”。可以尝试在论述中更多地融入第一人称视角和批判性表达。这是因为,当前的主流AI大模型为了提升用户满意度和留存率,通常倾向于迎合用户,避免采用强烈的批判立场。同时,为了营造“客观中立”的观感,AI在交流中也极少使用“我认为”、“我觉得”这类第一人称表述,而是采用更抽离的第三方视角。恰恰是这些AI刻意避免的特征,成为了人类作者降低“困惑度”的突破口。
说到底,在AI与检测工具“魔道相长”的博弈中,理解规则,并巧妙地展现属于人类的、不完美的、带有温度和独特视角的思考痕迹,或许才是通过这场“毕业大考”的关键所在。




