狂揽200余项SOTA!阿里发布Qwen3.5-Omni:多模态能力超越Gemini-3.1 Pro
来源:互联网
时间:2026-03-30 23:25:18
3月30日消息,
阿里今日正式发布千问新一代全模态大模型Qwen3.5-Omni。
据悉,Qwen3.5-Omni采用混合注意力MoE架构,可实现图片、视频、语音、文字等全模态内容的输入与输出。
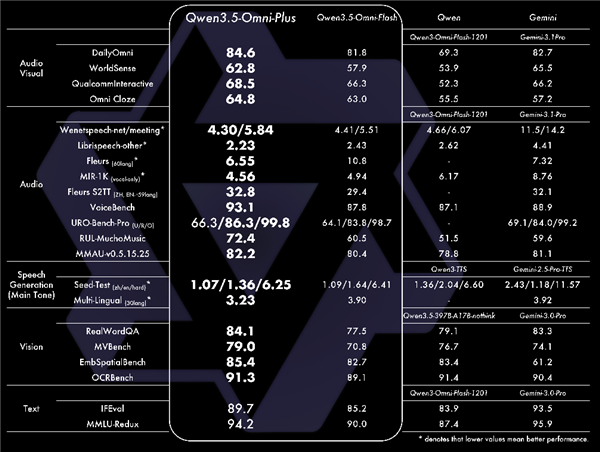
在音视频理解、识别、交互等215项任务中,Qwen3.5-Omni取得SOTA(性能最佳),超越Gemini-3.1 Pro,成为目前全球最强的全模态大模型之一。

例如在聚焦视听交互能力的DailyOmni、QualcommInteractive、Omni Cloze等测试中,Qwen3.5-Omni得分大幅领先Gemini-3.1 Pro。
在检测嘈杂环境抗干扰能力的WenetSpeech测试中,Qwen3.5-Omni错误率远低于Gemini,识别准确率极高。
在考察多语言语音生成质量的Multi-Lingual (30lang) 测试中,Qwen3.5-Omni同样显著优于Gemini-2.5-Pro-TTS。
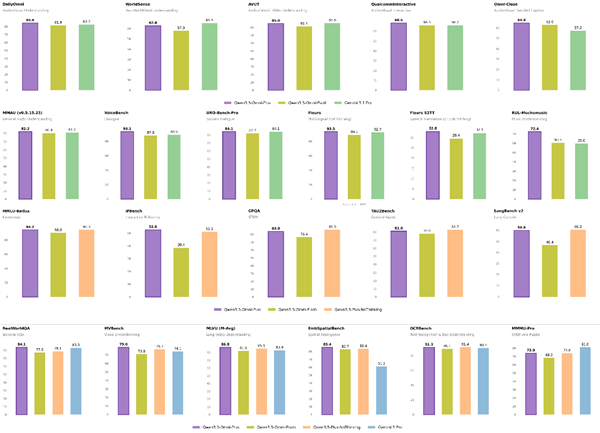
目前,Qwen3.5-Omni拥有极强的音视频理解与实时交互能力,能够对音视频内容生成详细且可控的结构化描述。
新模型支持113种语言及方言的语音识别和36种语言及方言的语音生成,就连使用人数不足一百万的毛利语和国内的海南方言,也能精准识别。
同时,基于一系列技术创新,Qwen3.5-Omni还将Vibe Coding能力推入下一阶段。
与纯文本或图片驱动的Vibe Coding不同,千问可以实现音视频编程:打开摄像头,用户对着草图口述需求,哪怕是包括复杂产品逻辑的描述,模型也能直接生成带有复杂UI的产品原型界面,真正实现“动动嘴即可编程”。
而Qwen3.5-Omni顶尖的全模态能力,还能为专业领域带来超级生产力。
新模型可对画面主体、人物关系、对话逻辑、乃至人物情绪起伏进行极细的拆解,并自动完成视频章节切片与时间戳标注,支持超过10小时的音频输入。
目前,阿里云百炼已上新Qwen3.5-Omni的Plus、Flash、Light三种API,可广泛应用于短视频/直播平台、游戏、自媒体等行业。
普通用户可前往Qwen Chat免费体验,开发者和企业可通过阿里云百炼平台调用Qwen3.5-Omni模型,每百万Tokens输入不到0.8元,比Gemini-3.1 Pro的1/10还低。
当前,千问已稳居中国企业级大模型调用市场第一,服务涵盖互联网、金融、消费电子及汽车等重点行业超100万家客户。