
基于TinyMce富文本编辑器的客服自研知识库的技术探索和实践|得物技术
先说说我们为什么需要自研一套客服知识库。在自研系统上线之前,得物一直用的是第三方采购的知识库。业务跑得越来越快,知识文档的维护量、下游系统的调用频次都在涨,老系统在协作效率和定制能力上确实有点跟不上了。基于这些现实问题,咱们自己上手,从零搭了一套客服知识库。
一、背景
客服知识库,简单说就是个集中管理和存储客服相关知识资源的系统。业务体量上来后,知识维护的工作量和下游系统的使用痛点越来越明显——第三方系统毕竟是“别人家的孩子”,想要快速响应内部需求、打通系统间的协作,确实力不从心。这才是推动自研的关键动力。
二、富文本编辑器的选型
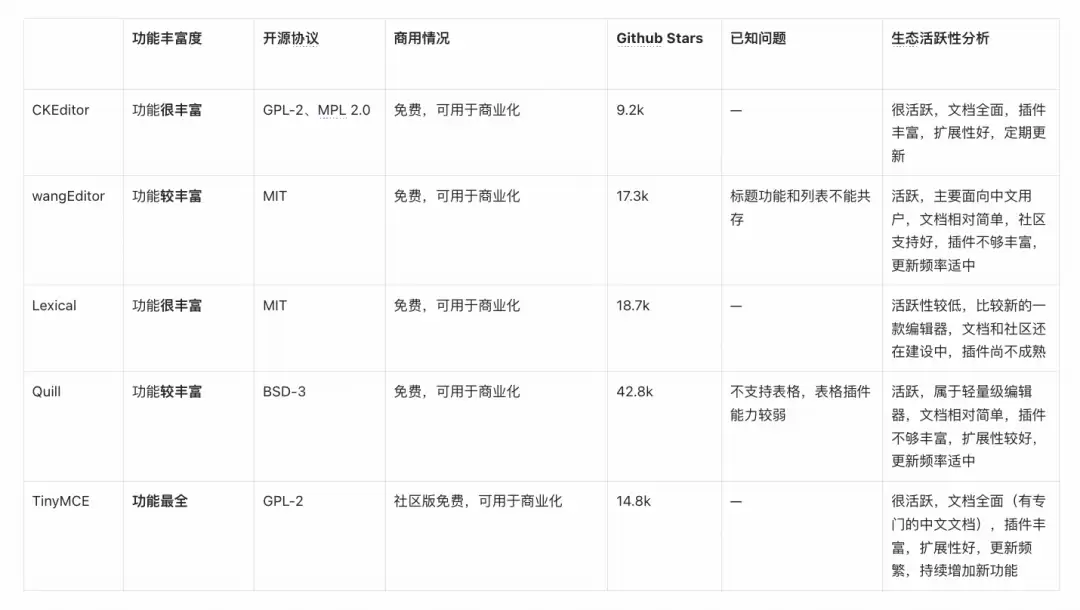
选编辑器这事,其实是个硬仗。市面上能打的富文本编辑器不少,但各有各的脾气。我们拉了个对比表,挨个过了一遍关键能力:表格支持、协作功能、扩展性、文档成熟度……这些维度一个都不能少。
编辑器的选择
首先看的是Quill。Quill本身的表格编辑能力是个明显的短板——虽然有插件能补上,但体验下来,表格操作不够丰富,交互感也一般,直接出局。
wangEditor则遇到了另一个尴尬:标题和列表(有序、无序)这两个功能居然互斥。对于知识库场景来说,这两个都是刚需,所以也只能放弃。
Lexical是Facebook推出的产品,功能层面确实不错,但文档和社区活跃度比起CKEditor、TinyMCE还有差距,插件生态也不够成熟。权衡下来,重点考察CKEditor和TinyMCE。
这两款编辑器各有千秋。不过我们注意到,老知识库用的就是TinyMCE,如果继续选它,对新老系统之间的格式兼容和数据迁移会顺畅很多。加上TinyMCE在功能丰富度上略有优势,最终TinyMCE胜出。
TinyMCE编辑器模式的选择
TinyMCE提供了两种运行模式,各有适用场景。
经典模式(默认模式)
基于表单实现,编辑器始终作为表单的一部分嵌入。内部使用iframe沙箱隔离编辑内容和页面样式,样式隔离效果很好。但缺点也很明显:iframe带来了额外的性能开销,尤其是多实例编辑器场景下,性能会有点吃力。
内联模式(沉浸模式)
这种模式把编辑视图和阅读视图合二为一——内容平时以阅读态展示,点击后才激活编辑器。性能更好,实现了真正的“所见即所得”。但代价是内容会直接继承页面的CSS样式,容易被外部样式干扰。
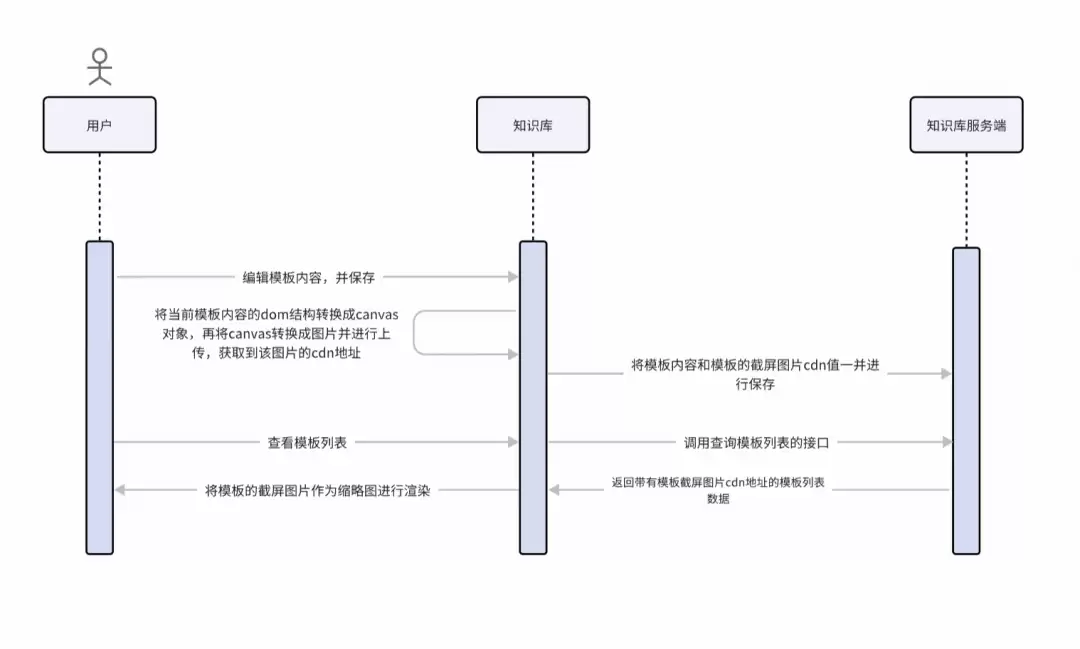
三、系统总览
知识创建链路
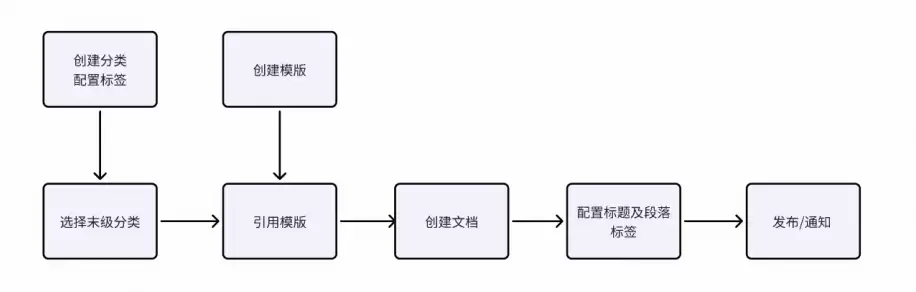
从知识创建到最终落地的完整链路,可以参考上面的示意图。
知识采编
结构化段落
为了让知识文档能被更细粒度地解析,我们引入了“结构化段落”的设计思想。每个段落都有唯一标识,还可以单独设置标签。这样一来,后续进行知识检索和分类时,就能够精确锁定到文档中的具体段落,而不是整篇文章。
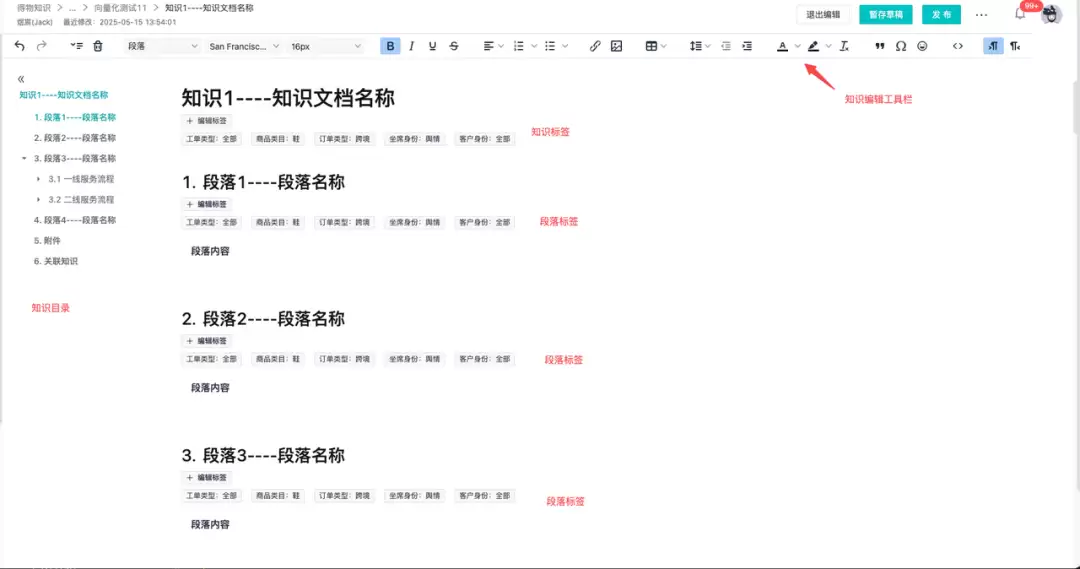
上图是知识文档的编辑页面。
应用场景
知识检索
基于传统的ES搜索引擎,支持按关键字检索知识库内容。检索结果可以直接在工作台打开对应的知识,并且能定位、滚动到具体的段落,匹配到的关键字也会高亮显示。

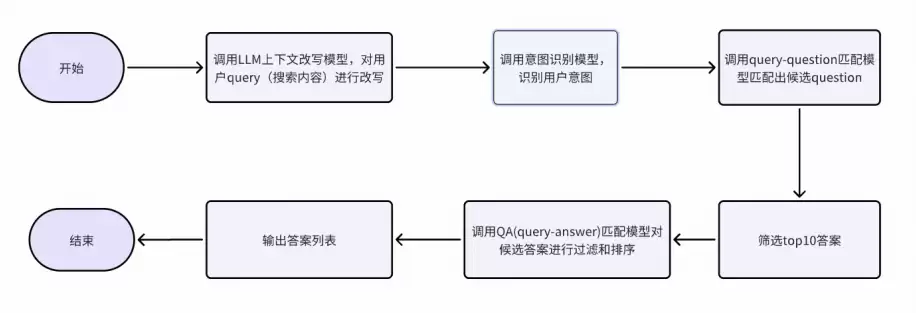
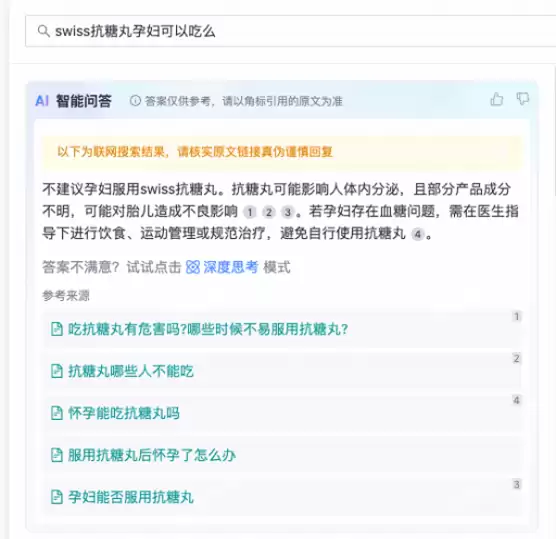
智能问答(基于大模型+知识库底层数据)
这里有两个核心能力:
RAG出话
核心价值在于辅助客服理解用户的真实意图,作为客服作业时的参考。RAG(检索增强生成)的工作流程分两步:检索阶段根据用户查询从知识库中找出相关信息(包括知识内容、订单信息、商品信息等);生成阶段则把这些检索到的信息作为上下文,生成更精准、更相关的回答。既可以把检索结果直接返回给用户,也可以结合LLM模型精加工后再输出。
答案推荐
可以结合用户的搜索内容、订单信息、商品信息等上下文场景,自动推算出最合适的答案,帮助客服更快地解决问题。
流程示意:
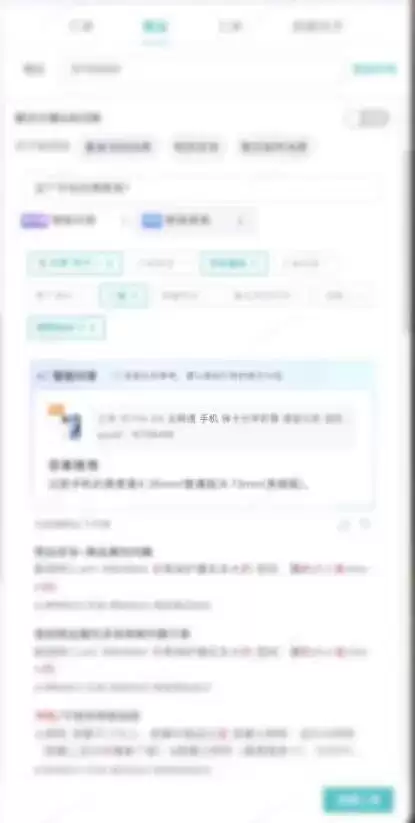
联网搜索
当RAG出话因为拒识没有结果时,系统会尝试联网搜索作为补充。底层接入的是第三方联网问答Agent服务。链路中增加了风控校验和意图清单过滤,只有符合设定的意图才会触发联网搜索。

四、问题和解决方案
解决图片迁移问题
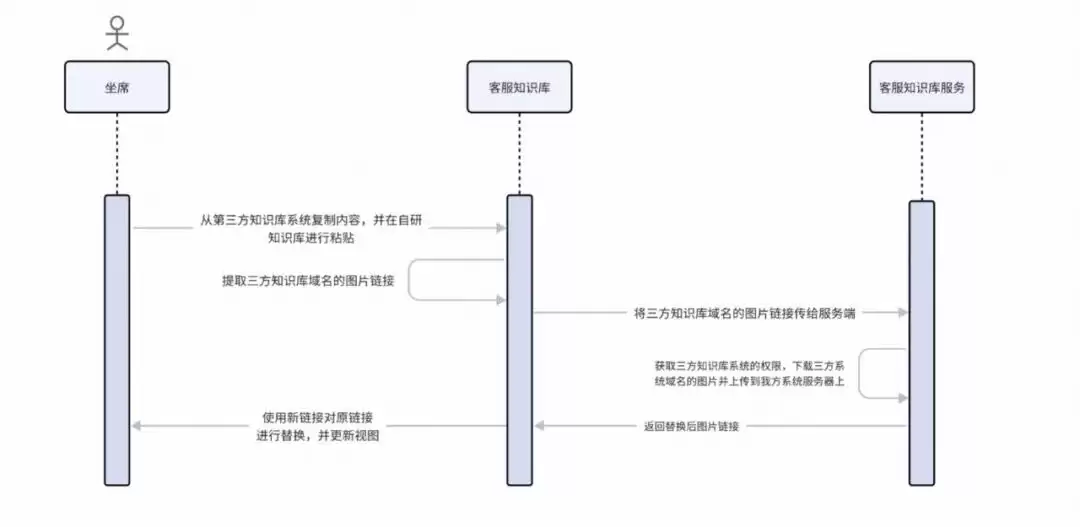
背景
新老知识库迁移时遇到一个棘手的问题:老知识库里的图片链接,域名指向的是老系统的地址。要想在新系统中正常访问和渲染这些图片,必须拥有老系统的登录凭证。这显然不现实。
解决方案
我们对用户粘贴内容的行为进行了监听,遇到来自老知识库的图片链接,自动把链接替换成新系统中可访问的地址。
核心逻辑
/**
* 替换编辑器中的图片URL
* @param content
* @param editor 编辑器实例
* @returns 替换后的内容
*/
export const replaceImgUrlOfEditor = (content, editor) => {
// 提取出老知识中的图片访问链接
const oldImgUrls = extractImgSrc(content);
// 调用接口获取替换后的图片访问链接
const newImageUrls = await service.getNewImageUrl(oldImgUrls);
// 将老知识库的图片链接替换成新的可访问的链接
newContent = replaceImgSrc(newContent, replacedUrls.imgUrls);
// 使用新的数据更新编辑器视图
editor.updateView(newContent);
};
解决加载大量图片带来的页面卡顿问题
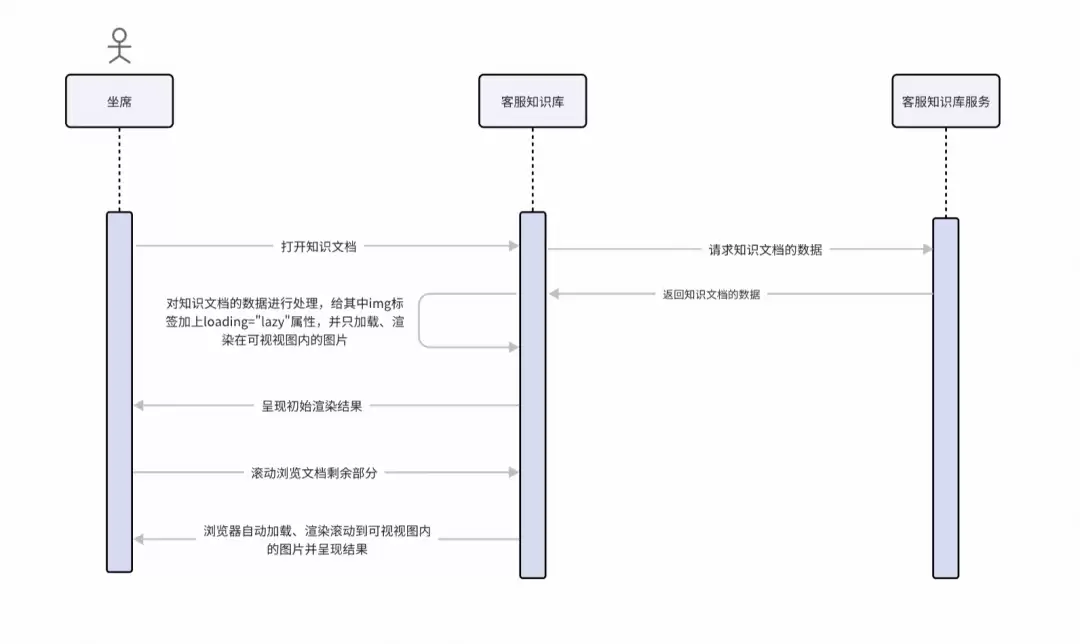
背景
知识库里图片多,打开一篇知识文档时,系统往往因为短时间内加载和渲染大量图片而直接“冻住”。这在老知识库中尤其严重,也是新系统必须攻克的核心问题。
解决方案
核心思路是图片懒加载:打开文档时,只加载视口内的图片,其余图片滚动到视口范围内才开始加载和渲染。
但这里有个难点——知识文档的内容本身是一段HTML字符串,最小渲染单元是段落(结构化段落),而每个段落的内容大小和图片数量完全不可预知。传统基于滚动位置的懒加载方式在这里并不适用:如果滚动到某个段落时,该段落恰好包含大量图片,依然会造成卡顿。
我们换了个思路:用正则表达式从HTML中提取所有img标签,将每个图片的加载与段落滚动解耦,实现更细粒度的控制。
模板缩略图
背景
在知识模板列表页或新建知识选择模板时,需要展示模板内容的缩略图。不同模板内容各不相同,缩略图需要展示模板靠前的内容,帮助用户除了看标题外,还能通过内容预览来选择最合适的模板。
解决方案
在保存模板之前,对模板进行截图,然后上传到CDN保存链接,再对截图做适当的缩放处理,作为模板的缩略图。
实际效果
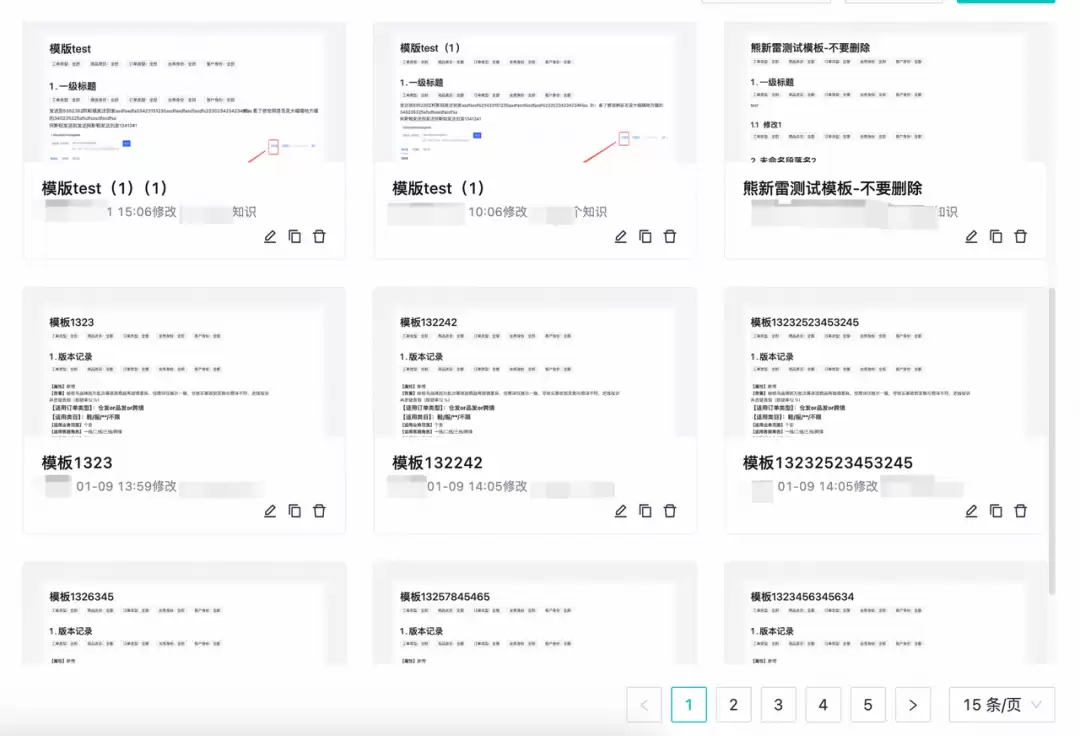
模板列表中缩略图展示效果
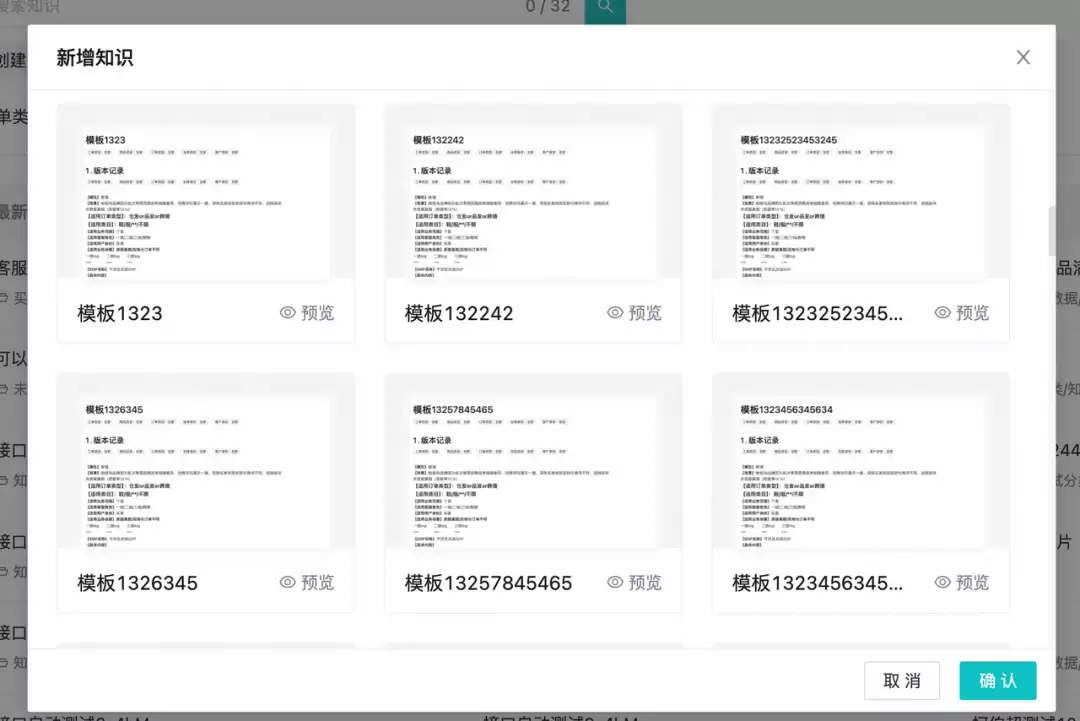
新建知识时缩略图展示效果
全局查找/替换
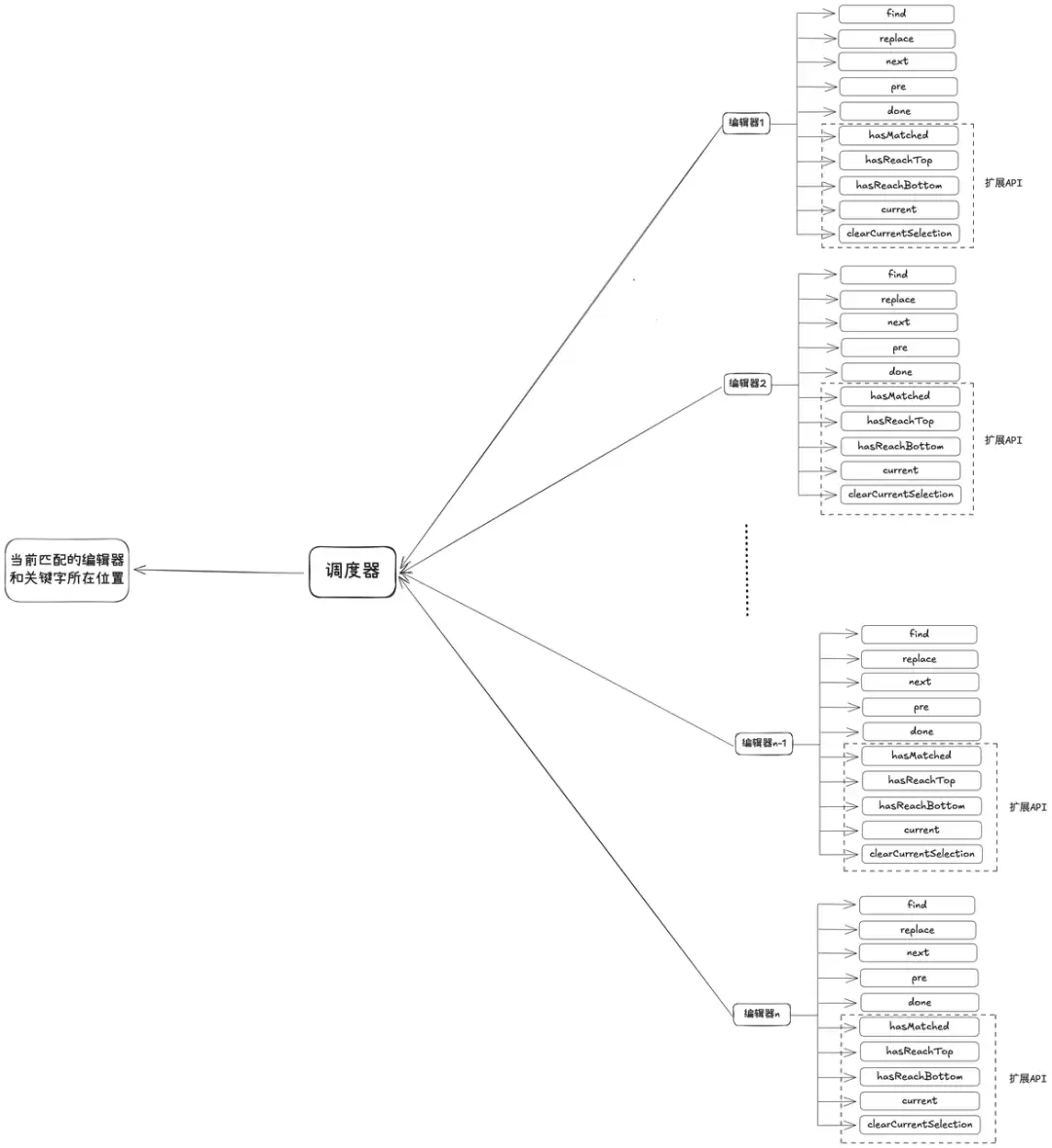
背景
因为采用了结构化段落的设计,每个段落都是一个独立的编辑器实例,导致编辑器的原生查找/替换功能只能针对当前焦点的编辑器生效,无法同时检索所有段落。这对编辑人员来说,无疑是增加了操作成本。
解决方案
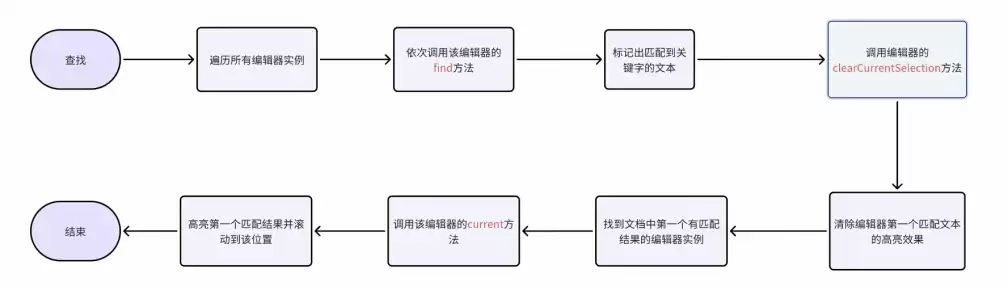
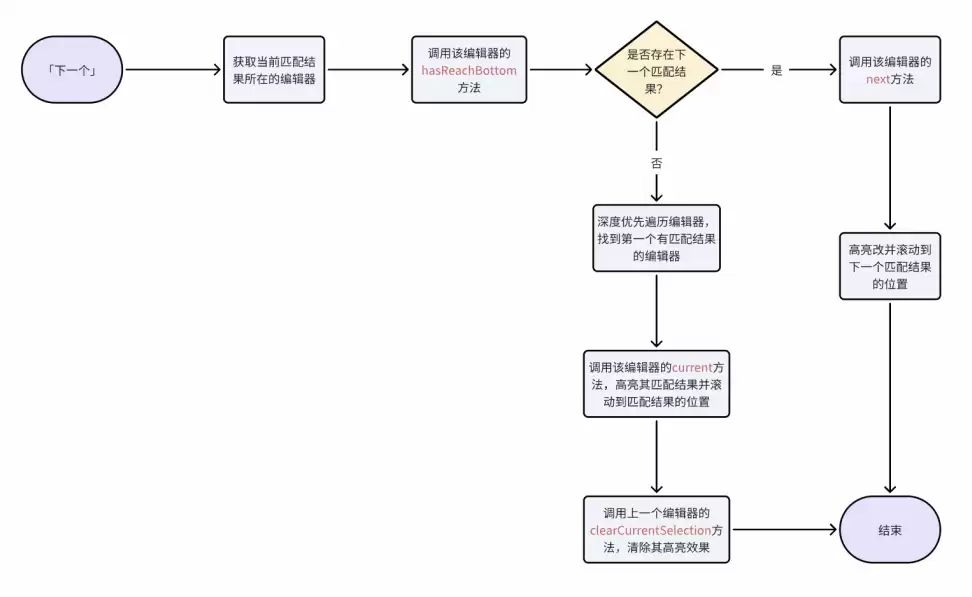
我们对编辑器的查找/替换插件源码进行了深入分析,发现其核心依赖5个API:find、replace、next、prev、done。基于这5个API,我们在多个编辑器之间引入了一个调度器,用来控制编辑器之间的接力,实现全局范围内的查找/替换。同时扩展了插件API,辅助调度器在多编辑器之间进行协同。
插件源码API扩展:
- :判断当前编辑器是否匹配到关键字。
hasMatched
- :判断当前编辑器是否已到达查找关键字的最前一个。
hasReachTop
- :判断当前编辑器是否已到达查找关键字的最后一个。
hasReachBottom
- :滚动到编辑器当前匹配到的关键字的位置。
current
- :取消编辑器当前匹配的关键字的高亮效果。
clearCurrentSelection
UI替换
屏蔽了插件自带的查找/替换弹窗,改用react-rnd库实现了一个支持拖拽的全局查找/替换弹窗。

「查找」
期望效果
「下一个」
期望效果
五、总结
新版客服知识库的研发和落地,是在TinyMCE编辑器的基础上做了大量的功能扩展和定制。过程中既有参考飞书文档、语雀等同类产品的方案,也有基于实际场景的创新设计。截至目前,已有1000+篇老知识库顺利完成迁移,系统运行稳定。
自研不仅解决了老系统的卡顿和定制化需求不足等顽疾,还在满足基本需求的前提下,通过优化交互方式和文档的加载、渲染性能,进一步提升了用户体验。后续团队会继续结合用户反馈和实际使用需求,持续优化和扩展知识库功能,也欢迎遇到类似场景的同学一起交流。
