
RBAC + 细粒度 ACL:GreptimeDB 企业版用户管理详解
不少人可能觉得,生产环境的数据库嘛,配一个共享用户名和密码就能应付了。但说实话,真到了线上环境,这种“一把钥匙开所有门”的做法,风险太大了。数据采集管道可能只需要往里写数据,开发人员只查不写,而管理员得管全局。每个角色、每个服务的访问权限,最好都卡得死死的。
GreptimeDB 开源版本身已经提供基于文件配置的细粒度权限管理,对大多数场景来说够用了。但企业内部的需求,常常会更拧巴一些:需要更细致的管控,更严格的审计。企业版内置的用户管理系统,就是奔着这个目标来的。你不再需要依赖一堆静态密码文件,也不用一上来就硬接外部的身份系统。直接在数据库集群内部管理用户——账号存得住,权限分得细,还自带管理界面。
说白了,访问控制这件事,很多团队都是从“够用就行”开始,慢慢变得复杂。一旦部署上了生产环境,需求就不一样了:
- 数据采集管道,不该有管理员权限。
- 分析师,不应该能改数据库。
- 应用服务,只能访问自己的表。
- 运维人员,需要一种安全、长期的方式来管理用户。
内置用户管理的思路,就是让 GreptimeDB 企业版直接接手用户的整个生命周期:账号持久化在 Metasrv 的 KV 存储里,所有 Frontend 节点保持一致;每次操作,数据库都强制执行权限检查;管理操作通过内置的 HTTP API 和 Enterprise Dashboard 完成。
下面快速说说,这个功能到底怎么用。
启用功能
要开启内置用户管理,只需要在 GreptimeDB 企业版 Frontend 的配置中设置 user_provider 选项(单机模式则在 standalone 配置中设置):
user_provider = "greptime_ee_user_provider:/path/to/passwords.txt"
冒号后面的路径,指向一个可选的账号文件,用于首次启动时导入初始账号。如果不需要导入任何用户,直接用 greptime_ee_user_provider: 就行——注意末尾的冒号是必需的,配置解析器要求保留它。
如果用的是官方 Helm chart 部署,把 auth.enabled 和 auth.useBuiltIn 都设置为 true 即可。Chart 会根据 auth.users 生成账号文件(以 Kubernetes Secret 形式)挂载到实例中,并自动完成配置。
导入初始账号
账号文件每行定义一个初始账号,格式是 username[:role]=password:
# username[:role]=password admin:admin=admin_pwd grafana:readonly=grafana_pwd telegraf:writeonly=telegraf_pwd writer:readwrite=writer_pwd
格式很直白:
username是账号名。role是可选的。password是初始密码。
预定义的角色也一目了然:
admin:完整权限,包括用户管理。readonly(或ro):只读。writeonly(或wo):只写。readwrite(或rw):可读可写。
省略角色时,默认是 readwrite。导入的用户,默认拥有 public 数据库的完整访问权限。
注意,导入只在首次启动时执行一次。后续启动时如果发现账号已存在,GreptimeDB 会跳过,不会覆盖它。之后你可以通过 Enterprise Dashboard 修改这些导入的用户。
默认管理员账号
为了简化首次部署,系统会在首次启动时自动创建 admin 账号(如果它还不存在)。
如果设置了环境变量 GREPTIME_ENTERPRISE_ADMIN_PASSWORD,就用它的值作为密码;否则系统会自动生成一个随机密码并打印到日志里。这样,哪怕还没创建任何自定义用户,运维人员也能登录新部署的集群。管理员密码后续还可以通过 CLI 重置。
关于管理员账号和密码重置的更多细节,可查阅文档的参考章节。
权限与 ACL
内置用户管理的模型,由两层控制组成。
第一层是基于角色的访问控制(RBAC)。它回答的问题是:这个用户可以执行哪类操作?
比如,一个用户可能被允许:
- 运行查询
- 写入数据
- 创建或修改表
- 管理数据库
- 执行管理操作
详细的权限定义,以及预定义角色到权限的映射关系,参见文档的权限与 ACL 章节。
第二层是基于 ACL 的访问控制。它回答的是另一个问题:这个用户可以访问哪些数据库或表?
下图是 Enterprise Dashboard 中编辑用户的表单。可以看到 Privileges 区域提供预定义角色,Access Control 区域支持按表勾选和正则表达式匹配:
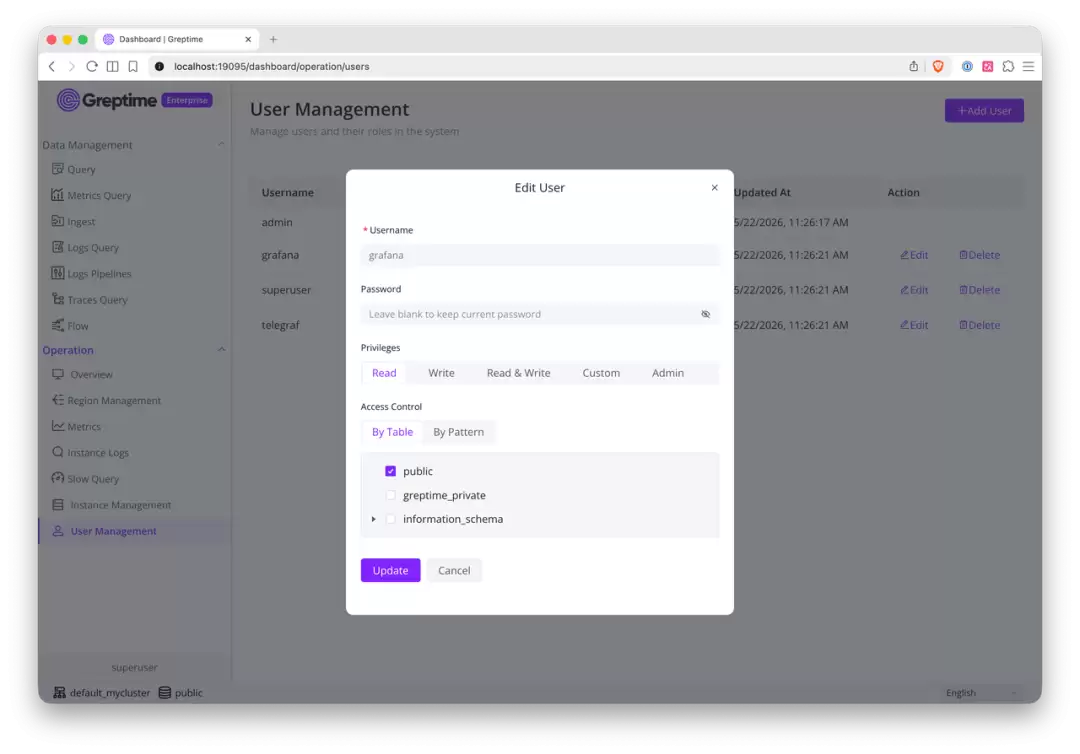
两层结合起来才有意义。两个用户可能都有查询权限,但未必允许查询同样的表。实际上,这个模型可以支撑常见的生产场景:
- 可视化工具只能读取报表数据。
- 采集服务只能写入指定的几张表。
- 团队账号能访问某个数据库,但访问不了另一个。
ACL 支持不同的粒度:可以放开某个数据库的所有表,可以按表名精确授权单张表,也可以用正则表达式匹配,比如 mem_.* 匹配所有以 mem_ 开头的表。小团队可以把模型用得很简单,大规模部署也有足够的演进空间。
所以,内置用户管理不只是解决登录问题:它确保每个账号只能触达它应该触达的数据,由数据库在日常的读、写和 schema 操作中强制执行权限。
日常管理
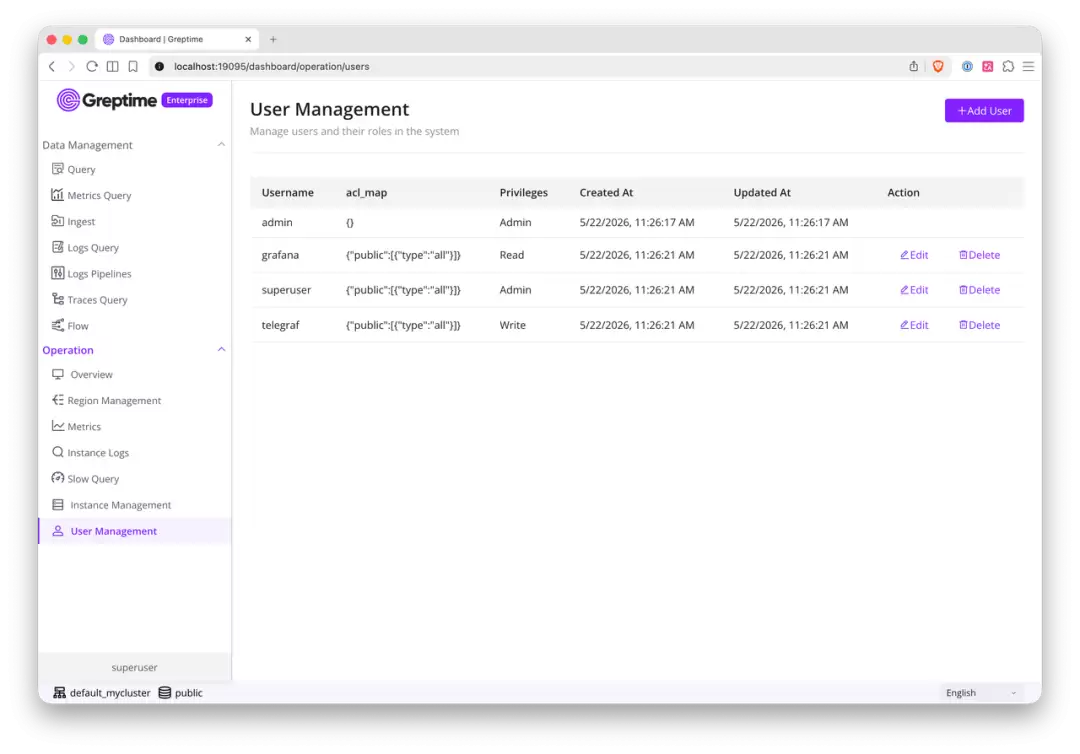
内置用户管理的设计目标是让运维真正好用,而不只是“技术上可行”。
启用后,GreptimeDB 企业版提供内置的 HTTP API 用于用户管理,无需重启服务器即可动态管理用户。Enterprise Dashboard 也让这些操作变得很简单:
- 查看用户列表
- 创建新用户
- 更新权限
- 编辑访问规则
- 删除不再需要的用户
初始配置之后,就不用再手工编辑配置文件了。注意只有拥有 admin 权限的账号才能看到用户管理菜单,且内置的 admin 用户不能通过 API 删除。
适用场景
如果你需要以下能力,内置用户管理会非常合适:
- 由数据库自身管理的持久化用户账号。
- 覆盖常见场景的基于角色的访问控制。
- 更精细地控制用户能访问哪些数据库或表。
- 通过 API 和 UI 完成的内置运维流程。
对于希望获得生产级访问控制、又不想一开始就依赖外部身份系统的团队来说,它尤其合适。
写在最后
GreptimeDB 企业版的内置用户管理,填补了“简单的初始凭证”与“完整的生产级访问控制”之间的空白。
它让你可以在数据库内部完成创建用户、分配角色、限制访问范围和长期权限管理这些事情。对于在生产环境部署 GreptimeDB 企业版的团队来说,从第一天起就遵循最小权限原则,会容易得多。
