
在线文档解析服务横评:TextIn、MinerU、MonkeyOCR 谁最适合企业知识库?
文档解析服务是知识库数据集的“源头活水”,它直接决定了后续问答的准确性。尤其在处理海量文档时,解析质量的高低,几乎与知识库产品的交付成本划等号。
在实际的知识库交付过程中,常见的问题不少:表格错位、公式显示异常、标题层级混乱、图文结构丢失……这些隐患如果在源头没处理好,后续的分块和检索召回,本质上都是在错误的数据上“叠罗汉”,结果可想而知。
对于构建知识库的团队来说,找到一种相对最优的解析服务,尽可能提升数据源质量、降低数据治理成本,是当务之急。
测试标准
综合行业内的反馈,我们重点考察了 MinerU、TextIn 和 MonkeyOCR 这三款主流产品。需要说明的是,PaddleOCR 在线体验无法生成 Markdown 文件,而 Dolphin 只能上传文件、无法预览 Markdown,因此这两款不在本次横评范围内。
考虑到本地部署耗时且变量多,本次评测统一使用各产品的官方在线体验地址,离线或开源版本不参与对比。模型优先采用 VLM 模型,以确保更好的识别效果。评测产物优先以 Markdown 文件为标准——对知识库来说,Markdown 格式是最友好的。
有一点值得留意:文档转 Markdown 必然会损失部分信息。毕竟 Markdown 是一种轻量级标记语言,它擅长文本内容,但无法完整表达复杂的排版和样式。
另外,由于评测文档样本有限,本次测评结果仅反映这些文档在解析服务默认参数下的表现,并不代表服务厂商在其他文档上的处理能力。
测试方案
考虑到文档格式的多样性,我们以 PDF 和 Word 这两种最常用的格式作为测试对象。在文档结构层面,重点关注表格、图文混排、分页、目录识别及复杂版式。核心指标是 Markdown 文档的还原度。
测试数据集
围绕上述标准,我们精心挑选了以下四份具有代表性的文档:
- ——该文档图文混排复杂,重点考察文档结构还原和图片提取能力。
某知名品牌电风扇使用说明书(PDF)
- ——文档包含表格内嵌表格及删除线等特殊格式,重点考察 Word 文档表格的还原能力。
邮件模板(DOC)
- ——全英文文档,关注目录级别识别效果以及跨页表格的识别能力。
跨页表格(PDF)

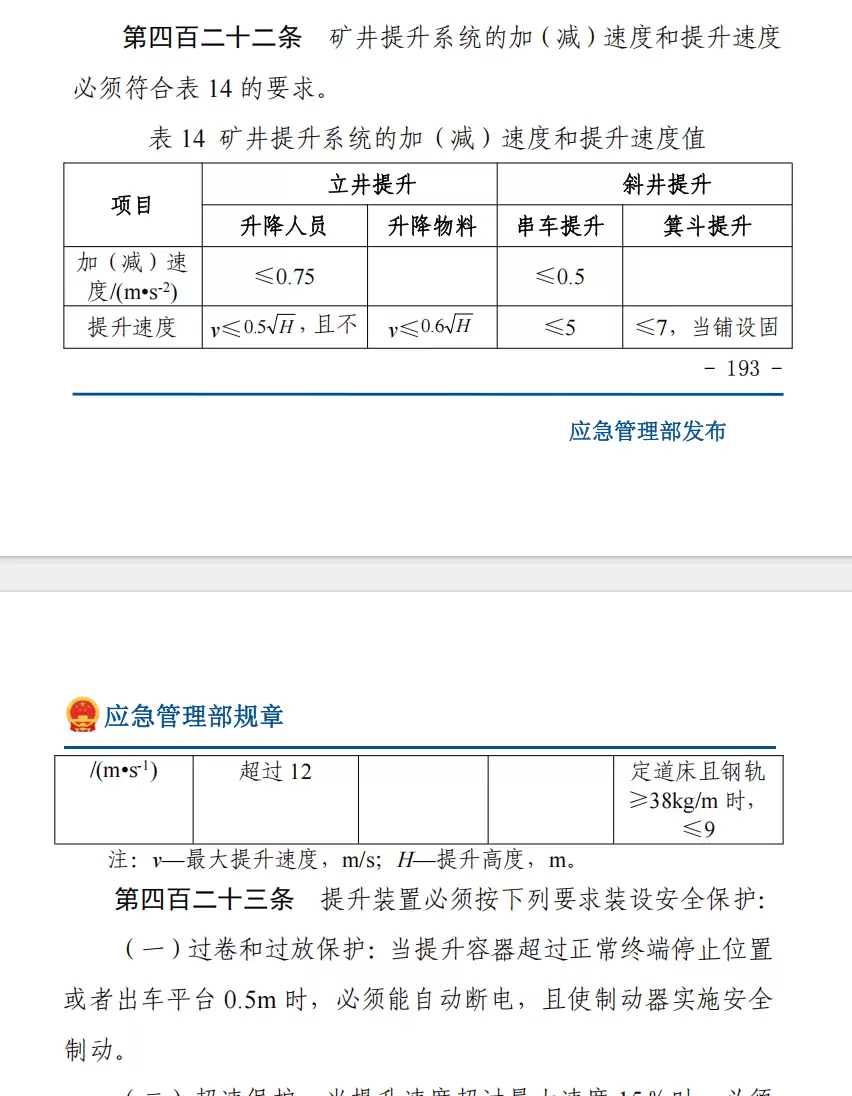
- ——图文混排,包含表格、文字和公式,重点关注表格内公式符号的还原程度。
煤矿安全规程2022版(PDF)
测试过程
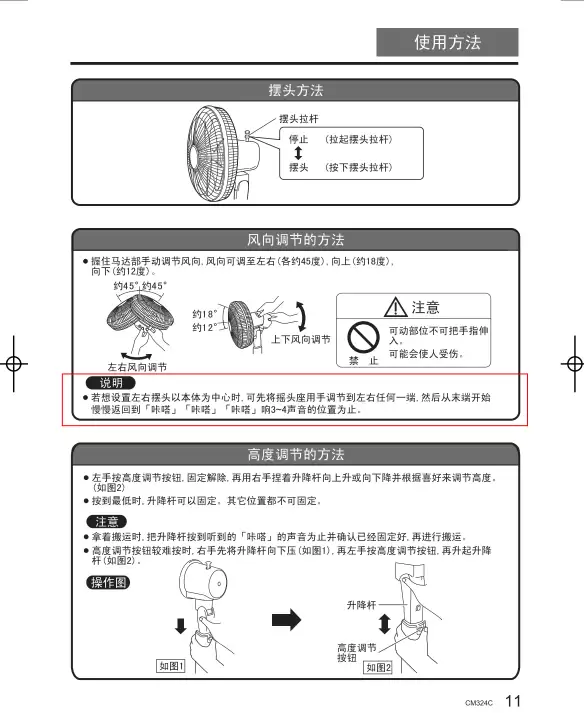
测试案例一:某品牌电风扇使用说明书 PDF 文档
客观来说,这份文档的结构相当复杂。
MinerU 实测表现
整体文本还原度尚可,但无序列表的层级关系没有表达出来,被合并成了一整段,丢失了列表排版。
• 左手按高度调节按钮,固定解除,再用右手捏着升降杆向上升或向下降并根据喜好来调节高度。(如图2)- 按到最低时,升降杆可以固定。其它位置都不可固定。
MonkeyOCR 实测表现

左手按高度调节按钮, 固定解除, 再用右手捏着升降杆向上升或向下降并根据喜好来调节高度。 (如图2)
● 按到最低时,升降杆可以固定。其它位置都不可固定。
层级关系和图片都丢失了,整体表现较差。
TextIn 实测表现
无序列表的关系完美还原,图片也原样重现,和原文没有区别。
·左手按高度调节按钮,固定解除,再用右手捏着升降杆向上升或向下降并根据喜好来调节高度。(如图2)
·按到最低时,升降杆可以固定。其它位置都不可固定。
从文档结构还原来看,TextIn 表现最优。
测试案例二:邮件模板 DOC
为什么选择这个文件?因为它格式特殊——表格相互嵌套,且含有删除线格式,本地用 LibreOffice 转 PDF 时直接崩溃了。
MinerU 实测表现

由于表格跨页,第一页的表格 MinerU 识别得不错,但第二页的列就完全对不上了。
MonkeyOCR 实测表现
MonkeyOCR 在线体验地址不支持 doc 文件,无法对比。
TextIn 实测表现

部分单元格出现了错误合并,但整体来看还原度较高,表格的结构信息基本维持。除去 MonkeyOCR 不支持 doc 外,TextIn 的表格还原相对更好一些。
测试案例三:跨页表格 PDF
MinerU 实测表现
原本预期是一个连续的表格,但实际识别结果被中间的标题分割了,不符合预期。
MonkeyOCR 实测表现

正确识别出了跨页的表格,但没有进行合并操作。
TextIn 实测表现
测试结果令人惊喜:完美合并了跨页表格。
测试案例四:煤矿安全规程2022版 PDF
MinerU 实测表现
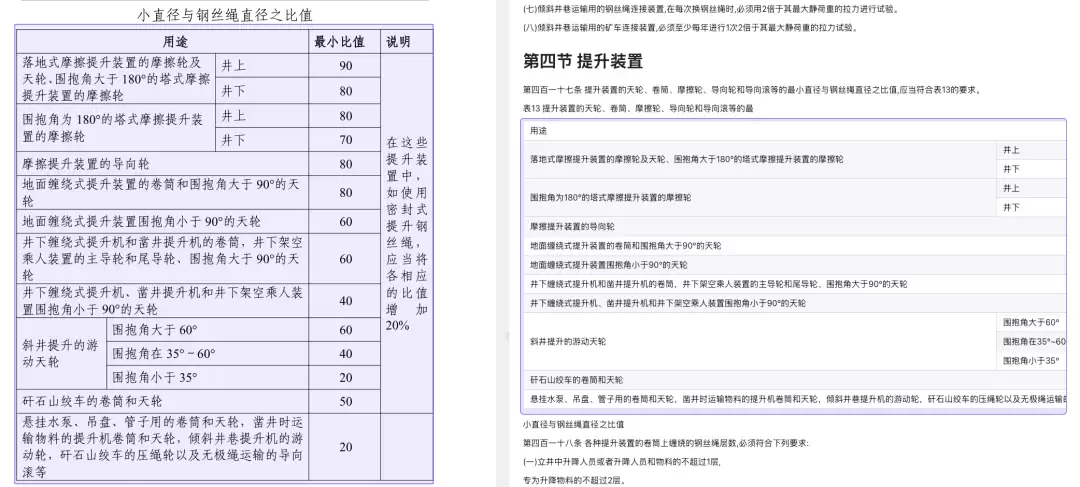
表格识别效果较差,表格最后两列直接丢失了;表格标题也被识别到了表格下方,整体效果不尽人意。
MonkeyOCR 实测表现

识别基本准确,“说明”一列的合并单元格识别有误,但整体效果还是挺好的。
TextIn 实测表现
识别准确,完美还原。
测试结论
本次选取的测试文档,客观来说结构都偏复杂,测试目的也明确围绕“知识库问答系统”所需的文档解析服务展开。
由于样本文档和参数配置的局限性,本次测试结果可能存在一定的随机性。但从整体表现来看,TextIn 在线解析服务在表格识别、文档结构还原、跨页表格处理等场景下表现突出。
从更宏观的角度看,文档排版、复杂图表、表格单元格合并等,依然是当前文档解析的难点,而文档分级目录的识别相对简单。对于重视文档解析质量的企业来说,在搭建知识库时,TextIn 在线文档解析服务当下是个相当不错的选择。
