
从文本到多模态:大模型非结构化数据加工与质量控制实践
大模型训练,本质上是一场数据的精密组织工程。数据从最初的原材料到最终可用于训练的语料,中间经历的加工流程远比想象中复杂。今天,我们沿着三条主线来拆解这件事:文本数据如何从网页变成训练语料、多模态数据如何处理,以及支撑这一切的工程基建怎么搭。
一、文本数据:从原始网页到训练语料
先梳理一下LLM的训练流程。它通常分为四个阶段:预训练、中期训练、监督微调和强化学习。预训练阶段靠的是真实物理世界的数据,比如网页、PDF、书籍;中期训练则开始引入合成数据,专门用来激发模型的推理能力;到了SFT和RL阶段,重点就放在指令跟随和偏好对齐上了。
这些年积累下来的数据量已经相当庞大。网页、代码、视频、音频,总量从百亿、千亿一路攀升到现在的万亿级别。
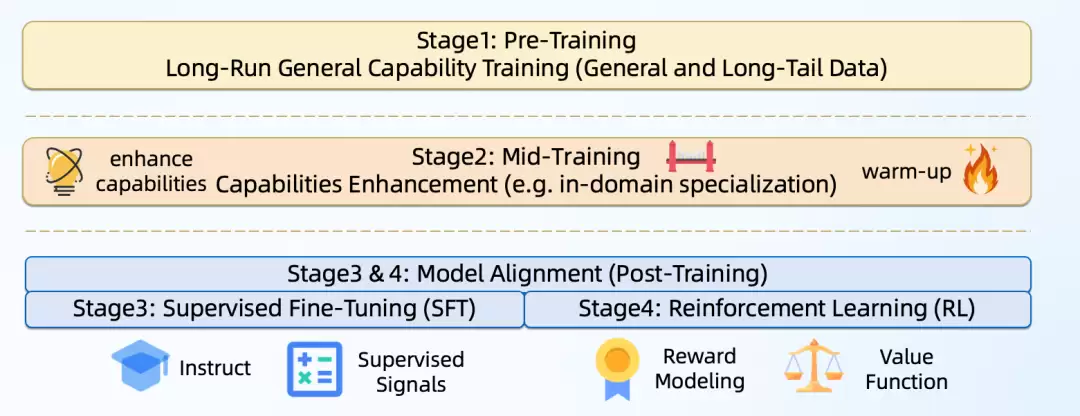

1.1 文本预训练:以原始网页到训练语料为例
拿网页数据来说,从原始HTML到可用的训练语料,通常得走这么六步:

第一步,原始HTML获取。
第二步,网页内容解析。
第三步,网页特征标签。
第四步,标准化流程。
第五步,数据上架与质量评级。
第六步,消融实验验证。
整个数据生产过程中,漏斗效应非常明显。万亿级网页数据存储容量约20PB,真正进到模型训练阶段时,已经缩减到几十亿规模、TB级别,中间少了整整一个数量级。除了网页,像PDF、书籍这类数据,大流程类似,只是过滤策略和算子的实现细节会有不同。
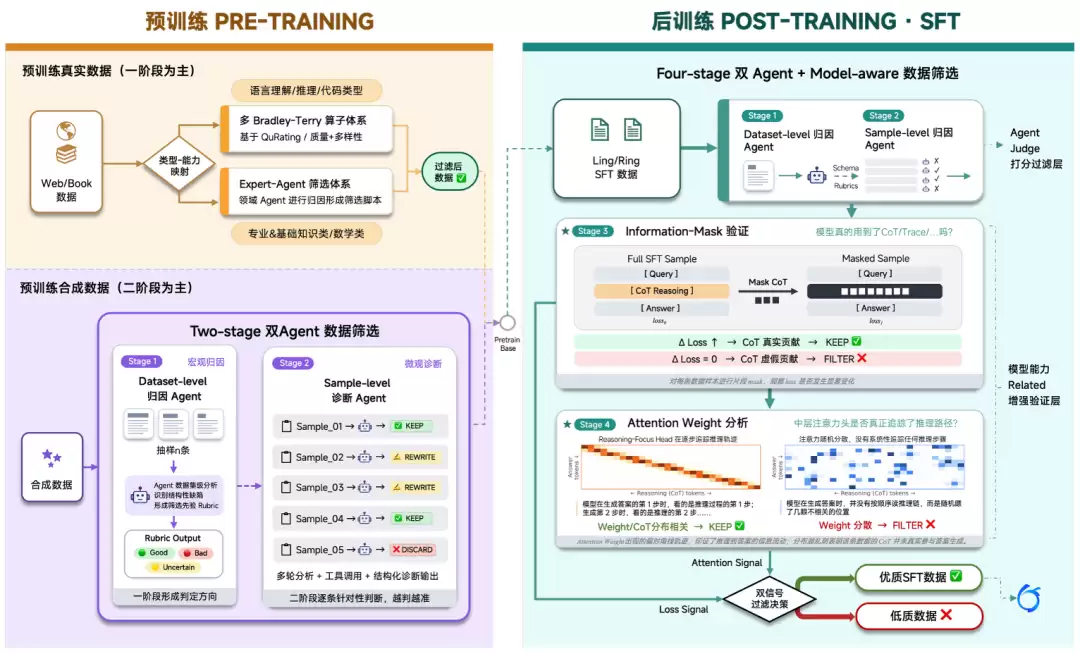
1.2 后训练数据现状
后训练和预训练有个明显的区别:规模更小,但质量要求更高。预训练追求的是海量、多样、覆盖面,数据动辄十亿、百亿甚至更高token量级;后训练更看重任务构造、答案质量和推理轨迹的可靠性,常见规模可能是百万级样本,但每条都得经过更严格的质量校验。
后训练的数据生产方式以合成为主。简单说就是构造一个问题——可能来自现实世界中已有的物理问题,也可能是从原始语料库提取生成——然后拿着这个问题去问一个效果更好的模型,用它的答案和思考过程作为训练样本,来提升自己模型的能力。这个过程叫"蒸馏"或"合成"。
种子数据构建
训练过程中可不只是答案本身,思考过程也会作为训练样本的一部分。关键就在于怎么合成问题,也就是种子。
拿SWE(软件工程)任务来举例。假设你有一个代码问题需要解决,比如修一个bug或加一个新功能。你得生成一个PR,里面包含code diff。就像日常开发那样:根据需求改代码、写测试用例、最后合并上线。SWE的目标就是构建Pipeline,生成issue、PR和测试用例,让模型学会解决这类问题。
生成种子数据有两种方法。第一种是从GitHub爬数据。GitHub上有大量真实的代码仓库、源代码、注释、测试用例。我们把这些信息提取出来,转化成训练样本。
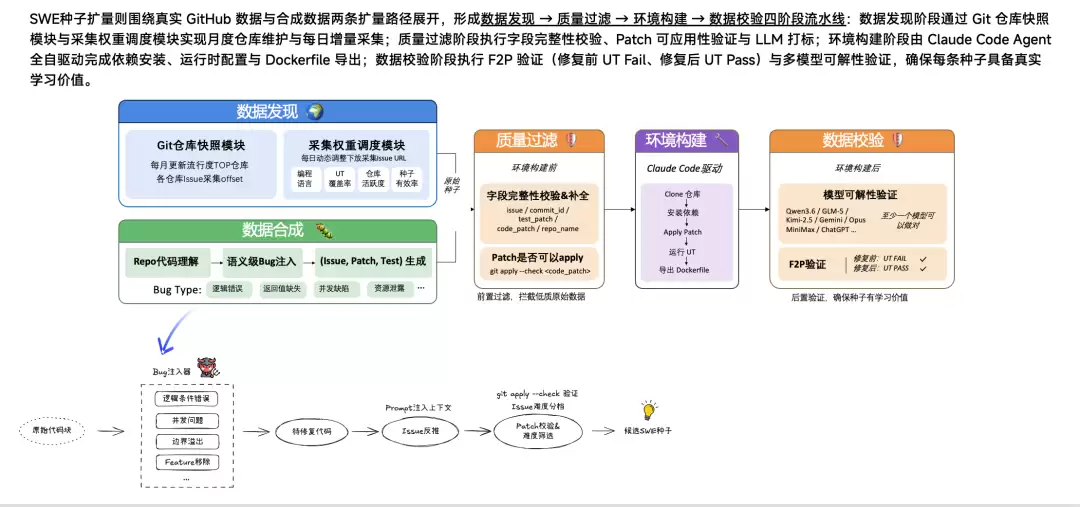
转换过程涉及几个关键步骤:先搭建一个能运行测试用例的隔离环境,也就是Docker镜像;然后验证测试用例的有效性——没应用PR时测试用例应该失败,应用了PR就应该通过。这就是从真实世界提取数据的基本流程。
合成轨迹生成
第二种方法是合成。通过修改现有的代码仓库,通常采用"注入Bug"的方式。比如修改函数里的条件判断逻辑,或者直接删除部分核心代码。这样构造出有缺陷的Bug,再让模型去修复,完成SWE中种子数据的合成。
当然,这只是个引子。不同领域的种子数据构建方法差异很大。比如做PPT自动生成,必须基于特定场景来构建数据——"投资研究报告"和"软件架构汇报",场景不同,构建逻辑完全不同。所以得先锁定具体场景,再根据场景合成种子数据及相应的解决轨迹,才能达到理想效果。
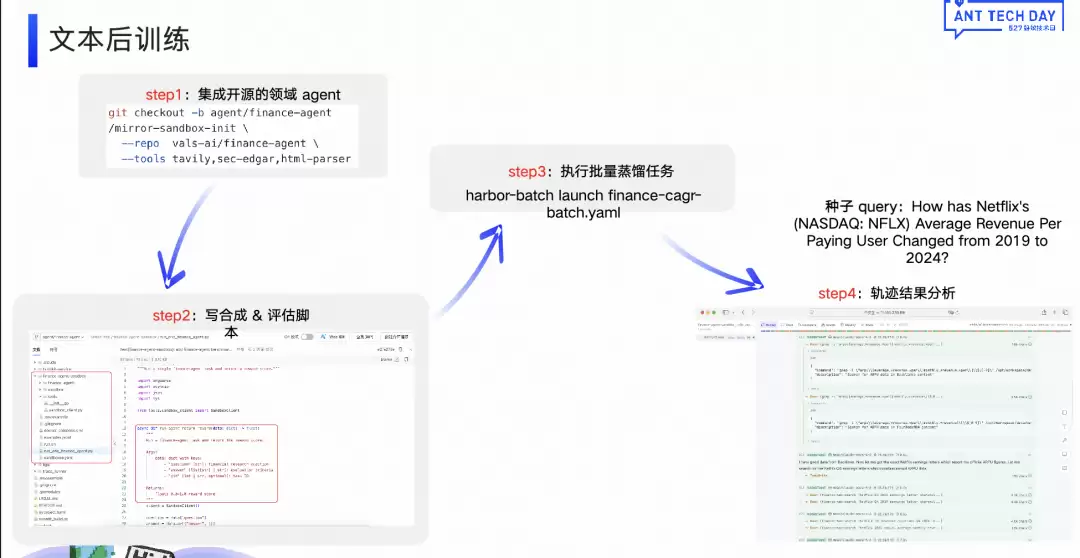
拿到种子数据后,通过以下四步合成完整的解决轨迹:首先集成开源的领域Agent(比如金融场景可以集成一个finance Agent库);然后编写合成和评估脚本——合成脚本负责策略,评估脚本判断效果;第三步开始执行任务;最后对轨迹结果进行分析,包括Agent解决问题的完整过程。
二、多模态数据处理
多模态数据处理主要分图像和音频两部分。视频可以归到图像理解范畴,因为视频可以抽帧成图片来理解。图像处理方面,主要可以拆成三块:VQA、图像分类和图像检索。
2.1 VQA
VQA就是给定一张图片,针对这张图片提出一个问题,给出答案。

VQA数据生成主要有两种方式。一种是直接构建一个查询,用这个查询去请求搜索引擎,让它返回相关图片,这样就拿到了查询和图片的配对。另一种是从原始语料中提取图片,直接进行合成——已有图片的情况下,把图片输入到能力更强的模型里,让它生成对应的问题和答案。
2.2 Caption
Caption和VQA不同。Caption是让模型对一张图片进行描述。也可以基于同一张图片提出多个问题,比如"这张图片里有什么?""这张图片属于什么场景?"通过这种方式,一张图就能生成多个问题。但Caption的问题设置通常比较固定,核心要求就是清晰简洁地描述图片,只不过问题可能有些细微变化,比如要求特别关注细节。
下面这张图是我们针对原始图片合成的Caption。它描述了主体(密集的鱼群)、环境信息(水质、倒影),还包含了视觉细节(岸边植被、光影分布)。Caption数据里,对同一张图像提供的细节越丰富、越准确,模型在处理类似图片时就能给出更精确的理解。

Q:以清晰简洁的方式描述图像。

2.3 Interleave
Interleave指的是文本和图片按上下文顺序交替出现的数据。目的是让模型在面对图文交错的情境时,更好地理解整个事件的发展过程。
实际上,互联网上的网页、PDF文档、公众号文章,本身就是图文交错的排版。人类在排版时,文字和图片的相对位置包含了大量"隐式语义信息"。解释一个知识点时附带一张图片,能加深理解。我们希望模型也能这样学习——不只是看文字,还要理解文字之外的图片等各种信息。
2.4 音频数据处理
音频数据处理跟图片有相似也有不同。图片有VQA,音频也有AQA(Audio Question Answering),本质就是把图片换成一段音频,针对音频提问题。音频数据里也存在类似Interleave和Caption的处理方式。
生产方式差异不大,但数据来源和质量评判标准截然不同。图片更关注画质、清晰度和信息丰富度;音频就复杂多了——方言、语言类型、音乐流派、曲风、演唱者的情感变化,这些特征都得提取出来,用于后续的数据筛选。
三、数据工程处理基建
面对万亿规模的数据处理挑战,我们在存储层面采用了OSS和ODPS组合的策略。非结构化数据(音频、视频、图片等)直接存在对象存储OSS里,对应的元数据(OSS链接和各种特征)存在ODPS中。目前正在向Paimon湖存储架构演进,把现有的非结构化和结构化数据统一迁过去,实现存储体系升级。
同时可以用统一宽表体系做非结构化数据的身份标识和特征管理。核心逻辑是:给每个采集或采购来的非结构化数据分配一个全局唯一的UID,然后围绕这个UID做特征提取和关联整合。
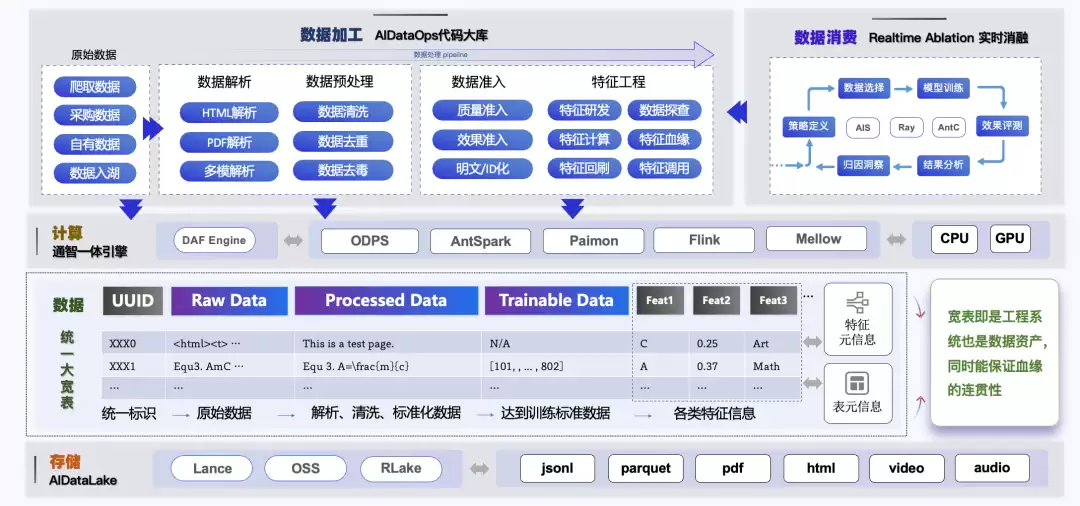
前面介绍的数据加工体系里,最关键的是代码大库。目前库里有四百多个算子,是过去一两年积累下来的,覆盖多种类型,能被各个引擎直接消费复用。CPU算子已经支持ODPS、AntSpark等多种执行引擎,GPU算子也能在多个引擎上跑数据处理任务。
3.1 Agentic Data Pipeline
Agentic Data Pipeline是基于智能体的数据处理流水线。目标是改变过去人工处理数据的模式——通过开发"数据处理算子"并引入Agent,你只需要指定数据处理目标,Agent就会调用AI模型对数据进行加工处理。
举个例子。有一个传统方式很难处理的金融逻辑题,涉及复杂的金融公式来计算违约概率。原样本给的答案是0.001,但引入Agent后,Agent直接为这道题写了一段Python代码,运行后得到的正确答案是7.63×10⁻⁸。这个案例说明,借助当前AI的能力,很多过去无法有效处理的低质量或错误数据样本,现在可以自动识别和剔除,大大提升数据集的整体可靠性。

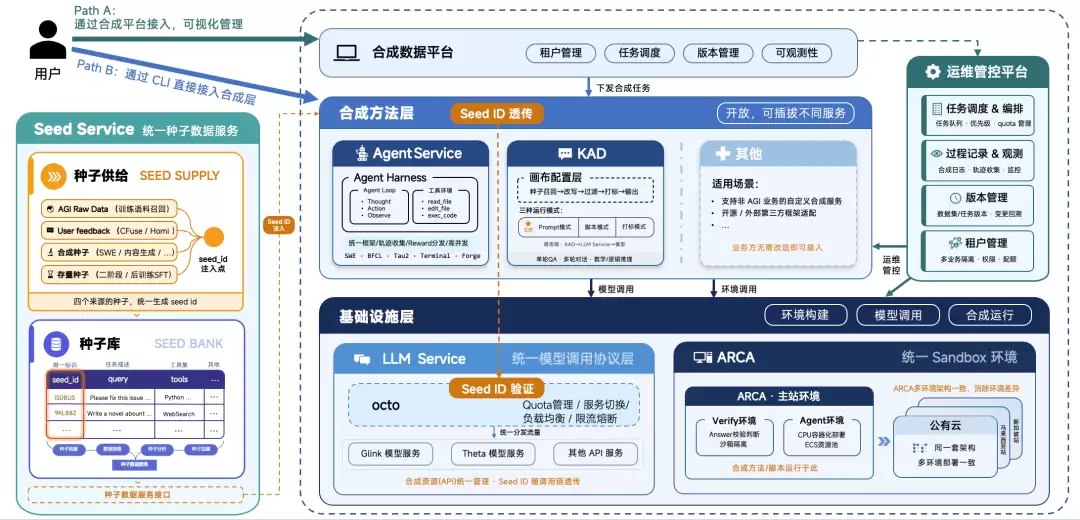
3.2 后训练数据生产平台
至于Data SQL项目,前面提到数据生产涉及种子生产、轨迹合成等环节。今年我们对平台做了几个重点升级:
第一,建立统一的种子库,把所有查询统一管理,为各业务线提供服务。第二,框架集成,让整个框架能直接消费种子数据服务。第三,统一资源网关,整合现有的合成相关通道和其他API,实现合成资源的高效管理。
通过这些升级,目标是打造一个更好用、更高效的"后训练数据生产平台"。
四、总结
回头看,大模型时代的数据生产不再只是"收集更多数据"那么简单,而是要围绕训练目标建立起可验证、可回流、可迭代的数据质量体系。
对预训练数据来说,关键是从海量非结构化数据中筛出高质量、高覆盖、低风险的语料。对后训练数据来说,关键是构建高价值任务、可靠答案和可验证的推理轨迹。对多模态数据来说,关键是让模型建立文本、图像、音频和上下文之间的关联。
随着Agent、自动评估和湖式存储等能力的逐步成熟,非结构化数据生产正在从过去的人工密集型流程,演进为一个更自动化、平台化、智能化的数据工程体系。
