
AI可观测性:Prompt、Tool Call、Trace、Token全链路追踪
先说一个让人头疼的场景:AI系统好不容易上线了,用户反馈“有时候好用,有时候不好用”。等你想排查问题时,瞬间陷入四个不知道——不知道Prompt是什么,没记录;不知道调了哪些工具,没日志;不知道完整调用链路,黑盒一个;不知道花了多少Token,月底看账单才傻眼。
这不是个别现象,这是2026年大多数AI系统的真实写照。传统软件有成熟的APM监控、日志、指标和链路追踪,但AI系统——尤其是基于大语言模型的应用——有其独特的复杂性:同样的输入可能产生不同的输出,一个用户请求能触发十几次LLM调用,Agent还会调用外部API、数据库、搜索引擎,Token消耗和API费用更是难以预估。
所以,AI可观测性这件事,不是锦上添花,而是刚需。
什么是AI可观测性?
AI可观测性不是简单的日志记录,而是理解AI系统内部状态和行为的完整能力。打个比方:传统APM监控的是HTTP请求到数据库查询再到响应,而AI可观测性追踪的是用户输入到Prompt到LLM调用到Tool Call再到多轮推理和最终输出。两件事完全不在一个复杂度层级上。
AI可观测性有四个核心维度,一个都不能少——缺任何一个,你的AI系统就是个昂贵的黑盒:
- Prompt追踪:记录和追踪所有Prompt,包括动态生成的
- Tool Call追踪:监控Agent调用的所有外部工具
- Trace链路追踪:完整的调用链路,从输入到输出
- Token追踪:Token消耗、成本和延迟的实时监控
维度1:Prompt追踪——你的AI在“想”什么?
为什么Prompt追踪如此重要?
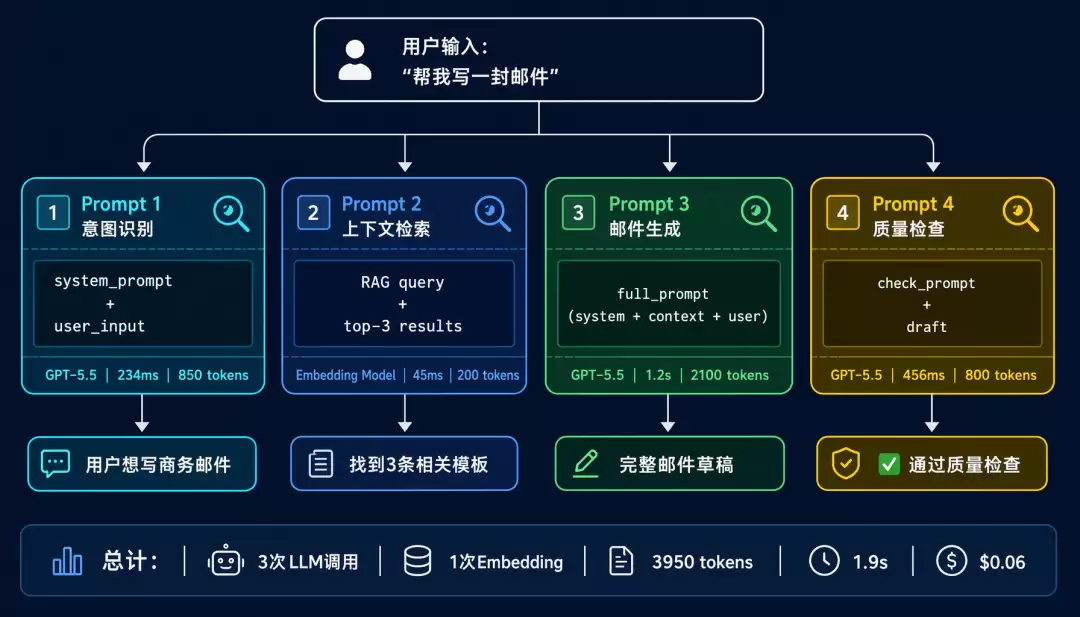
一个典型的AI应用,一次用户请求可能生成多个Prompt。举个具体的例子:用户说“帮我写一封邮件”,背后可能发生的流程是这样的:
用户输入 → Prompt 1(意图识别,判断用户想做什么)→ Prompt 2(上下文检索,从知识库找相关信息)→ Prompt 3(邮件生成)→ Prompt 4(质量检查)→ 最终输出
如果最终输出的邮件有问题,你怎么定位是哪个Prompt出了问题?没有Prompt追踪,只能靠猜;有了它,数据说话。
Prompt追踪的核心要素
每个Prompt应该记录的信息相当丰富,包括唯一标识、时间戳、所属的Trace ID、系统Prompt、用户输入、最终发给LLM的完整Prompt、模型名称、参数、响应内容、完成原因、延迟、Token数量,还有用户ID、会话ID、功能标记等业务上下文。简单说,能记录的都记录下来,越全越好。
实战:用Langfuse实现Prompt追踪
Langfuse是目前最流行的开源AI可观测性平台。下面是一个完整的示例,展示了如何在代码中嵌入追踪逻辑:
from langfuse import Langfuse
from openai import OpenAI
langfuse = Langfuse(
public_key="pk-lf-...",
secret_key="sk-lf-...",
host="https://cloud.langfuse.com"
)
openai = OpenAI()
def generate_email(user_input: str, user_id: str):
trace = langfuse.trace(
name="email_generation",
user_id=user_id,
metadata={"source": "web"}
)
span1 = trace.span(name="intent_detection")
intent_prompt = f"判断用户意图:{user_input}"
response1 = openai.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": intent_prompt}]
)
span1.end(
output=response1.choices[0].message.content,
metadata={
"tokens_input": response1.usage.prompt_tokens,
"tokens_output": response1.usage.completion_tokens
}
)
intent = response1.choices[0].message.content
span2 = trace.span(name="email_drafting")
email_prompt = f"根据意图 '{intent}' 生成邮件"
response2 = openai.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": email_prompt}]
)
span2.end(
output=response2.choices[0].message.content,
metadata={
"tokens_input": response2.usage.prompt_tokens,
"tokens_output": response2.usage.completion_tokens
}
)
email = response2.choices[0].message.content
trace.update(
output=email,
metadata={"total_spans": 2}
)
return email
Prompt追踪的最佳实践
记录完整Prompt是关键——不要只记用户输入,要记最终发给LLM的全部内容,包括system prompt和few-shot示例。另外,Prompt模板要有版本号,方便追踪哪个版本效果好;A/B测试的分组信息要记在metadata里;用户输入如果有个人信息,记得脱敏再记录。
维度2:Tool Call追踪——你的Agent在“做”什么?
Agent的工具调用链
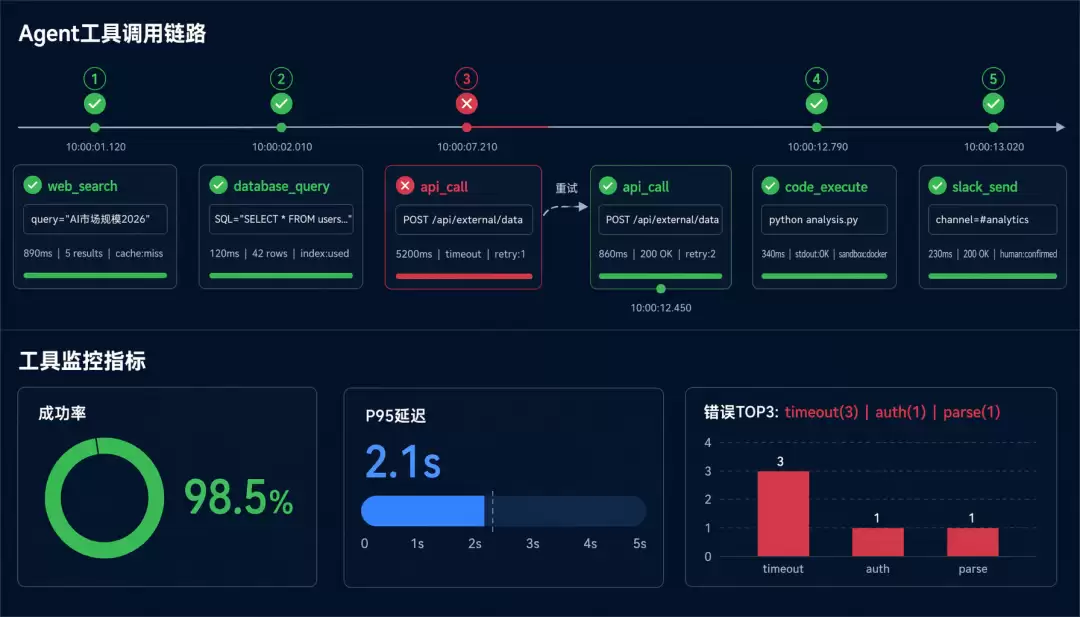
到了2026年,AI Agent早就不是简单的问答机器了。它们会搜索互联网获取实时信息,调用API查询数据库,执行代码做计算,甚至操作浏览器完成复杂任务。一个Agent任务可能调用5到20个工具,没有追踪,你根本不知道它在后台折腾什么。
Tool Call追踪需要记录的内容包括工具名称、版本号、调用参数、响应结果、延迟、重试次数、错误信息,还有缓存命中率和是否被限流等细节。
下面是一个用装饰器自动追踪工具调用的示例:
from langfuse import Langfuse
from typing import Callable, Any
langfuse = Langfuse()
def tracked_tool_call(trace, tool_name: str, func: Callable, **kwargs):
span = trace.span(
name=f"tool_call:{tool_name}",
input=kwargs
)
try:
result = func(**kwargs)
span.end(
output=result,
metadata={"success": True}
)
return result
except Exception as e:
span.end(
output=None,
metadata={
"success": False,
"error_type": type(e).__name__,
"error_message": str(e)
}
)
raise
def search_web(query: str, num_results: int = 5):
return {"results": [...], "count": num_results}
trace = langfuse.trace(name="research_agent")
results = tracked_tool_call(
trace,
"web_search",
search_web,
query="AI market size 2026",
num_results=5
)
工具调用的常见陷阱
| 陷阱 | 表现 | 解决方案 |
|---|---|---|
| 工具超时 | Agent卡在某个工具调用 | 设置超时 + 重试机制 |
| 工具幻觉 | Agent调用不存在的工具 | 工具注册表 + 严格校验 |
| 工具滥用 | 简单任务调用过多工具 | 优化工具选择逻辑 |
| 工具依赖 | 工具A失败导致工具B也失败 | 记录依赖关系 + 级联错误处理 |
维度3:Trace链路追踪——完整的“故事线”
什么是Trace?
Trace是一次完整用户请求的全部调用链路。传统软件里,一个HTTP请求可能经过多个微服务调用和数据库查询才返回响应;在AI系统里,一个用户输入可能触发多个Prompt、多次LLM调用、多个Tool Call才能输出最终结果。Trace让你看到完整的故事线,而不是零散的片段。
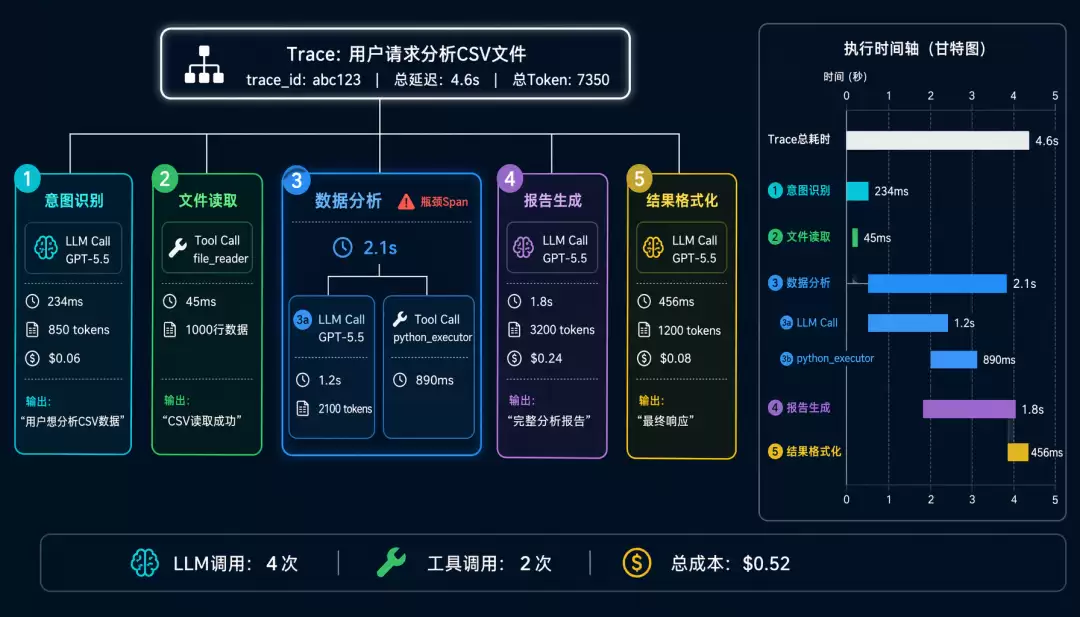
一个典型的Trace层级结构大概长这样:
用户请求“帮我分析这个CSV文件” → Span1(意图识别,含一次LLM调用)→ Span2(文件读取,一次Tool Call)→ Span3(数据分析,含一次LLM调用和一次代码执行)→ Span4(报告生成)→ Span5(结果格式化)。算下来,这单次请求就用了4次LLM调用和2次工具调用,总延时4.6秒,消耗了7350个Token。
Trace的核心价值
用户说“响应太慢”,Trace能告诉你慢在哪个环节;发现某个Span耗时最长,就能针对性优化。成本分析方面,每次请求花了多少Token、哪些Prompt最贵,数据清清楚楚。还可以对比成功和失败的Trace,找出差异所在。
维度4:Token追踪——你的AI花了多少钱?
为什么Token追踪如此重要?
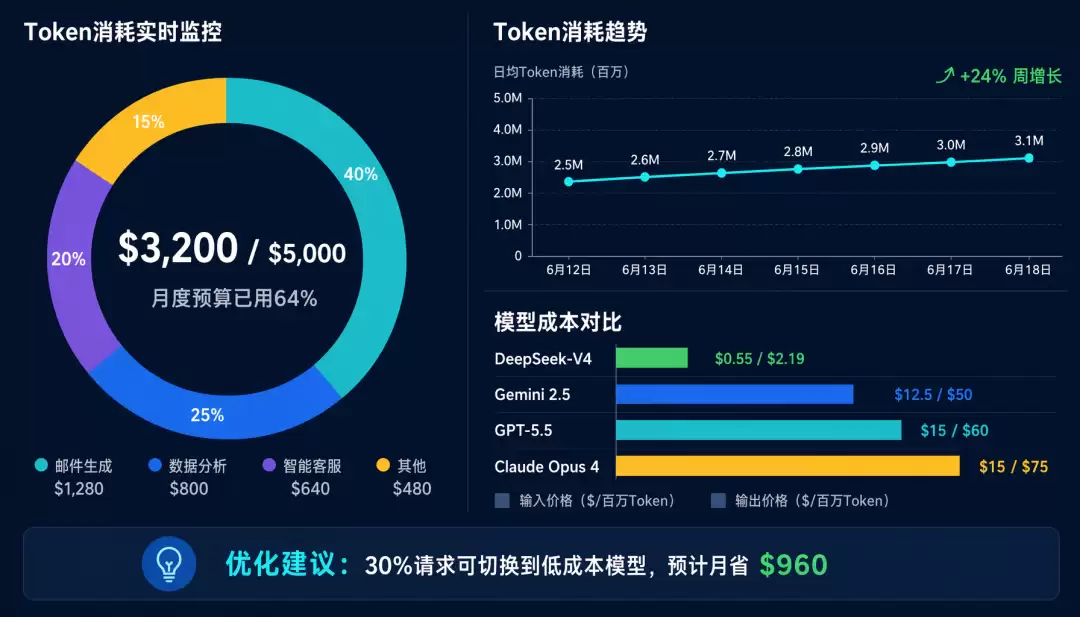
看看2026年各大模型的价格就知道了。GPT-5.5的输入价格是每百万Token 15美元,输出是60美元;Claude Opus 4的输出更是到了75美元;DeepSeek-V4相对便宜,输入只要0.55美元。一个复杂的Agent任务可能轻松消耗一万以上的Token,成本在0.5到1美元。如果你的系统日处理一万个请求,用低成本模型每天50到100美元,用高成本模型直接飙到5000到10000美元。
没有Token追踪,你只能月底看账单傻眼。有了它,实时监控、预警、优化,一套全搞定。
完整的AI可观测性架构
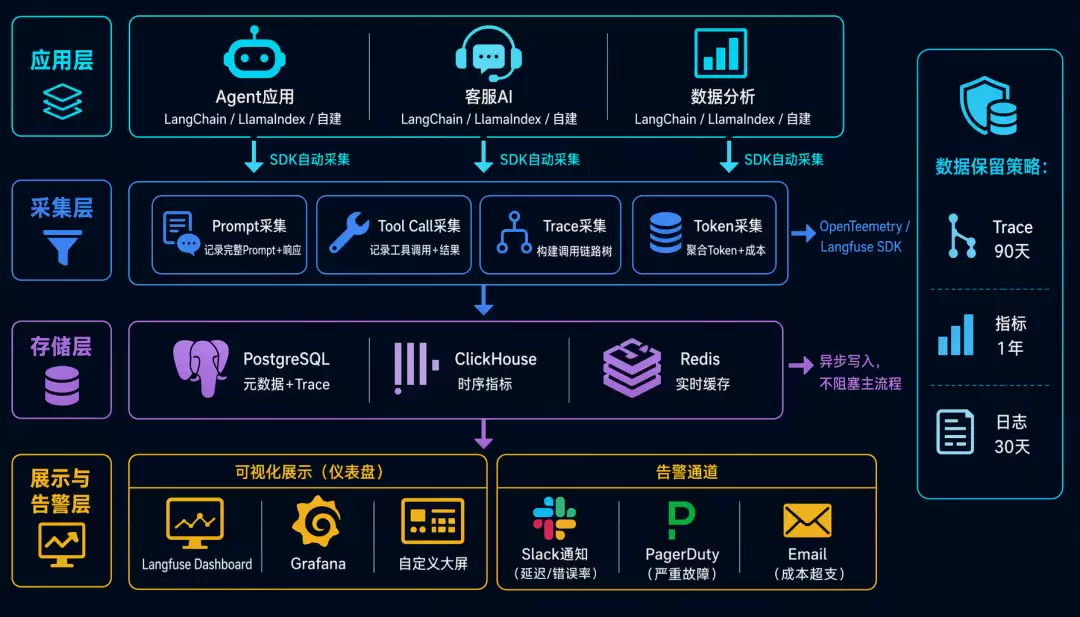
这四个维度怎么整合?用户请求进来,Trace链路追踪贯穿始终。每个Span里,Prompt追踪记录完整Prompt和LLM调用,Tool Call追踪记录工具调用和执行结果,Token追踪聚合所有Span的Token消耗。一线贯穿,环环相扣。
技术栈方面,开源方案首推Langfuse(支持全维度,集成容易,适合中小团队),另一条路是用OpenTelemetry加上自定义方案。商业方案有LangSmith(与LangChain深度集成,调试和评估功能强)和Helicone(专注LLM监控,成本追踪做得不错)。
实战案例:一个完整的可观测性改造
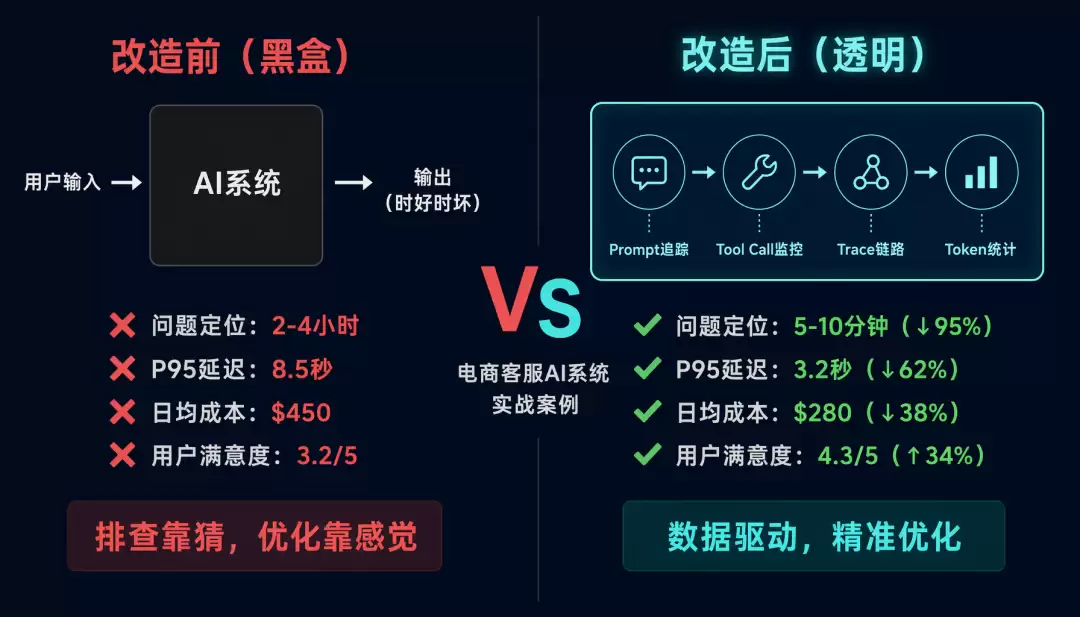
用一个电商客服AI系统的改造来感受一下实际效果。改造前的问题非常典型:没有Prompt追踪,没有Tool Call追踪,没有Trace,没有Token追踪。改造方案就是接入Langfuse,加上自定义追踪,再构建监控仪表盘。
结果相当惊人:问题定位时间从2到4小时降到了5到10分钟,P95延迟从8.5秒降到3.2秒,日均成本从450美元降到280美元,用户满意度从3.2分升到4.3分。关键发现包括:某个Tool Call(查询订单系统)的P95延迟本来是4.2秒,优化后降到0.8秒;Prompt模板里的few-shot示例过时了,更新后准确率提升25%;还有30%的请求其实可以用更便宜的处理。
最佳实践:AI可观测性的10条原则

总结一下:从第一天就接入可观测性,不要等上线后再补。追踪一切但要有重点,重点关注高成本功能、高延迟环节和高错误率路径。结构化Trace,使用清晰的命名规范。记录足够的上下文,输入输出、模型参数、Token消耗、延迟、错误信息、业务上下文,一样不能少。
设置合理的告警——P95延迟大于5秒、错误率超过5%、成本超过预算80%、单次请求Token超过一万,这些都是值得关注的红线。每周定期回顾最慢的10个Trace、最贵的10个Trace和失败的Trace。建立团队的成本意识,让每个人都了解每个功能的日均成本、每个用户的平均成本和每次LLM调用的平均成本。
持续优化Prompt,基于Trace数据缩短不必要的Prompt、优化few-shot示例、调整参数。做好版本管理,Prompt模板版本、模型版本、工具版本、代码版本一个都不能漏。最后,安全与隐私是底线,脱敏敏感信息,控制数据访问权限,遵守数据保留政策。
总结:从黑盒到透明
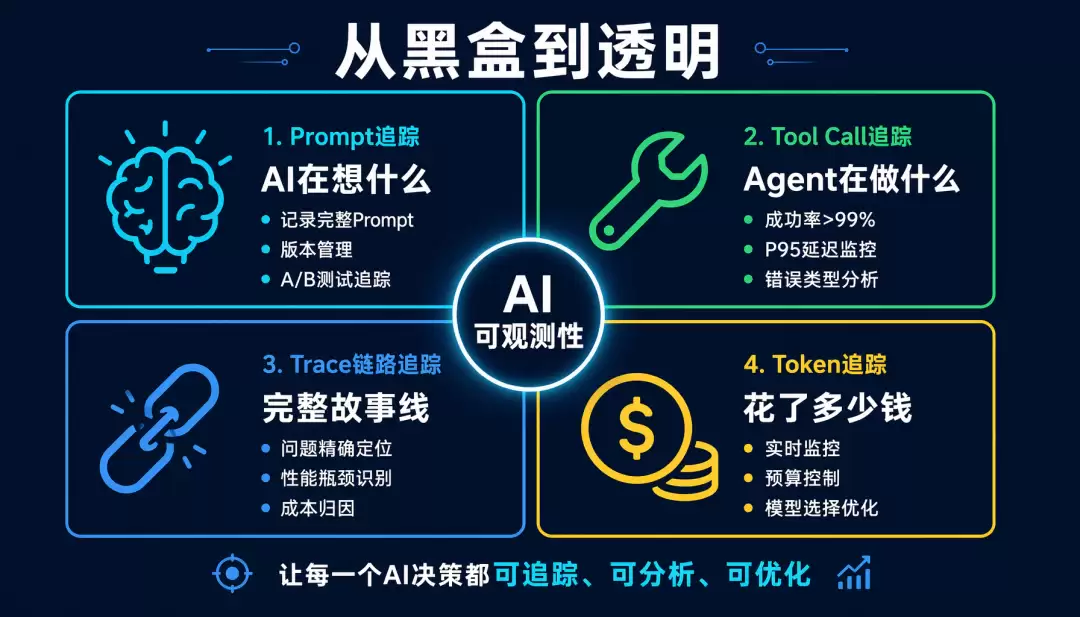
AI可观测性不是可选项,而是必选项。没有可观测性的AI系统,问题定位靠猜、性能优化靠感觉、成本控制靠月底账单、质量改进靠用户反馈。有了可观测性,问题定位靠数据、性能优化靠分析、成本控制靠实时监控、质量改进靠A/B测试。
记住这四个维度:Prompt追踪告诉你AI在想什么,Tool Call追踪告诉你Agent在做什么,Trace链路追踪给你完整的故事线,Token追踪告诉你花了多少钱。从今天开始,别让你的AI系统继续当黑盒了。
参考资料:
- Langfuse官方文档(https://langfuse.com/docs)
- LangSmith官方文档(https://docs.smith.langchain.com)
- OpenTelemetry for LLMs(https://opentelemetry.io/blog/2024/genai)
- AI Trust OS: Continuous Governance for Autonomous AI(https://arxiv.org/abs/2604.04749)
- Governance-Aware Agent Telemetry(https://arxiv.org/abs/2604.05119)
- From Confident Closing to Silent Failure(https://arxiv.org/abs/2606.09863)
