
知识库不是文件堆——我把RAG准确率从60%调到了92%
为什么RAG准确率低?问题很可能出在知识库构建环节。上周有朋友问了一个典型问题:搭了一个保险客服Agent,知识库传了200多份产品文档,但准确率只有60%出头,是不是模型不够好?我们深入聊了一下,发现关键卡点在于:一份50页的产品手册,是怎么切块的?回答是直接按PDF分页切。这就对了,准确率低的核心原因不在模型,而在知识库的构建方式。
这篇文章完整拆解了一个客服知识库从60%到92%的调优过程,涵盖三个最容易被忽视的假设、每轮调优的实测数据,以及三个必须避开的坑。

一、大多数RAG准确率低,根因不在模型,在三个假设
RAG(检索增强生成)听起来简单:把文档丢进向量库,用户提问时检索相关内容,喂给大模型回答。三步走,似乎不需要调。但这里藏着三个默认假设,每一个都可能让你翻车。
假设一:文档切得越细,检索越精准。
假设二:用户问什么,就检索什么。
假设三:检索到了,模型就能答对。
这三个假设,每一条都值得反复验证。接下来是实测数据。
二、实测:三轮调优,准确率从60%提到了92%
测试场景是一个保险客服知识库,包含3款产品条款文档、27份FAQ、12份合规话术模板——共42份文档。评测集50题,覆盖产品咨询、理赔流程、投保规则、退保计算四类场景。
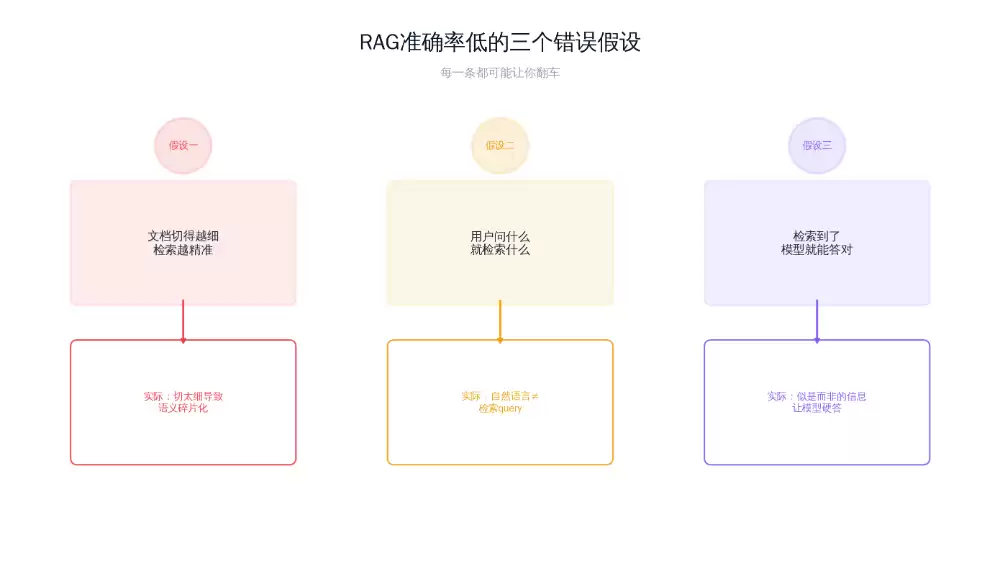
基线(Round 0):准确率60%
初始配置:固定长度分块(500字/块)、无Query改写、Top-3检索、无相似度过滤。50题中答对30题,答错20题。主要错误类型包括:
- 答非所问(8题):检索到了内容但和问题不匹配
- 信息缺失(7题):关键信息被切到另一个块里,检索没命中
- 编造内容(5题):检索到的内容不够,模型自己补了不存在的细节
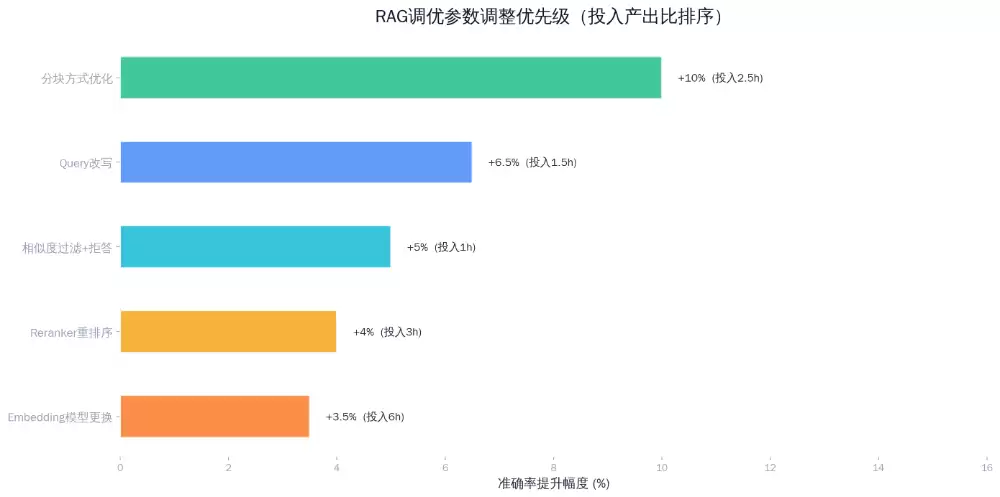
第一轮调优:分块策略改造 → 准确率72%
把固定长度分块改成"按语义段落切"。具体做法:先用段落分隔符切大块,再对超过800字的块按句子边界二次切分,保证每块是一个完整的语义单元。同时给每块加上元数据(产品名、章节标题)。效果:答非所问从8题降到3题,信息缺失从7题降到2题。准确率提升12个百分点。
第二轮调优:Query改写+相似度过滤 → 准确率85%
加了两层处理:①用LLM把用户的口语问题改写成检索友好的query;②检索结果按相似度排序后,过滤掉低于0.7阈值的结果——宁可少给,不给错的。效果:编造内容从5题降到1题(相似度过滤生效),答非所问从3题降到1题。准确率提升13个百分点。
第三轮调优:Prompt约束+不确定就不答 → 准确率92%
在生成Prompt里加了两条硬约束:①"只能基于检索到的内容回答,不得补充";②"如果检索结果和问题相关性低,回答'这个问题我需要转给人工确认'"。同时把Top-3检索改成Top-5,但要求模型只引用相似度最高的2段。效果:最后一道防线兜住了边界case。准确率提升7个百分点,达到92%。
三、三个最容易被忽略的坑
调优过程中,有三个坑反复出现:
坑一:只看准确率,不看错误类型。
坑二:评测集太小或太偏。
坑三:改了参数不记录基线。
四、从哪开始:三个小时就能见效的第一步
不要一上来就重构整个知识库。选一个已经上线但准确率不满意的场景,做三件事:
- 建一套30题的评测集(用真实用户问题,人工标答案)
- 只改一个参数:把分块方式从"固定长度"改成"按语义段落切"
- 跑一遍评测,看准确率变化
这三件事大约需要3个小时。如果准确率提升了5%以上,说明知识库有明确的优化空间,值得继续投入。如果准确率没变化,那问题可能不在知识库,在Embedding模型和你的内容类型不匹配,需要往下查。
五、写在最后
知识库建设有一个反直觉的真相:文档越多,准确率不一定越高。关键是文档怎么切、检索怎么组织、回答怎么约束。
从60%到92%的提升过程中,技术上没有用到任何高深的东西——分块策略、Query改写、相似度过滤、Prompt约束,全是公开的工具和方法。区别在于:有没有一个评测闭环,可以知道每一步改了之后到底有没有变好。
如果正在搭建知识库,或者已经搭了但准确率不满意,可以问自己三个问题:
- 文档是怎么切的——按页、按字数、还是按语义?
- 有没有一套30题以上的评测集?
- RAG有没有"不确定就不答"的机制?
三个问题有一个回答"否",准确率就有明确的提升空间。

本文基于在保险客服场景下的RAG知识库调优实践。评测数据为50题封闭测试集结果,不同场景、不同知识库内容类型、不同模型的准确率可能存在差异。文中数据已做脱敏处理。RAG方案因业务场景和技术栈不同需要适配调整。
