
告别拖拽做工作流:两个Skill让Dify应用全流程自动化
用自然语言描述需求,自动生成Dify工作流并直接部署,告别繁琐的拖拽操作
大多数人搭Dify工作流,还在这么干:打开网页,拖节点,连线,填参数,测试,导出备份。需求一变,再拖一遍。领导不满意,再改一遍。整个过程又慢又容易出错,尤其是复杂业务场景,拖拽体验简直雪上加霜。
我做了两个Claude Code Skill——
dify-workflow
dify-deploy
DSL 是什么?为什么自动生成比拖拽快?
Dify 的工作流本质上是一个 YAML 格式的配置文件,叫
DSL
手动拖拽的问题很明显:你在跟一个可视化编辑器交互,每改一个参数都要点开节点面板、找到字段、填写、保存。而
自动生成 DSL,是让模型直接输出这个配置文件
但只生成 DSL 还不够。生成完了还得手动导入到 Dify,还是得开网页、点按钮。
dify-deploy 补上了这一步
不只是快速原型,复杂设计也能搞定
很多人对"AI 生成工作流"的预期是:只能做简单的线性流程,稍微复杂一点就搞不定。这两个 Skill 的设计目标不是这样——
简单任务要快,复杂任务要准
简单任务:模板直接套,几分钟出活
SKILL.md 内置了 4 个常用模板:
Chatbot
RAG
Agent
Translation
比如领导说"做个聊天机器人",直接套 Chatbot 模板——Start → LLM → Answer,三个节点,改一下模型名称和 prompt,几分钟生成完部署好。
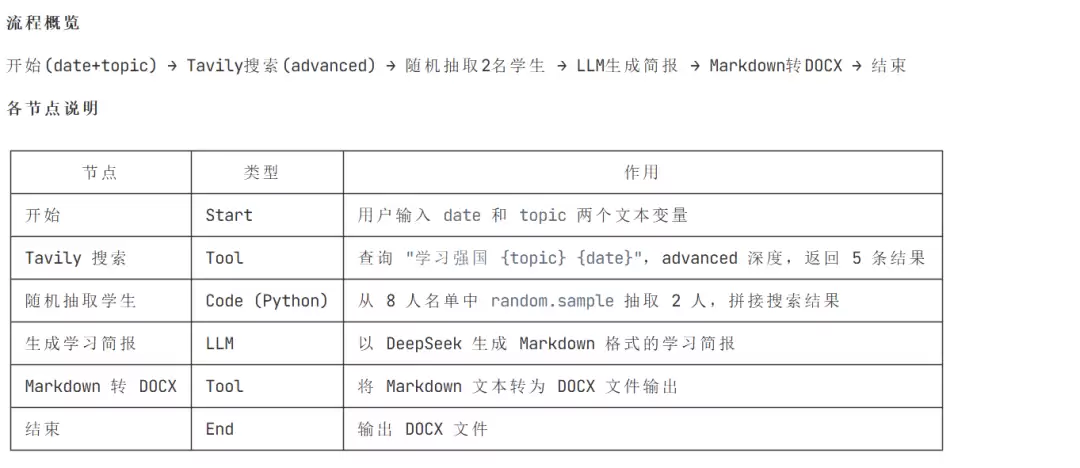
下面这个会议总结工作流,需求用流程图方式描述,涉及参数提取、HTTP 搜索、随机抽取、LLM 生成、插件调用等多种节点类型,
Skill 一次生成完成
帮我生成 dify 应用,其主要流程如下:用户输入(日期+主题)→ 提取 date/content → Ta vily 搜索(学习强国,advanced 深度,使用 Ta vily 插件)→ 提取搜索结果内容 → 从固定列表(先填入8个假名字)中随机抽取 2 名同学 → LLM 生成报告(主题+搜索结果+学生姓名)→ Markdown 转 DOCX(使用 Markdown to Word 插件)→ 输出 DOCX 文件
需求明确,Skill 直接从节点路由表匹配类型、从 Schema 文档组装字段,不需要追问,同意设计稿后几分钟出结果。
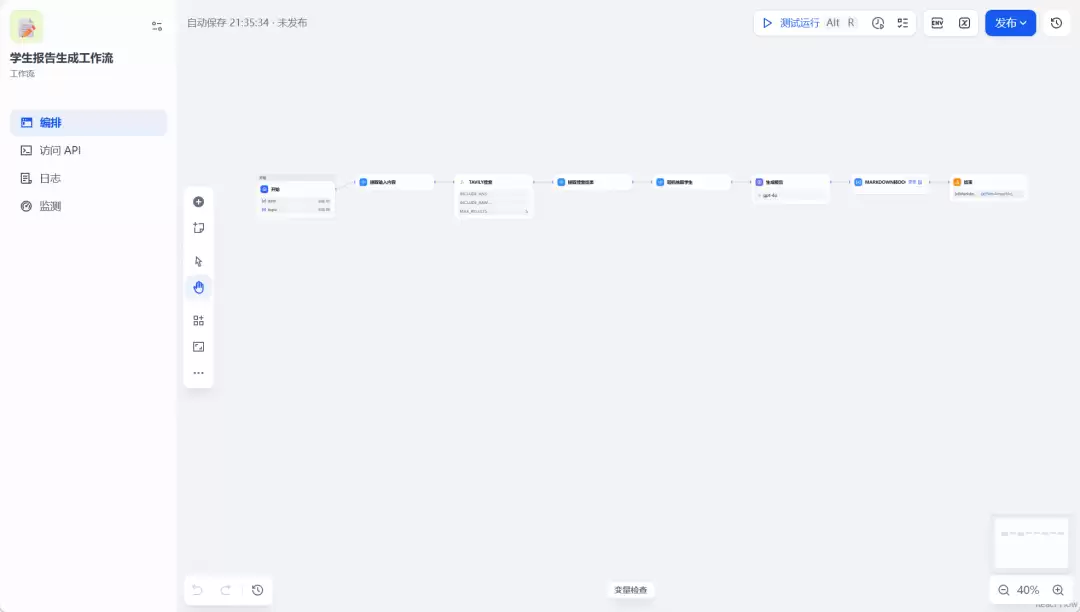
这里简单套了个前端,大家可以体验一下:meetsum.311factory.top/
复杂任务:逐节点查阅 Schema,精准组装
当需求复杂到一定程度——多分支、多模型、多接口调用、异常处理——Skill 会逐节点查阅 references/nodes/ 目录下的
15 种节点文档
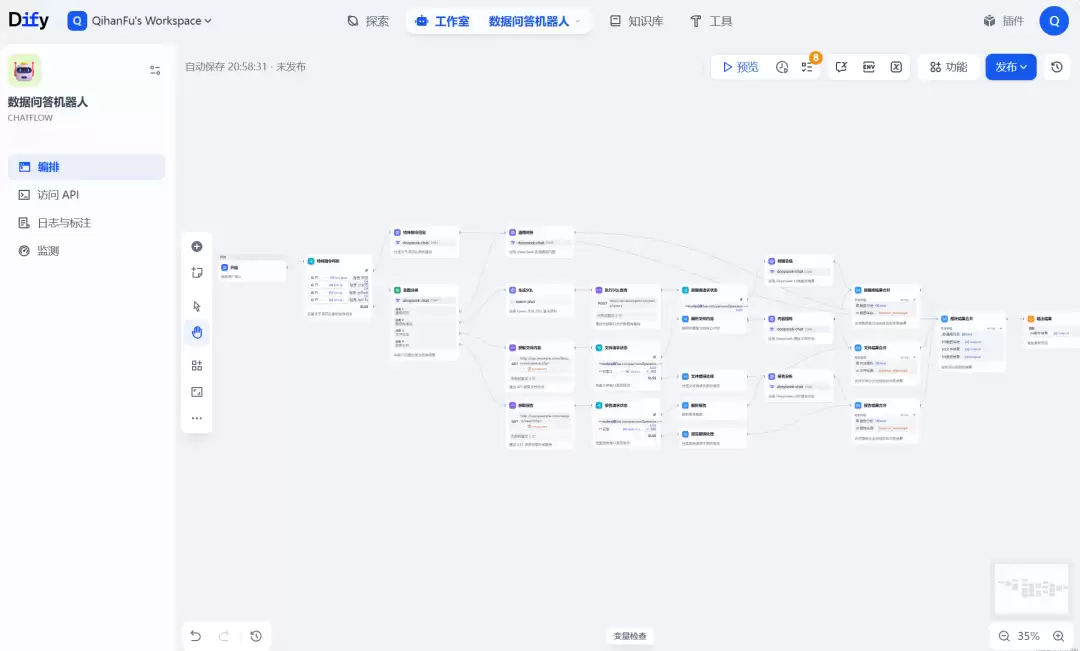
下面这个知识库问答工作流,全程用大白话描述,需求里包含条件分支、意图分类、HTTP 请求、状态码检查、多模型调用,
Skill 逐条拆解、逐节点组装
写一个 Dify 数据问答机器人的 DSL 配置,模型主要调用 DeepSeek 和 Qwen。流程从一开始先加个条件判断拦截特殊指令进行直接回复,其余进入核心的意图分类节点。意图需划分为通用、数据库、文件和报告四种场景。通用场景直接过 DeepSeek 生成结果并输出。数据库场景先让 Qwen 写 SQL,通过 POST 请求调用内部接口查数据,接着判断 HTTP 状态码,成功则解析数据给大模型做总结,异常走失败分支。文件场景根据具体需求分流,通过 API 提取文档内容后进行大篇幅文本提炼。报告场景利用 GET 请求获取外部报告,解析状态后输出最终分析结论。所有涉及接口调用的地方都要配上状态码检查来处理网络异常。
这段需求涉及的节点类型:If/Else 做条件拦截、Question Classifier 做意图分类(4 种类别)、HTTP Request 调接口、Code 节点解析数据、LLM 调用 DeepSeek 和 Qwen、Answer 输出结果。
Skill 没有急着出原型,而是先给出自己的设计方案,并主动引导你澄清需求:
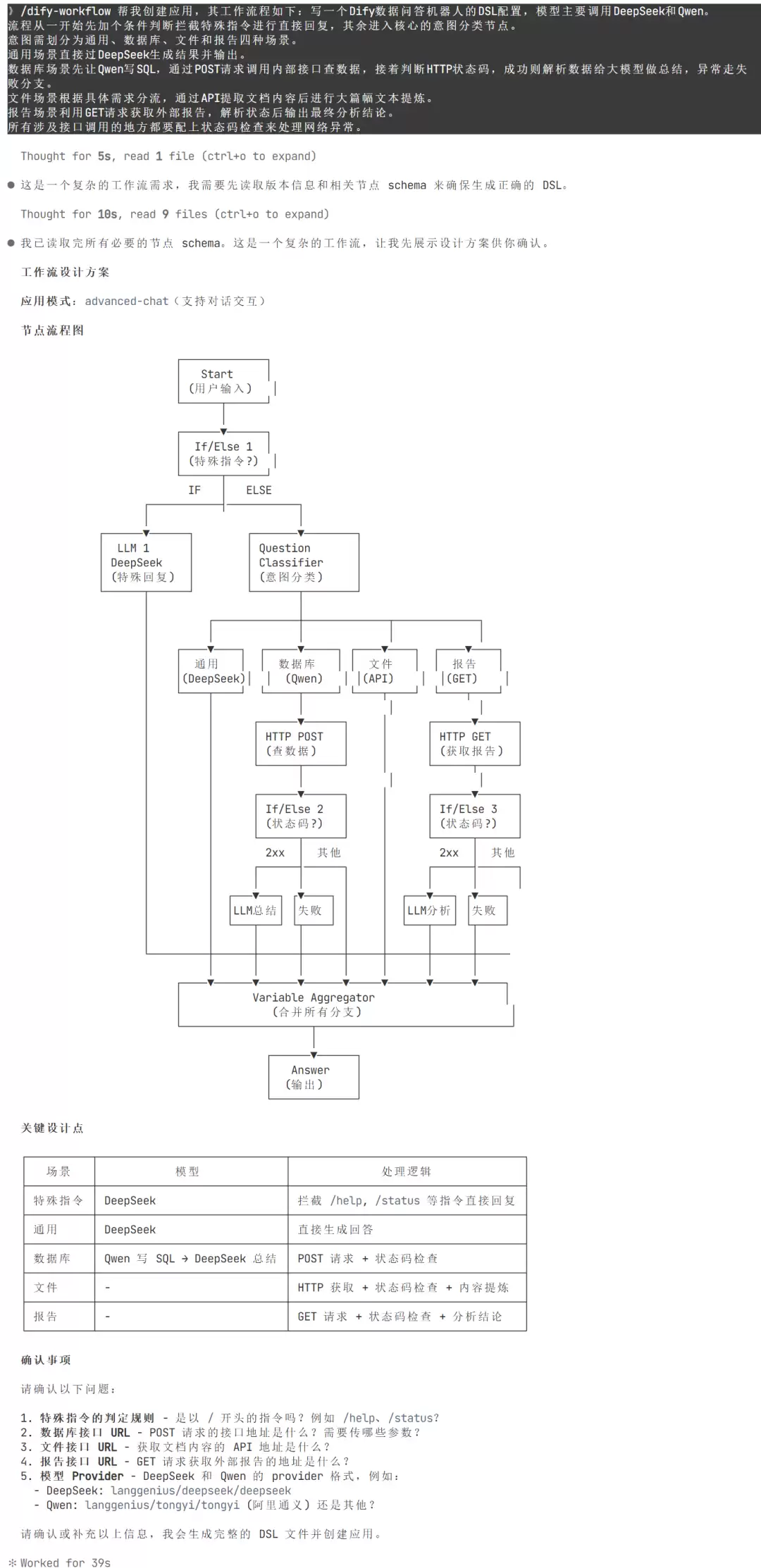
在你确认设计方案无误,并补充完毕信息后,Skill 开始逐节点查阅 Schema,检查每个字段的约束——比如 Question Classifier 的 classes 最少 2 个、HTTP Request 的 body 类型要跟 Content-Type 匹配、If/Else 的 sourceHandle 要区分 true/false 分支——
最终生成的 DSL 直接导入成功

需求变了?持续迭代,自动备份
工作流应用最难的不是第一次搭建,而是后续迭代。领导看完原型说"数据库场景再加个缓存判断",手动改意味着打开 Dify、找到对应节点、拖新节点、连线、改变量引用,一不小心改错了还得从备份恢复。
用 Skill 迭代的流程是:
- 描述修改需求:“在数据库场景的 HTTP 请求前加一个缓存判断节点”
- Skill 到临时目录,文件名带时间戳
自动备份旧 DSL
- 生成新 DSL,到 Dify
覆盖导入
- 导出验证,确认新版本正确
推倒重来不再白费心血
版本兼容:不怕单位 Dify 版本老
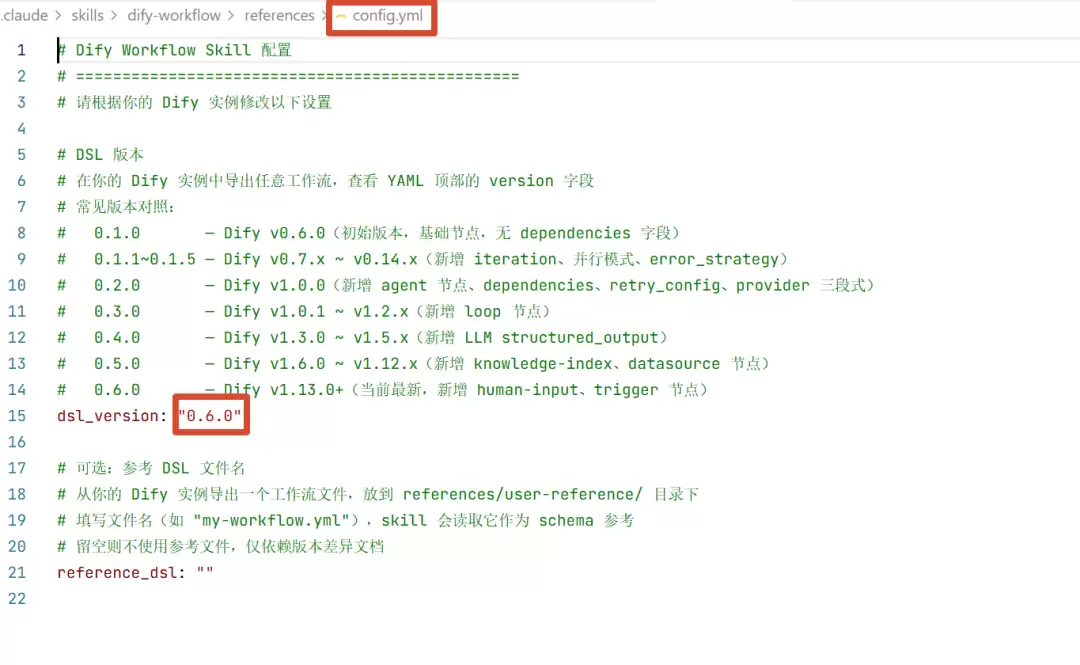
Dify 迭代快,版本碎片化严重。网课教程用的是 v0.6,单位部署的是 v0.12,网上找的模板是 v1.x——导入就报错。
dify-workflow 在 references/config.yml 中维护了一份版本对照表:
| DSL 版本 | 对应 Dify 版本 |
|---|---|
| 0.1.0 | v0.6.x ~ v0.12.x |
| 0.1.1 ~ 0.1.5 | v0.13.x ~ v0.14.x |
| 0.2.0 ~ 0.3.x | v1.0.0 ~ v1.2.x |
| 0.4.0 ~ 0.5.x | v1.3.0 ~ v1.9.x |
| 0.6.0 | v1.10.0+ |
指定版本号后,Skill 只使用该版本支持的节点类型和字段。
指定 0.1.0 就只用初始 14 种节点、单段式 provider 格式
兜底设计:按规则执行,不靠模型硬扛
dify-deploy 设置了 disable-model-invocation: true,让模型直接读取 API 返回的 JSON 内容。Skill 里写死了状态码验证规则:
| 状态码 | 含义 | 处理方式 |
|---|---|---|
201 CREATED | 应用创建成功 | 继续下一步 |
200 OK | 导出或导入完成 | 继续下一步 |
202 ACCEPTED | 导入进入 pending 状态 | 调用 confirm 接口确认 |
401 | key 配置有问题 | 检查 ADMIN_API_KEY |
Connection refused | API 地址不可达 | 检查 DIFY_BASE_URL |
模型只需要"遵守"这些规则,不需要"理解"API 设计。即使模型能力有限,只要它能按状态码执行对应动作,就能一路跑通到应用创建成功。这条设计把判断逻辑从"模型理解"降级为"规则匹配",
提高了整个流程的鲁棒性
总结
两个 Skill 配合使用的完整链路:
- 用自然语言描述需求(可以是大白话,也可以是流程图)
dify-workflow生成兼容指定版本的 DSLdify-deploy一键创建应用并导入到 Dify- 需求变了?自动备份旧版本,生成新 DSL,覆盖导入
- 中途出错?读 API 返回,按规则重试
