
Transformer作者初创重磅发布Transformer²,AI模型活了,动态调整自己权重
先说几个核心判断。大语言模型虽然能力惊人,但有一个根深蒂固的弱点:它学完知识后,就像一个“固化”了的大脑。想让它吸收哪怕一句新信息,往往都得把整个训练流程重来一遍,成本高得吓人。
而生物界的适应能力,却几乎是本能的。章鱼可以瞬间改变肤色融入环境,人类大脑在受损后能重建神经通路——“物竞天择,适者生存”并非一句空话。但落到LLM头上,怎么让它们也拥有这种“随需而变”的能力,却是个长期难题。
现在,Sakana AI的研究团队给出了一个新的解题思路,叫做
Transformer²

从技术原理上看,它打破了传统“一次训练管全部”的微调框架。我们当然希望一个模型能通吃所有任务,但现实很骨感:全面的后训练几乎意味着天文数字的计算资源,而且一旦引入更多样化的数据,过拟合和任务间的干扰就会变得非常棘手。
相比之下,“自适应模型”的思路就更灵活。与其试图让一个模型什么都会,不如给它配上一套“专家工具箱”,在需要的时候动态调用。但这里也有问题——创建多个专家模块意味着训练参数暴增,依然容易过拟合,模块之间的组合也不够灵活。
Transformer²找到了一个精巧的突破口:它不去动整个模型,而是专注于有选择性地调整权重矩阵中的关键“零件”。
Transformer²这个名字本身就解释了两步走的过程:第一步,模型“看一眼”传入的任务,理解它的需求;第二步,执行任务专用的适应性调整,输出最佳结果。在数学、编程、推理和视觉理解等多种任务上,它的表现都相当亮眼,不仅超越了LoRA这样的传统静态方法,还在效率上实现了提升——用更少的参数,达到了更好的效果。
LLM的「大脑」:权重矩阵
人类大脑通过互联的神经通路存储和处理信息。LLM的“大脑”则是权重矩阵——它从海量训练数据中提炼出的核心知识就存储在其中。
想要让这个“大脑”能灵活适应新任务,首先得弄清楚它的内部结构。而奇异值分解(SVD)恰恰提供了这扇窗口。
形象点说,SVD就像一个技术高超的外科医生,能给LLM的“大脑”做精细解剖。它将庞大复杂的知识矩阵,分解成更小、更独立、更有意义的组成部分——比如,针对数学、语言理解等不同能力的“子路径”或组件。SVD正是通过识别权重矩阵中的这些主成分来达成这一目标的。
有趣的是,研究人员发现,如果选择性地增强某些组件的信号,同时抑制另一些,就能显著提升LLM在下游任务中的表现。基于这个发现,Transformer²向前迈出了关键一步——让这种调整变得“动态”且“任务特定”,从而让LLM能在更复杂的场景里游刃有余。
引入Transformer²
Transformer²重新定义了LLM适应多样化任务的方式。它的核心,就是动态调节权重矩阵里的关键组件。
在训练阶段,它引入了
奇异值微调(SVF)
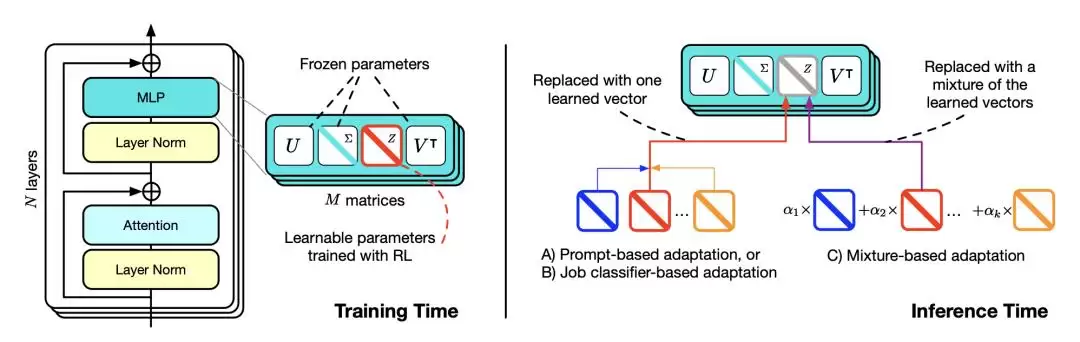
下图清晰地展示了这个框架。
左图:使用SVD将权重矩阵分解为独立组件。右图:利用RL训练这些组件的组合以应对不同任务。注意,有些组件(比如图中的紫色齿轮)在语言理解和推理任务之间是共享的。推理时,系统会先识别任务类型,然后动态调整组件的组合。
使用SVF和RL进行训练
在训练阶段,SVF会为每个下游任务学习一组
z向量
你可以把z向量理解为该任务的“专家标识”。它是一个非常紧凑的表示,指定了权重矩阵中每个组件的期望强度,相当于一个“放大器”或“衰减器”,用来调节不同组件对模型行为的影响力。
举个简单的例子:假设SVD把权重矩阵分解成了[A, B, C, D, E]这5个组件。
对于数学任务,学习到的z向量可能是[1, 0.8, 0, 0.3, 0.5]。这表明组件A对数学任务至关重要,而组件C几乎不影响它的表现。
而对于语言理解任务,z向量可能会变成[0.1, 0.3, 1, 0.7, 0.5]。这说明组件C虽然在数学任务里用处不大,但对语言理解却举足轻重。
SVF通过强化学习在预定义的任务集上学习这些z向量。这些学习到的z向量,使得Transformer²能以极小的参数代价(仅仅多训练了一些z向量),就能适应各种全新的下游任务。
自适应性
在推理阶段,框架采用了“两阶段”的适应策略。
第一阶段,给定任务或单个输入提示,Transformer²会通过下面三种方法之一来分析“测试时”的条件。第二阶段,它会结合这些z向量来调节权重,生成最适合当前场景的最终答案。
三种任务检测与适应方法如下:
- 使用专门设计的提示词,对任务进行分类(比如数学、编程),然后直接选择一个预训练好的z向量。
基于提示的适应:
- 额外训练一个任务分类器,在推理时识别任务类型,再匹配合适的z向量。
基于分类器的适应:
- 通过加权插值,组合多个预训练的z向量。一个简单的优化算法会根据模型在少量样本测试集上的表现,来自动调整这些权重。
少样本适应:
这三种方法共同确保了Transformer²既能实现强大的任务自适应,又保持了高效的推理能力。
主要结果
作者将这些方法应用在了Llama和Mistral模型上,并在广泛的任务维度进行了测试,包括数学(GSM8K、MATH)、代码(MBPP-Pro、HumanEval)、推理(ARC-Easy、ARC-Challenge)和视觉问答(TextVQA、OKVQA)。
SVF测评
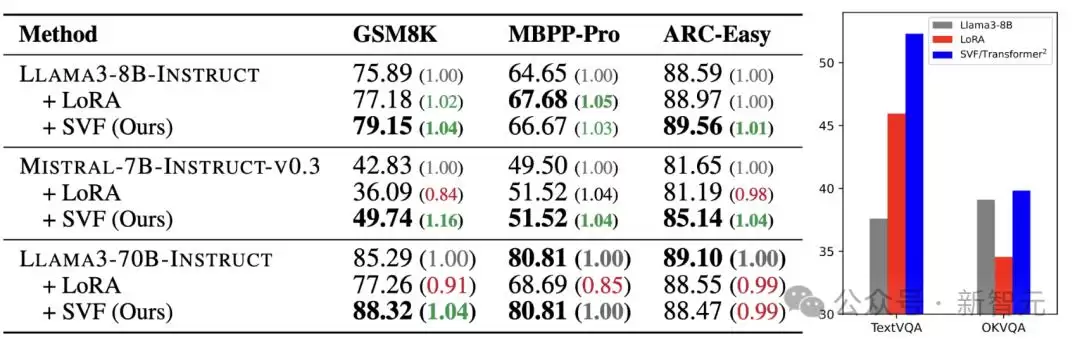
首先,研究人员用SVF在这些任务上获取了z向量,并和LoRA进行了对比。
结果很清晰:在文本任务上,SVF全面优于LoRA,尤其在GSM8K数据集上提升显著。这很可能得益于RL的训练目标——与LoRA不同,RL并不要求每个问题都有“完美解决方案”,容错空间更大。右侧的直方图也展示了SVF在视觉领域的惊人表现。
未见过的任务
接着,研究团队将Transformer²的适应框架与LoRA在“未见过的任务”上进行了对比,重点包括MATH、HumanEval和ARC-Challenge。
下表左侧展示了,随着方法复杂度的提升,新架构在所有任务上都实现了逐步的性能提升。
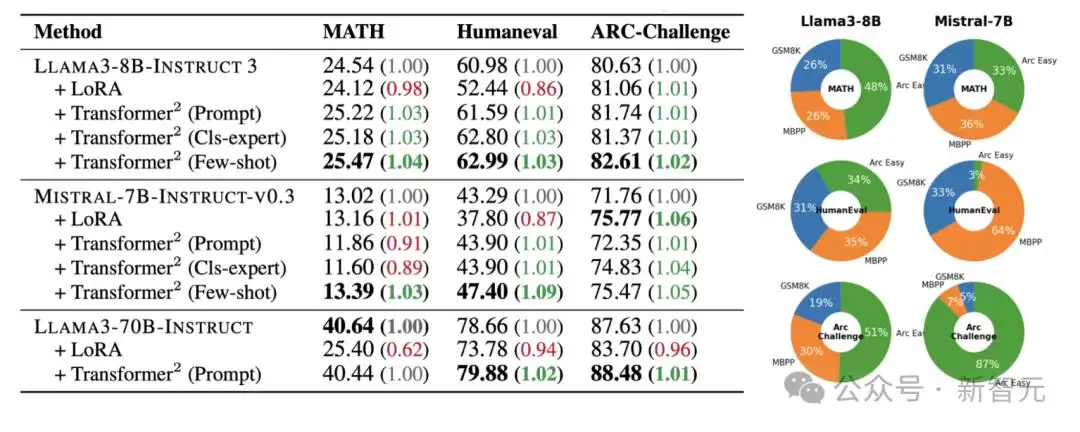
左图:在未见任务上的自适应表现。右图:学习到的z向量插值权重分析。
更有趣的是右图的发现:当模型在处理MATH这种复杂推理问题时,它并不是只依赖于为GSM8K任务专门训练的z向量。相反,它组合了数学、编程和逻辑推理等多种能力。这说明复杂的任务,确实需要模型综合不同的专业知识才能达到最佳效果。
模型知识转移
最后,作者探索了一个颇具前瞻性的问题:能否把一个模型学到的知识,转移到另一个模型里?
答案是令人兴奋的。当把Llama学到的z向量转移到Mistral上时,后者的表现在大多数任务上都有提升。当然,这背后有一个重要前提:Llama和Mistral有着相似的结构,这可能是知识能够兼容的原因。
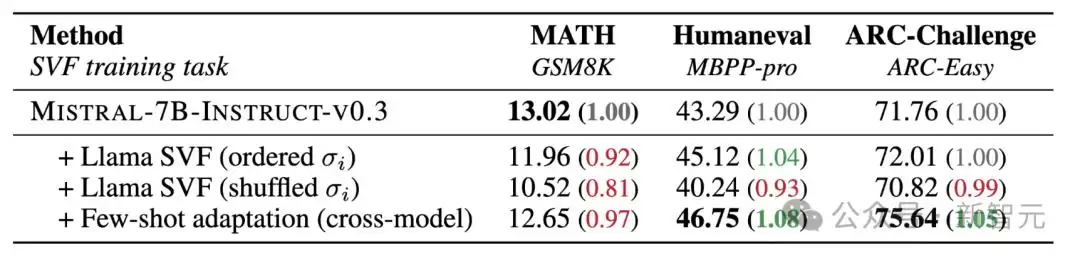
不同AI模型之间能否实现真正的知识共享,目前还悬而未决。但这些结果的确打开了一扇新的大门:特定任务技能的解耦与重用,似乎不再是天方夜谭。这为未来更大、更强的模型提供了一种全新的赋能方式。
「活体智能」
但这仅仅是开始。Transformer²为我们描绘了一个更激动人心的场景:AI系统不再是训练好就固化下来的静态实体。相反,它们开始向“活体智能”迈进——一个能不断学习、演化、适应新环境的模型。
像Transformer²这样的自适应系统,正在缩小静态AI与“活体智能”之间的鸿沟。它为更高效、更个性化、且真正能融入各个行业的AI工具铺平了道路。而这,或许才是AI走进我们日常生活的正确姿势。
