
MiniMax震撼开源,突破传统Transformer架构,4560亿参数,支持400万长上下文
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
「2025 年,每个公司都将拥有 AI 软件工程师 Agent,它们会编写大量代码。」——Meta CEO Mark Zuckerberg
「未来,每家公司的 IT 部门都将成为 AI Agent 的 HR 部门。」—— 英伟达 CEO 黄仁勋
2025 年开年,趋势尚未明朗,几位 AI 界的关键人物却不约而同地指向了同一个方向——2025 年将是 AI Agent 的元年。对于这个判断,大家应该不会感到意外。
没想到的是,MiniMax 很快就有了动作:他们开源了最新的基础语言模型 MiniMax-Text-01 以及视觉多模态模型 MiniMax-VL-01。新模型最大的亮点在于,业内首次大规模实现了全新的线性注意力机制,这让输入的上下文窗口被拉长到了惊人的 400 万 token——是其他模型的 20 到 32 倍。MiniMax 相信,这些模型将为接下来一年里 Agent 相关应用的爆发提供有力的支撑。
那么,这项工作为何对 Agent 如此关键?原因在于,随着 Agent 深入实际应用场景,无论是单个 Agent 工作时产生的记忆,还是多个 Agent 协作时产生的上下文(context),都对模型的长上下文窗口提出了更高的要求。

一系列创新,造就比肩顶尖模型的开源模型
MiniMax-Text-01 究竟是如何炼成的?从新型线性注意力到改进版的混合专家架构,再到并行策略和通信技术的优化,MiniMax 解决了一连串大模型在面对超长上下文时的效果与效率痛点。
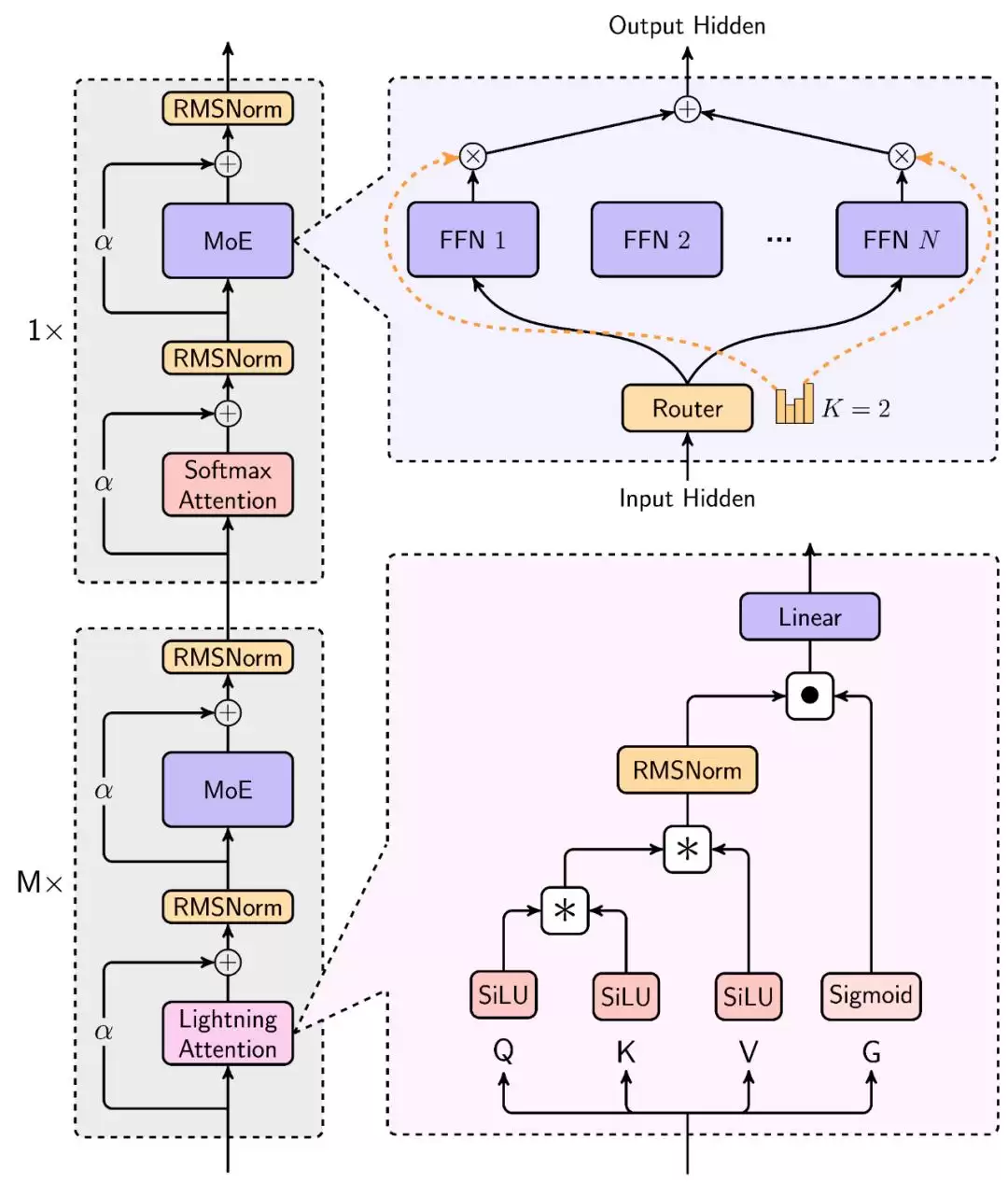
MiniMax-Text-01 的架构
Lightning Attention
当下主流的 LLM 大多基于 Transformer,而 Transformer 核心的自注意力机制是其计算成本的主要来源。为了优化,研究社区可以说是绞尽脑汁,陆续提出了稀疏注意力、低秩分解和线性注意力等众多技术。MiniMax 的 Lightning Attention 就属于线性注意力的一种。
通过使用线性注意力,原生 Transformer 的计算复杂度能从二次复杂度大幅下降到线性复杂度,如下图所示。
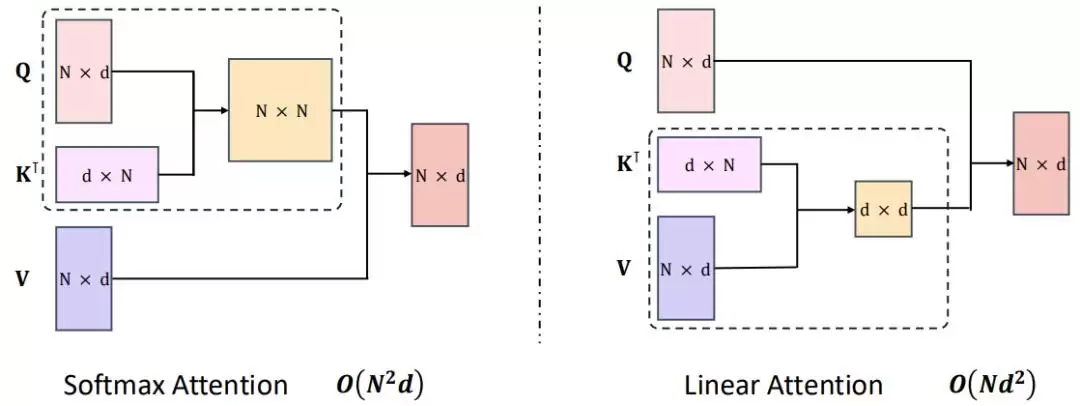
根据 MiniMax 的技术报告,这主要得益于一种“右边积核技巧”(right product kernel trick)。以 2022 年论文《The Devil in Linear Transformer》中的 TransNormer 为例,下图左侧的 NormAttention 机制可被转换成使用“右侧矩阵乘法”的线性变体。

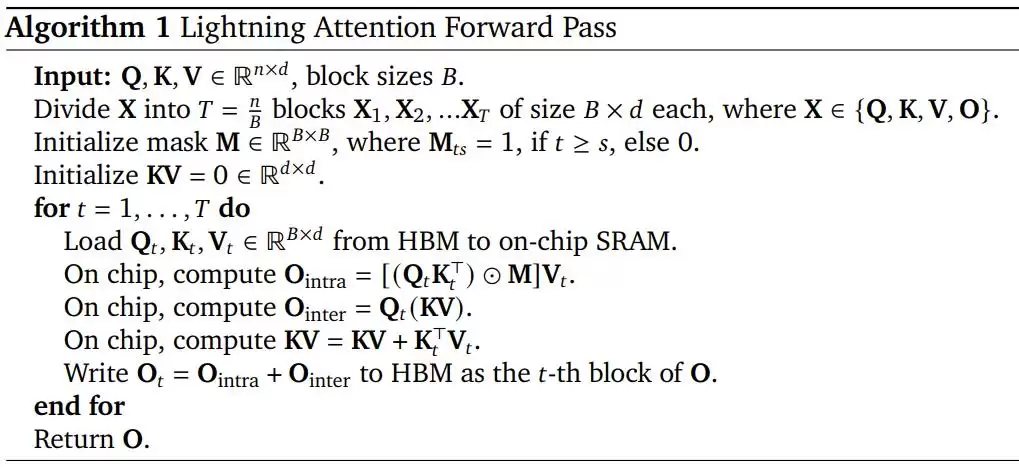
而 Lightning Attention 就是基于 TransNormer 实现的一个 I/O 感知型优化版本。其前向传递的算法描述如下。
基于 Lightning Attention,MiniMax 还提出了一个 Hybrid-lightning 方案,即每隔 8 层将 Lightning Attention 替换成 softmax 注意力。这样做,既解决了 softmax 注意力的效率问题,也提升了 Lightning Attention 的 scaling 能力。效果如何?下表给出了根据层数、模型维度、批量大小和序列长度计算注意力架构参数量与 FLOPs 的公式。可以明显看出,模型规模越大,Lightning Attention 与 Hybrid-lightning 相对于 softmax 注意力的优势就越明显。

混合专家(MoE)
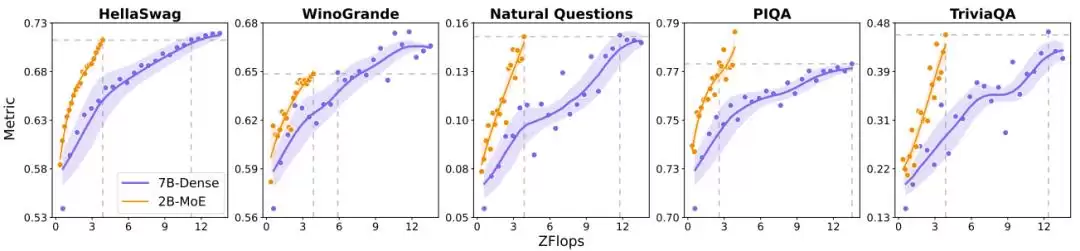
MoE 相对于密集模型的效率优势已经得到大量研究的验证。MiniMax 团队同样进行了一番对比实验,比较了一个 7B 参数的密集模型和 2B 激活参数、20B 总参数的 MoE 模型。结果如下图所示:在多种基准上,当计算负载相同时,MoE 模型的表现大幅优于密集模型。
此外,MiniMax 还引入了一个新的 allgather 通信步骤,专门用于解决扩大 MoE 模型规模时可能遇到的路由崩溃(routing collapse)问题。这是一个典型的高效算法设计思路。
计算优化
和许多大模型训练项目一样,MiniMax 先通过小规模实验验证上述技术改进的有效性以及 Scaling Law,然后再开始大规模训练。训练过程中,他们使用了 1500 到 2500 台 H800 GPU,并且具体数量会动态变化。大规模训练有其特有的挑战,MiniMax 为此开发了一系列针对性的优化。
首先,对于 MoE 架构,优化重点在于降低其通信负载,尤其是采用 all-to-all(a2a)通信的 MoE 模型。他们的解决方案是一种基于 token 分组的重叠方案。
其次,对于长上下文训练,一大难题是很难将真实的训练样本标准化到统一长度。传统的方法是填充,但这会造成严重的计算浪费。MiniMax 的思路是进行数据格式化,让不同样本沿序列维度首尾相连,并将这种技术命名为 data-packing。这种格式能最大限度地减少计算过程中的浪费。
最后,为了让 Lightning Attention 真正落地,MiniMax 采用了四项优化策略:分批核融合、分离式的预填充与解码执行、多级填充,以及跨步分批矩阵乘法扩展。
MiniMax-Text-01:上下文巨长,能力也够强
基于以上一系列创新,MiniMax 最终得到了一个拥有 32 个专家、总参数量达 4560 亿的 LLM,每个 token 会激活其中 459 亿个参数。这个模型被命名为 MiniMax-Text-01。推理时,它的上下文长度最高可达 400 万 token,并且展现出了非常卓越的长上下文能力。
MiniMax-Text-01 基准成绩优秀
在常见的学术测试集上,MiniMax-Text-01 基本能媲美甚至超越 GPT-4o、Claude 3.5 Sonnet 等闭源模型,以及 Qwen2.5、DeepSeek v3、Llama 3.1 等 SOTA 开源模型。直接看成绩。
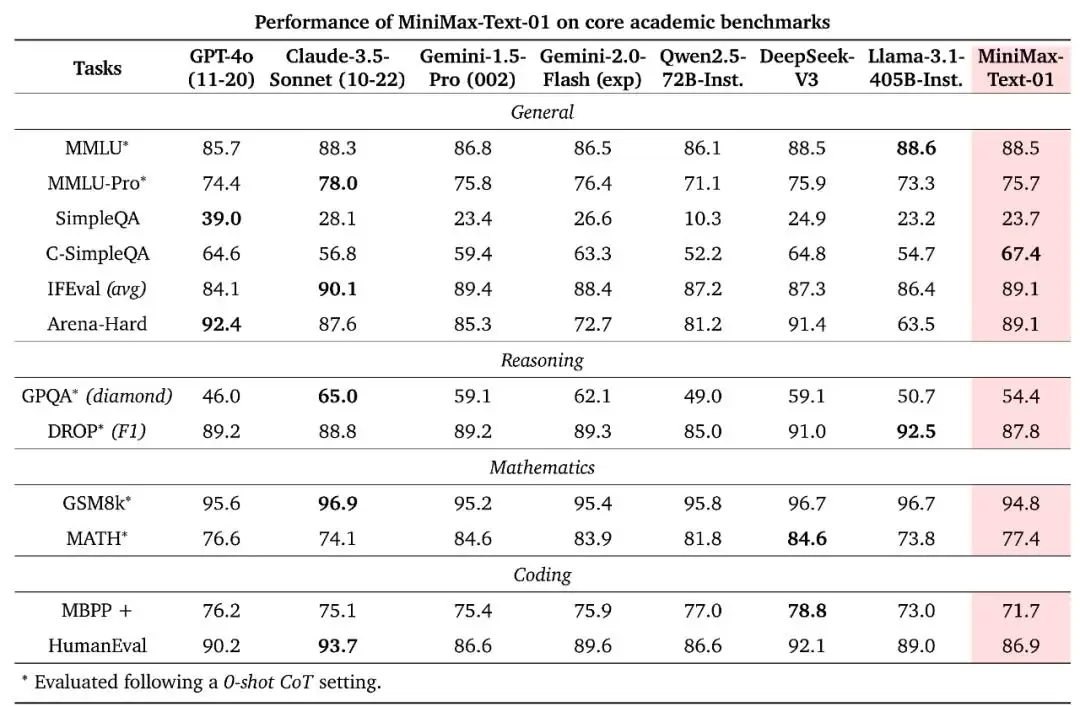
可以看到,在 HumanEval 上,MiniMax-Text-01 的表现与 Instruct Qwen2.5-72B 不相上下。此外,在 GPQA Diamond 这样具有挑战性的问答数据集上,它取得了 54.4 的成绩,超越了大多数开源指令微调的 LLM 以及最新版本的 GPT-4o。在 MMLU、IFEval 和 Arena-Hard 等测试中,它也跻身前三甲,展示了其在给定限制条件下,应用全面知识以满足用户查询、与人类偏好保持一致的卓越能力。这无疑为开发者开发 Agent 应用提供了更好的基础。
领先的上下文能力
那么,MiniMax-Text-01 引以为傲的长上下文能力到底有多强?优势非常明显。
在长上下文理解任务上,MiniMax 测试了 Ruler 和 LongBench v2 两个常见基准。在 Ruler 上,当上下文长度在 64k 或更短时,MiniMax-Text-01 与其它 SOTA 模型不相上下;而当上下文长度超过 128k 时,它的优势就立刻显现出来了。
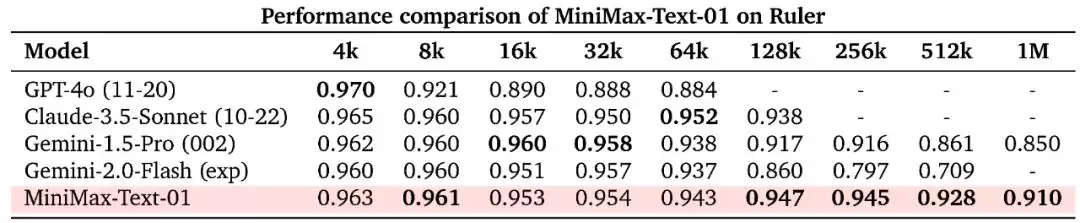
在 Ruler 上,MiniMax-Text-01 与其它模型的性能比较
同样,在 LongBench v2 的长上下文推理任务上,MiniMax-Text-01 的表现也十分突出。
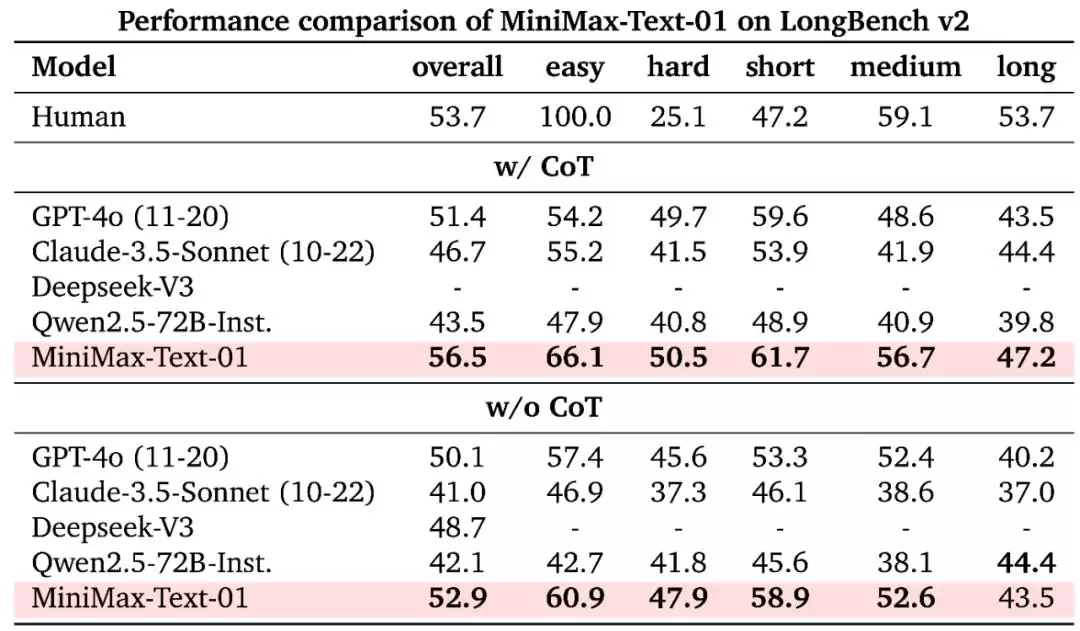
在 LongBench v2 上,MiniMax-Text-01 与其它模型的性能比较
另外,MiniMax-Text-01 的长上下文学习能力(这是终身学习的核心研究方向)也达到了 SOTA 水平,在 MTOB 基准上得到了充分验证。
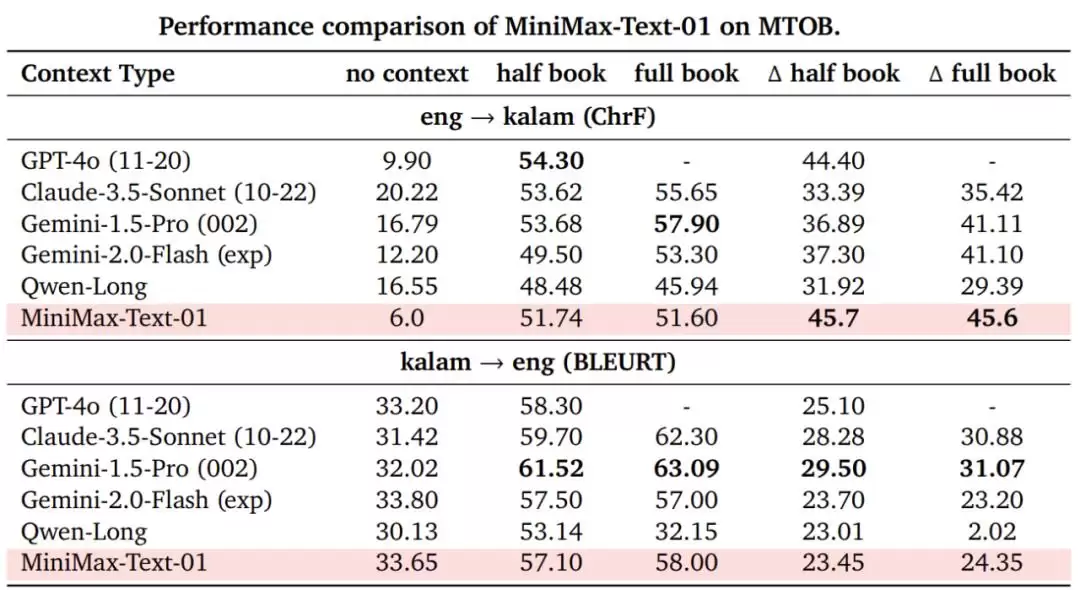
在 MTOB 上,MiniMax-Text-01 与其它模型的性能比较
长文本能力实例展示
基准分数不错,实际表现又如何?来看几个例子。
先写首歌吧。
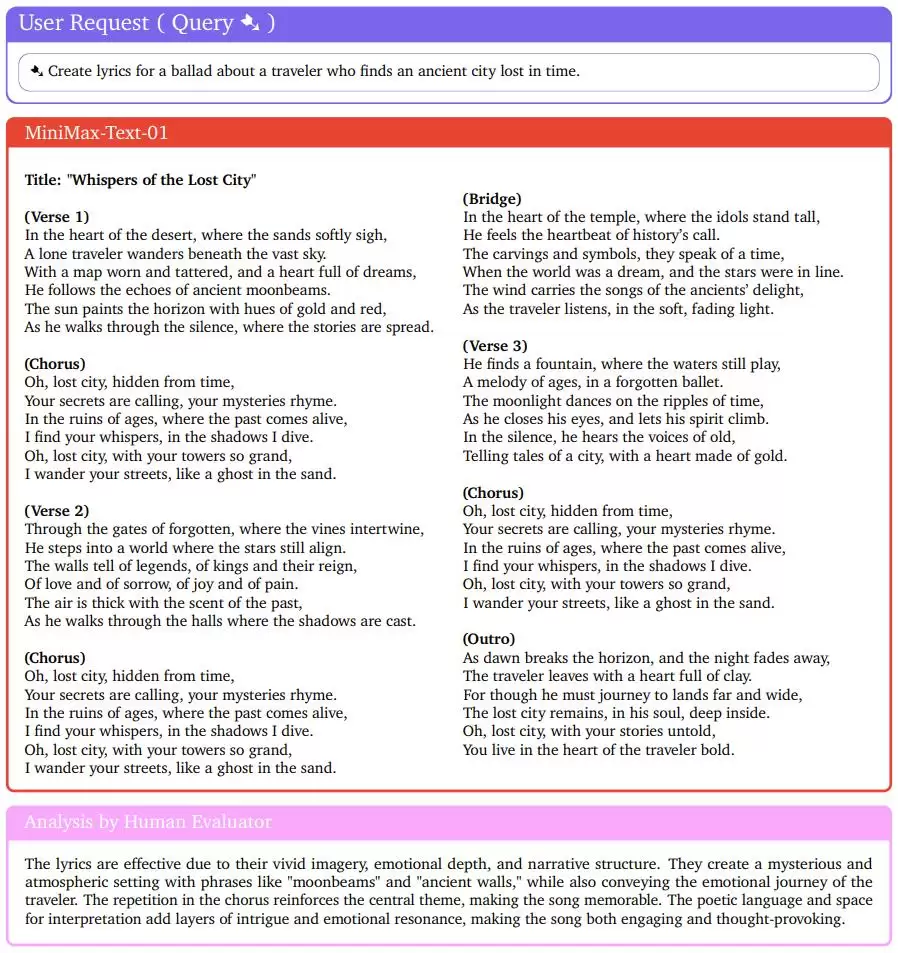
人类评估者给出了非常积极的评价:诗意的语言和演绎空间为歌曲增添了层层趣味和情感共鸣,使其既引人入胜又发人深省。
下面重点展示 MiniMax-Text-01 的长上下文能力。对于新几内亚的一门小众语言 Kalamang,将指令、语法书、单词表、与英语的对照例句全部放入上下文,然后让其执行翻译。可以看到,MiniMax-Text-01 给出的答案基本与标准答案一致。

至于长对话记忆任务,MiniMax-Text-01 的表现堪称完美。

视觉-语言模型
基于 MiniMax-Text-01,MiniMax 还开发了一个多模态版本:MiniMax-VL-01。思路很直接:在文本模型的基础上整合一个图像编码器和一个图像适配器。简而言之,就是将图像转化为 LLM 能够理解的 token 形式。
因此,其整体架构遵循了常见的 ViT-MLP-LLM 范式:以 MiniMax-VL-01 为基础模型,使用一个 303M 参数的 ViT 作为视觉编码器,并配以一个随机初始化的两层 MLP投影器来执行图像适应。当然,为了确保视觉理解能力足够强,还需要在文本模型的基础上使用图像-语言数据进行持续训练。MiniMax 为此设计了一个专有数据集,并采用了一个多阶段训练策略。
最终得到的 MiniMax-VL-01 模型在各个基准上的表现如下。
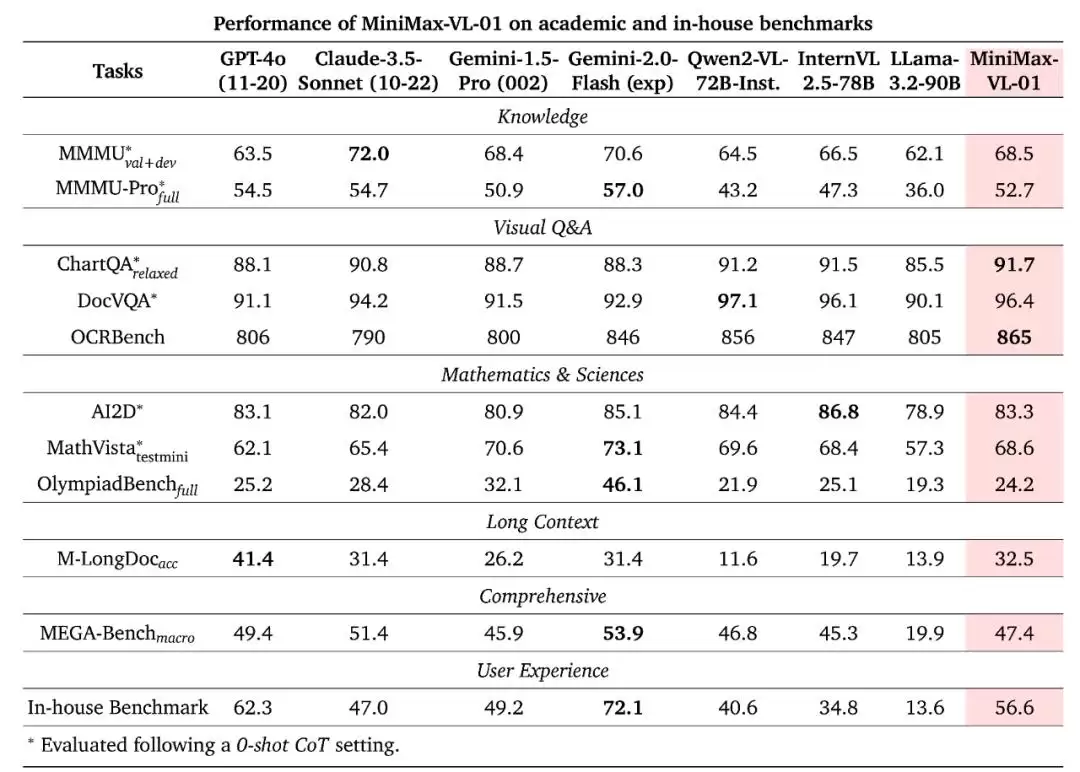
可以看到,MiniMax-VL-01 整体表现强劲,能与其它 SOTA 模型相媲美,并在某些指标上达到了最佳。
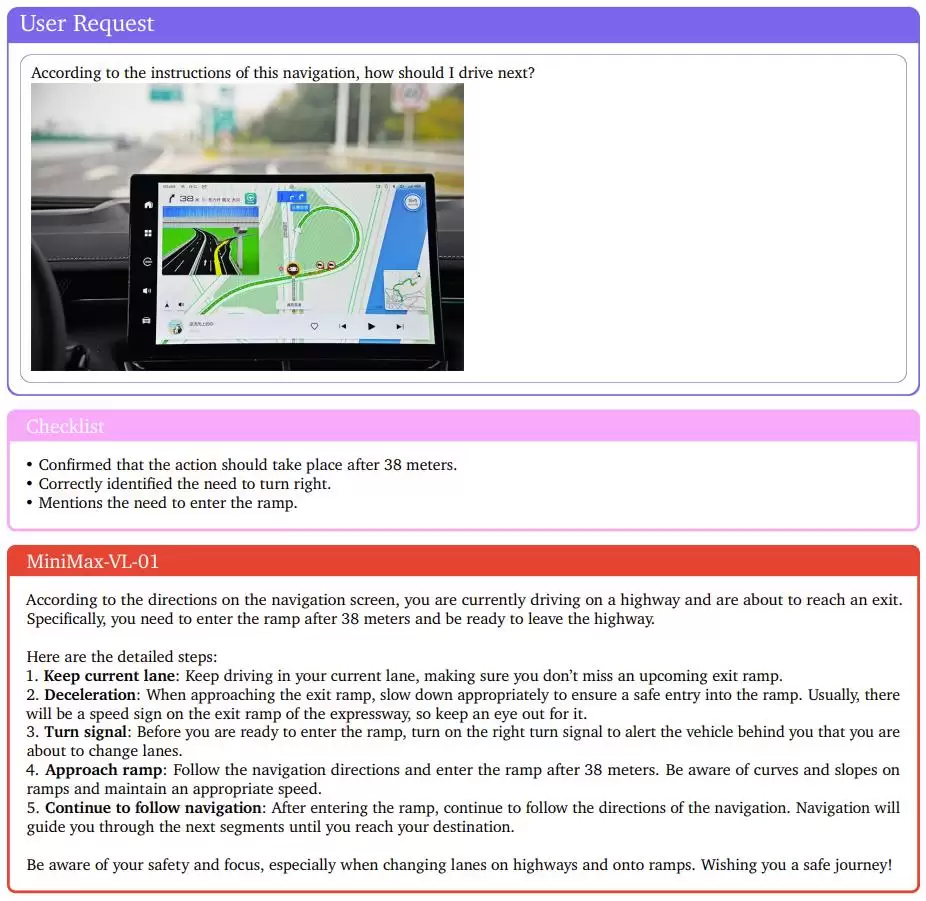
下面展示了一个分析导航地图的示例,MiniMax-VL-01 的表现值得点赞。
探索无限的上下文窗口,让 Agent 走进物理世界
有人认为,context 是贯穿 AI 产品发展的一条暗线。context 是否充分同步,会直接影响智能应用的用户体验——这包括用户的个性化信息、环境变化信息等各种背景上下文。为了保证 context 的充分同步,足够大的上下文窗口就成了大模型必须攻克的技术难题。目前,MiniMax 已经在这条路上迈出了重要的一步。
当然,400 万 token 的上下文窗口远不是终点。他们在技术报告中写道:“我们正在研究更高效的架构,以完全消除 softmax 注意力,这可能使模型能够支持无限的上下文窗口,而不会带来计算开销。” 除此之外,MiniMax 还在 LLM 的基础上训练了视觉语言模型,同样拥有超长的上下文窗口,这同样是由 Agent 所面对的任务决定的——毕竟,在现实生活中,多模态任务远比纯文本任务更为常见。
“我们认为,下一代人工智能是无限接近通过图灵测试的智能体,交互自然、触手可及、无处不在。”MiniMax 创始人在去年的一次活动中这样说道。或许,“无处不在”也意味着,随着多模态 token 的加入,Agent 将逐步走进物理世界。为此,整个 AI 社区需要更多的技术储备。
