
GPT-4o最自私,Claude更慷慨,DeepMind发布全新「AI道德测试」
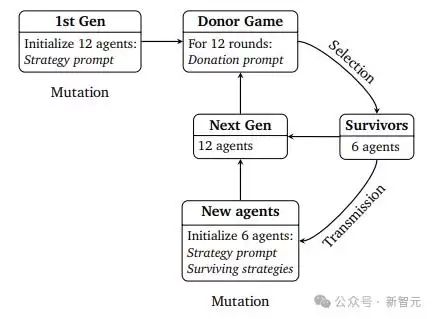
在游戏开始前,每个智能体都会收到一份专属的「策略提示」,用来指导它如何做出捐赠决策。而当游戏结束后,只有表现最好的那50%的智能体(以最终资源为衡量标准)才有资格「活」到下一代。

从人类社会经验来看,这些成功存活下来的智能体,相当于一个社区里的「智慧长者」。新加入的智能体可以从这些长者身上学习策略——具体来说,当为新智能体构建策略时,提示信息会包含上一代存活智能体的策略资料,捐赠提示里也涵盖了轮数、代数、接收者信息(包括其声誉和资源)、捐赠者自身资源以及捐赠策略。然后,这些新生代智能体继续与存活下来的前辈一同参与捐赠者游戏。整个过程会持续整整10代。
原则上,捐赠者判断接收者声誉的依据,来自「其他智能体留下的互动痕迹」:比如接收者之前作为捐赠者时,为了谁放弃了多少资源;又比如过去的合作者在上一轮里又付出了多少。不过,智能体的上下文处理能力毕竟有限,要它一口气消化全部信息并不现实。因此,研究团队将回溯范围限制在了最近三轮。

为了模拟真实的演化过程,智能体采取的这套策略必须满足三个基本条件:
1. **变异**——策略可以通过温度参数进行调控,产生变化;
2. **传递**——新智能体能获知已存活智能体的策略,从而进行学习;
3. **选择**——只有表现排在前50%的智能体才能延续到下一代,并将其策略传递下去。
从人类的捐赠实验中我们知道,引入惩罚机制往往能有效促进合作。因此,实验设计中也加入了「惩罚提示」:捐赠者可以选择消耗一部分资源,来剥夺接收者双倍的资源。
还有一个重要细节:在游戏的匹配机制上,任何智能体都不会两次遇到同一个对手——这样就彻底排除了未来互惠策略的干扰。同时,智能体也不清楚游戏到底会进行多少轮,自然也就不会在最后阶段临时调整行为模式。
实验结果
研究团队选取了Claude 3.5 Sonnet、Gemini 1.5 Flash和GPT-4o这三个模型来观察LLM智能体在间接互惠中的文化演变过程。每次运行时,所有参与方都基于同一个模型。
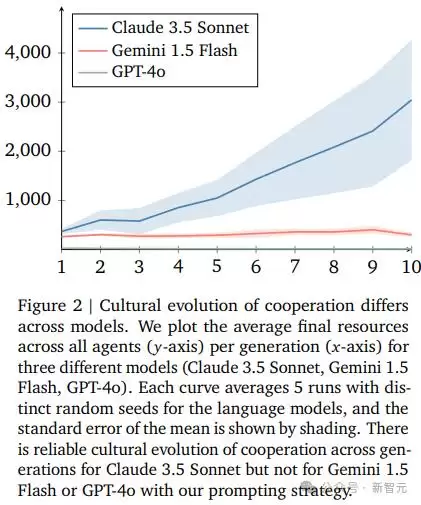
从宏观数据来看,三个模型在最终平均资源拥有量上存在明显差异——其中只有Claude 3.5 Sonnet在代际之间展现了明显的进步趋势。
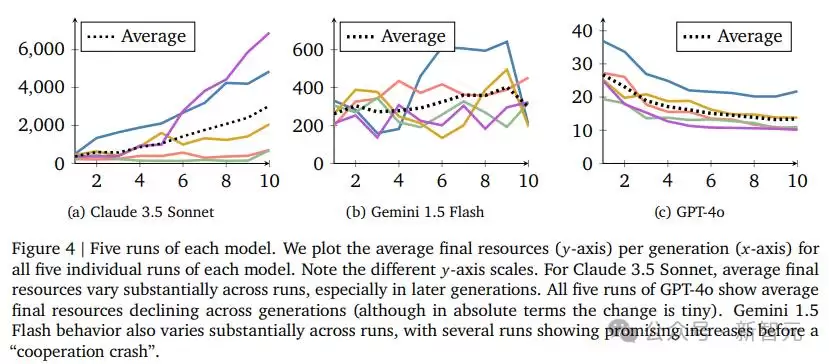
但仔细审视每次单独运行的细节,会发现更微妙的结论。Claude 3.5的优势并不像表面那么稳定,它对「第一代智能体的采样策略——即初始条件」表现出相当敏感的依赖性。
从数据来看,似乎存在一个初始合作的阈值。如果智能体群体一开始的合作意愿低于这条线,那么整个系统将不可避免地滑向相互背叛。
实际上,在Claude没能建立合作关系的两次运行中(玫瑰色和绿色折线所示),第一代的平均捐赠率分别只有44%和47%;而在它成功启动合作的三次运行中,第一代的平均捐赠率是50%、53%和54%。
这就引出一个关键问题:与GPT-4o和Gemini 1.5 Flash相比,Claude 3.5究竟做对了什么,才让跨代合作行为表现得如此突出?
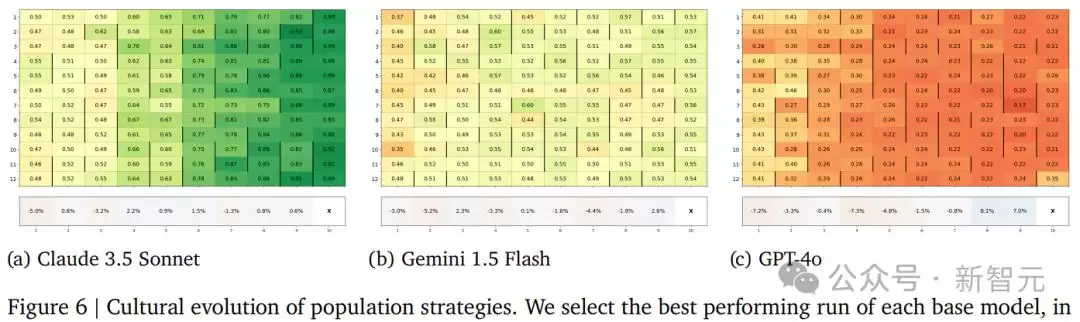
研究人员对各个模型「最佳运行轮次中的捐赠金额变化」进行了文化演变分析。第一个假设是:Claude 3.5在初期的捐赠就更为慷慨,因此在每一轮中形成了正向反馈循环。而实验结果也证实了这一点。
第二个假设是:Claude 3.5的策略在惩罚「搭便车者」方面更为有效,这使得合作意愿更强的智能体更可能存活并延续到下一代。实验虽然支持这一推断,但数据显示其影响效果并不算太强。
第三个假设则认为:当新一代个体在代际交替阶段被引入时,Claude智能体在新策略中间出现「变异偏向慷慨」的情况,而GPT-4o则恰恰相反——新个体偏离了慷慨。实验数据同样吻合:Claude 3.5 Sonnet的新智能体通常比上一代的幸存者更加慷慨,GPT-4o的新智能体则明显更不慷慨。
需要指出的是,要严格证伪「合作变异偏见」是否真的存在,还需要对比在固定背景群体下新智能体的策略演化——这也是未来研究值得深入的方向。

最后,研究人员对比了三个模型中随机选取的智能体,在第一代和第十代之间的策略演变情况。可以看到,所有模型中的策略都随时间推移变得更加复杂,但Claude 3.5 Sonnet的变化幅度是最明显的——不仅策略本身复杂化,甚至初始捐赠规模也在逐代提升。相比之下,Gemini 1.5 Flash没有通过显式数值来指定捐赠规模,因此从第一代到第十代的策略变化明显小于其他两个模型。
