构建 AI 时代的知识底座:直播数据 LLM Wiki 实践
来源:互联网
时间:2026-06-29 13:23:46
# 领域知识编译指南:从零散数据到AI知识库的完整实践
本教程详细介绍了如何将散落、矛盾、过时的数据知识,编译为AI可精准调用的统一知识库,从而让数据团队从重复答疑中解放出来。核心内容涵盖:领域知识对AI价值的关键作用、传统RAG的局限性、LLM Wiki“编译”过程的核心理念,以及在指标召回、SQL生成等场景中的实际应用效果。

阿里妹导读
文章内容基于作者个人技术实践与独立思考,旨在分享经验,仅代表个人观点。
一、为什么要知识库
领域知识决定了AI在业务中能发挥多大的价值和作用。任何AI系统都由
模型、知识、架构
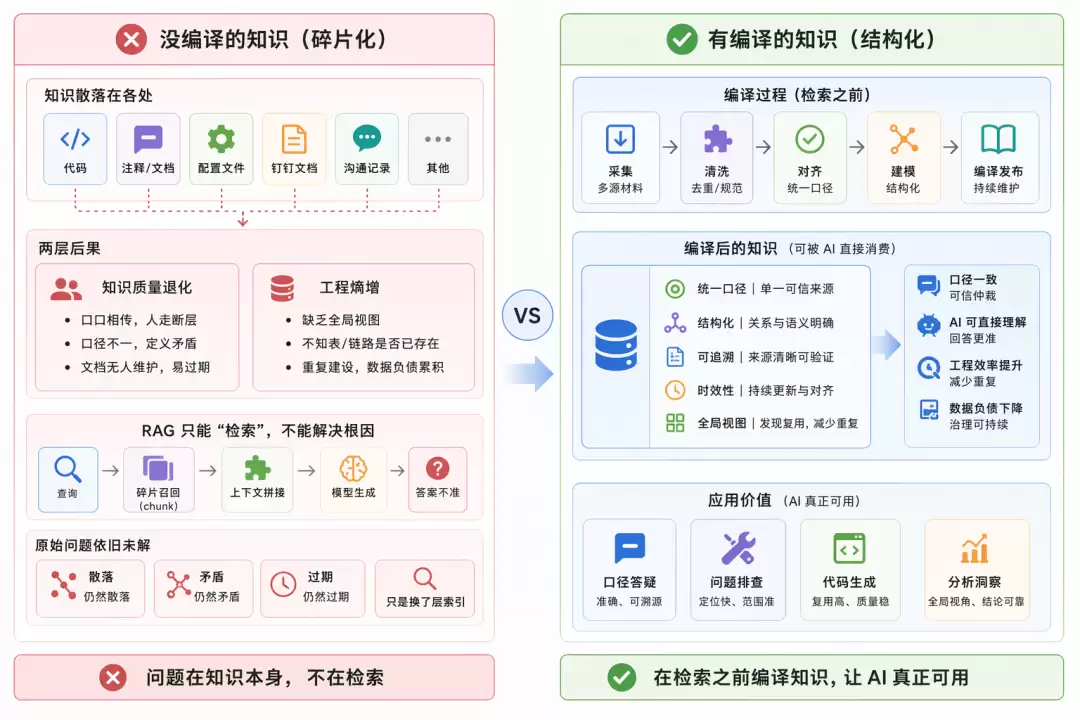
然而,领域知识的沉淀面临诸多挑战,在数据团队中尤为严重。知识散落在代码和注释、配置、钉钉文档、沟通记录等各处,没有统一载体,这带来两层后果:
- 传播靠口口相传,人走知识就断;口径不一致,同一指标在不同文档里定义矛盾,没人能仲裁;即便有人写了文档也无人持续维护,三个月后就和线上对不上。
知识质量退化:
- 缺乏全局视图,团队无法判断一张表是否已经存在、一条链路是否已有人建过,重复建设不断累积数据负债。
工程熵增:
数据团队中如口径答疑、问题排查、代码生成这些本可以被AI极大提效的场景,都卡在了“知识喂不进去”这一步。
直接套RAG解决不了这件事。RAG的模式是每次查询都到原始文档碎片里现找现拼——chunk召回、上下文拼接、模型生成——但它并不改变原始材料本身的状态。散落的还是散落的,矛盾的还是矛盾的,过期的还是过期的,只是多了一层向量索引。知识本身的问题一个没解决,只是把“人找不到”变成了“AI找到了但答不准”。
问题出在知识本身,不在检索。