
刚刚,DeepSeek V4更新DSpark,推理速度提升80%
DeepSeek V4 又更新了,这次不声不响地放了个大招。
新推出的投机解码框架
DSpark
DeepSpec
需要说明的是,这次不是全新架构的模型换代,而是在 DeepSeek-V4-Pro 的基础上,引入了推测性解码模块。说白了,这次更新的重点在于工程落地,而非模型能力本身的迭代。
DSpark 目前已经在 DeepSeek-V4(Flash 和 Pro)的真实线上流量中部署,效果立竿见影——大语言模型的推理速度大幅提升。

技术报告:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
技术报告链接:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
DSpark 的初衷,归根结底就是解决生产环境中的老大难问题——尤其是在高并发场景下,LLM 推理面临的延迟和吞吐量瓶颈。简单来说,它成功地把高吞吐量的「并行生成」和自适应的「负载感知验证」结合到了一起。
推测性解码是什么?它本质上是一种不改变模型输出分布,却能加速大模型推理的技术。核心思路是引入一个轻量级的「草稿模型」,先预生成一批候选 token,然后由目标模型批量验证并接受或拒绝。这样一来,原本串行的逐 token 生成就变成了并行批量校验,端到端延迟自然就降下来了。
而 DSpark 的创新点,在于引入了
半自回归生成架构(Semi-Autoregressive Generation)
另一个关键创新是
硬件感知的置信度调度验证(Confidence-Scheduled Verification)
为了保证在真实线上基础设施中落地,DSpark 的调度器还采用了异步机制,兼容零开销调度和连续的 CUDA 图回放。它利用前两步的历史预测,来决定当前动态截断长度,从而隐藏了调度延迟,避免了 GPU 流水线停顿,同时保证了目标模型输出分布完全无损还原。
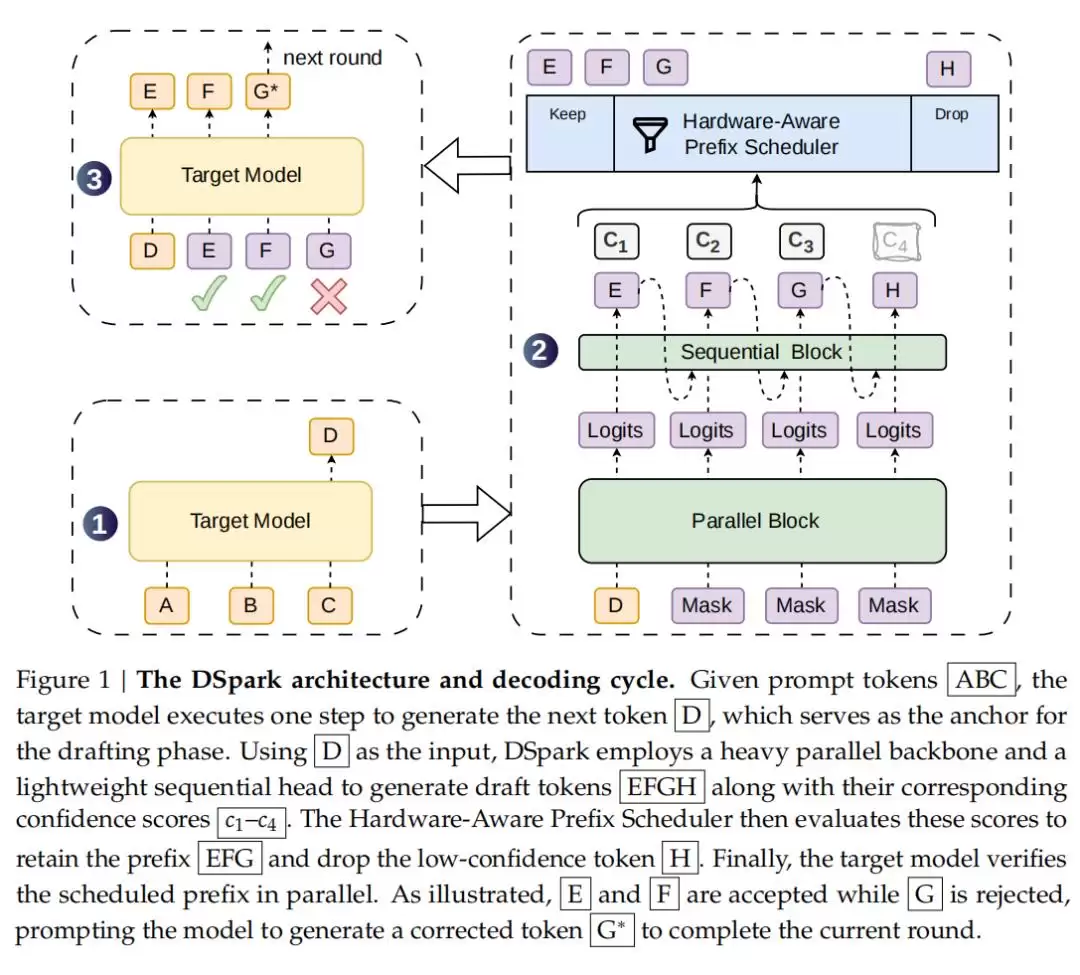
测试数据也很能说明问题。在数学推理、代码生成和日常对话等多个领域,DSpark 大幅超越了目前最先进的自回归模型(Eagle3)和并行草稿模型(DFlash)。举个例子,在 Qwen3 系列(4B、8B、14B)目标模型上,它的平均接受长度比 Eagle3 提升了 26.7% 到 30.9%,比 DFlash 提升了 16.3% 到 18.4%。
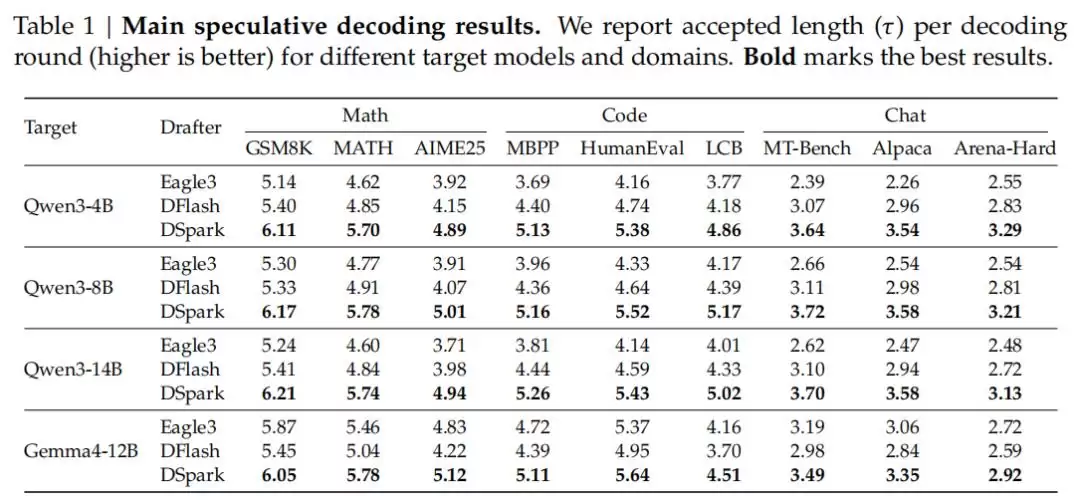
和上一代部署的单 Token 生产基准(MTP-1)相比,在维持相同总体吞吐量的情况下,
DSpark 将用户的生成速度分别提升了 60%-85%(Flash 模型)和 57%-78%(Pro 模型)
随 DSpark 一同开源的 DeepSpec,是一个用于训练和评估推测性解码草稿模型的全栈代码库。它承载了这套方案以及其他前沿算法的实现,堪称「开源基础设施」。里面包含了数据准备工具、草稿模型实现、训练代码和评估脚本,一应俱全。
DeepSpec 把整体流程拆成了三个阶段:数据准备、训练和评估。三个阶段需要按顺序运行,前一阶段的输出作为后一阶段的输入。
数据准备阶段,需要下载提示词数据,用推理引擎对目标模型重新生成答案,并构建目标缓存。值得注意的是,以默认的 Qwen/Qwen3-4B 配置为例,目标缓存体积可达约 38 TB。在动手之前,一定要先评估好存储资源。
训练阶段可以通过 bash scripts/train/train.sh 启动。脚本会调用 train.py,并为每张可见的 GPU 启动一个 worker。用户可以通过指定 config_path,在 config/ 目录下选择不同算法和目标模型配置。项目也支持通过覆盖 config_path、target_cache_dir,以及使用 --opts 修改单个配置字段来调整训练设置。
硬件方面,DeepSpec 默认配置面向单节点 8 卡环境。如果你的 GPU 数量较少,就需要相应减少 CUDA_VISIBLE_DEVICES 中的可见 GPU 数量。
评估阶段通过 bash scripts/eval/eval.sh 启动。评估脚本会使用训练好的草稿模型 checkpoint,在多个 speculative decoding 基准任务上衡量接受情况。项目当前列出的评估数据集包括 GSM8K、MATH500、AIME25、HumanEval、MBPP、LiveCodeBench、MT-Bench、Alpaca 和 Arena-Hard-v2,覆盖了数学推理、代码生成、对话能力和综合问答等不同任务类型。
算法方面,DeepSpec 目前内置了三种草稿模型:DSpark、DFlash 和 Eagle3。目标模型系列方面,目前支持 Qwen3 和 Gemma。
DeepSpec 的开源,把推测性解码这一此前散落于各研究团队内部的工程实践,整合成了一套可复现、可扩展的标准化工具链。对于希望为自有大模型加速推理的研究者和工程师来说,这意味着可以直接在成熟框架上训练定制草稿模型,跳过大量重复的基础设施搭建工作。
参考链接:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
-

- 网名带郑和霍字的网名女有哪些
- 角色扮演 | 1
- 网名