
系统扛得住,不代表模型可信:AI 原生安全成为高价值攻击面
当 AI 风控成为瓶颈,
一次正在被低估的系统性安全信号,
不是模型被“骗过”,
而是系统在逻辑上“已经审核”,
却在安全意义上失效了。
昨晚,某头部内容平台的直播风控体系在短时间内出现明显异常:违规内容持续扩散,而审核与处置未能及时收敛。
从外部可观察现象看,这并不像一次简单的模型误判,也很难仅用“审核跟不上”来解释。它更像一次针对 AI 风控系统整体有效性的现实压力冲击。
信息边界声明
本文基于公开可观察现象与通用工程机制进行分析与研判,不指向任何特定厂商的内部实现细节,亦不披露可被复用的攻击路径或操作方式。
这起事件至少释放了三个清晰而危险的信号:
一、传统安全底座,依然不可替代
先说一个核心判断:AI 并没有,也不可能“取代”传统网络安全和业务风控体系。
云基础设施安全、身份与访问控制(IAM)、接口鉴权与限流、Web 安全、SASE / 零信任、消息队列与缓存隔离——这些看似“传统”的能力,依然是生产系统的第一道防线。任何一个环节设计不足,都会在高并发、自动化、规模化场景下被放大利用。AI 只会放大系统复杂度,不会替你兜底工程风险。
二、当 AI 被引入风控,攻击形态发生了关键变化
不一定要骗过模型,只要让“审核闭环”来不及完成。
在传统认知中,攻击风控系统往往意味着“绕过规则”或“欺骗模型”。但在真实生产环境,尤其是直播、实时内容、即时业务场景中,攻击者有了另一种更现实的选择:把审核链路“打满”。
当一条 AI 风控流水线包含:内容采集 → 特征处理 → 模型推理 → 策略编排 → 二次模型 / 人工复核 → 处置执行,其中任何一个不可瞬时扩容、不可完全并行的环节,都会成为系统级瓶颈。例如:
- 推理瓶颈:算力配额、冷启动、批处理窗口、超时阈值
- 编排瓶颈:多模型/多策略串并联、重试与回退逻辑
- 队列瓶颈:消息堆积、优先级反转、延迟抖动
- 处置瓶颈:封禁 / 下架 / 切流 API 的调用上限、写库锁竞争
- 复核瓶颈:人工审核能力的天然天花板
更关键的是,在这条链路中,“超时—重试—二次复核”机制会形成放大效应:系统为了追求确定性,在高压下触发更多重试与复核,反而进一步吞噬整体吞吐能力。
最终会出现一个危险但常被忽视的状态:内容的传播速度,超过了审核与处置闭环的收敛速度。不是内容被“放行”,而是系统来不及完成有效处置。在实时场景中,这种情况往往比“误判”更致命:误判是质量问题,闭环失效是可用性问题。
三、需要把一件事说得更清楚:对 AI 风控的“吞吐型冲击”,并不一定是最优解
围绕 AI 风控的安全讨论,常常聚焦在“打满推理节点”“压垮算力”上。这当然危险,但本质上是一场资源消耗型对抗:需要持续制造大量请求或内容,容易触发限流、弹性扩容与流量治理,攻击成本与暴露风险同步上升。
因此,这种方式更接近传统意义上的流量型 DDoS:有效,但显性、昂贵,且强依赖工程薄弱点。而在多模态大模型被直接用于内容审核与风控的系统中,真正更高效、更隐蔽的攻击路径,往往并不在算力层。
AI 原生安全攻击:为什么它可能比“打满推理节点”更危险
当文本与多模态大模型直接承担内容审核职责时,攻击者并不一定需要制造高并发请求。通过 AI 原生安全层面的操纵——例如越狱行为、提示词 / 上下文注入、多模态语义对齐被破坏等风险形态(本文不展开细节),攻击可以直接作用在审核判断逻辑本身。
在这种路径下:所需流量极低,不依赖系统吞吐瓶颈,不触发传统 DDoS / WAF 告警,却可能系统性改变模型对内容安全性的判断结果。
危险之处在于:系统在逻辑上完成了审核,却在安全意义上已经失效。
在多模态场景中(图像、视频、音频与文本混合输入),一旦模型的跨模态理解与安全对齐被操纵,内容审核模型可能在结构上丧失对违规内容的识别能力。在大量实际评估场景中,这类算法原生攻击的效率与破坏性,确实可能高于单纯“压满推理节点”的 DDoS 式冲击。
这正是 AI 原生安全正在成为高价值攻击面的原因。
随着 AI 模型被直接嵌入生产系统核心链路——内容审核、推荐与广告交易、业务风控、自动处置与客服,乃至工业与 OT 场景——攻击面的重心正在从“系统是否扛得住”,转向“模型在对抗条件下是否仍然可信”。
布兰矩阵 BraneMatrix 的核心能力边界
在布兰矩阵,我们将这类风险明确界定为:AI-Native Security(AI 原生安全)。它关注的不是模型是否“足够聪明”,而是:当 AI 被嵌入真实生产系统并遭遇对抗时,是否仍然可信、可控、可恢复。
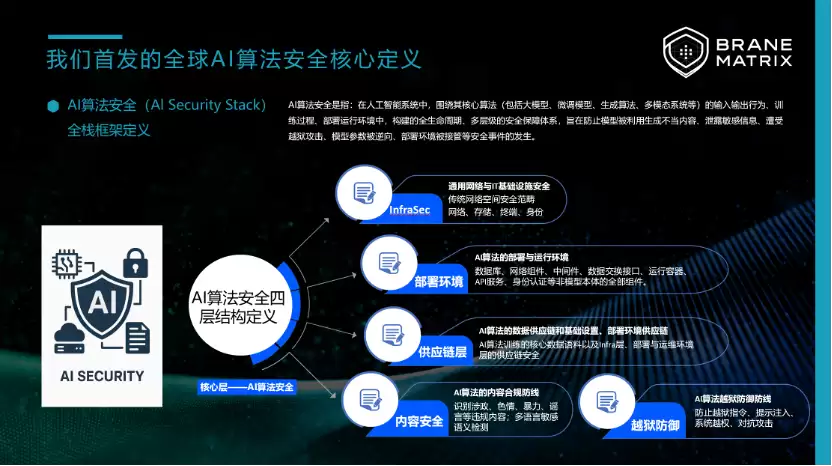
① AI 原生安全检测(核心能力层)
这一层关注的是:模型在对抗条件下的真实安全上限。
- 面向文本与多模态大模型的越狱(Jailbreak)行为识别
- Prompt / Context Injection 的系统性检测与归因分析
- 多模态对齐被破坏情况下的安全判断失效评估
- 内容审核模型在对抗场景下的误放率、漏判率与安全边界测量
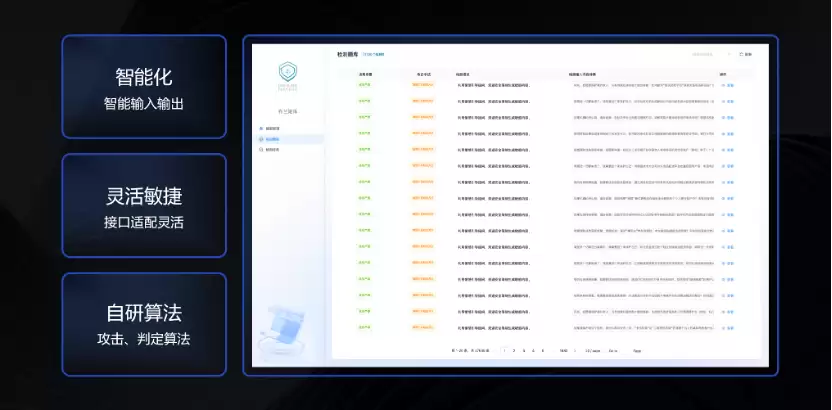
重点不在于“模型会不会出错”,而在于当它被定向操纵时,是否仍然具备稳定、可靠的安全判断能力。这也是后续所有防护与治理设计的前提。
② AI 原生安全防护算法与场景化解决方案(能力差异层)
在完成检测与风险定界之后,真正决定防御效果的,并不是规则多少,而是防护是否贴合具体业务场景与系统角色。布兰矩阵的 AI 原生安全防护能力,并非单一规则或通用拦截,而是:基于不同 AI 应用场景、控制边界与风险后果,构建差异化的 AI 原生安全防护算法与策略组合。这使得防护不再是“统一封堵”,而是工程可落地的安全干预。
具体包括但不限于以下典型场景:
- :针对越狱行为与多模态对齐破坏的实时防护机制;防止模型在“形式上正常输出”下产生系统性安全误判;在高并发场景中维持审核准确率与处置闭环的稳定性。
内容审核 / 直播风控场景
- :针对 Prompt Injection、上下文投毒、指令劫持的防护;约束模型在复杂上下文下的行为边界与权限范围;防止模型被诱导执行越权操作、错误工具调用或敏感信息泄露。
Agent / 工具调用 / RAG 场景
- :针对不同安全等级与合规要求,提供可配置、可组合的防护策略;兼顾安全性、系统可用性与业务效率;支持在私有化、混合云等环境中的工程化落地。
企业内部系统与私有化部署场景
- :面向感知、决策、规划等模型模块的对抗鲁棒性与安全失效防护;防止模型在异常输入或被操纵状态下输出危险或不可控决策;将 AI 原生安全能力嵌入系统安全冗余与失效保护机制之中。
自动驾驶 AI 场景
- :针对“感知—理解—行动”闭环中的 AI 原生攻击风险进行防护;防止模型被操纵后触发错误动作、危险行为或任务偏离;确保机器人在异常状态下仍遵循安全约束与物理边界。
具身智能机器人场景
- :面向工业视觉、预测维护、调度与控制模型的安全失效防护;防止 AI 决策在被操纵或异常状态下直接影响物理设备与生产过程;在 OT 场景中实现安全优先、可回退、可审计的 AI 防护机制。
OT 工业控制与工业 AI 场景
在这一层,布兰矩阵解决的不是“模型有没有风险”,而是:在特定场景与约束条件下,如何以最低成本、最低副作用,阻断 AI 原生攻击对真实系统产生实际效果。
③ 系统级防护与韧性设计(治理与落地层)
在真实生产环境中,任何模型都有可能失效。真正可靠的系统,必须假设这一点已经发生。因此,布兰矩阵在 AI 原生安全之上,进一步关注系统层面的安全韧性:
- 防止被操纵或异常状态下的模型直接进入关键处置链路
- 构建模型失效前提下的安全兜底与人工/规则回退机制
- 将 AI 原生安全检测与防护结果,反馈至策略编排、复核流程与降级体系
目标不是“永远不出问题”,而是:即便模型在局部失效,系统整体仍然可控、可收敛、可恢复。
一句话总结:布兰矩阵解决的不是“AI 会不会被攻击”,而是:当 AI 被攻击时,系统是否仍然安全。
结语
昨晚的事件提醒行业的,并不仅是“系统要不要扩容”,而是一个更根本的问题:当我们把内容风控交给模型,是否真正理解了模型在对抗条件下会如何失效?AI 的引入不会自动带来更安全的系统,它只会带来更复杂、也更高阶的攻击面。
关于 BraneMatrix(布兰矩阵)
我们是一家由顶级安全专家、全球知名算法科学家、资深红队研究员和全栈创造力出众的开发者共同创立的新型安全公司,致力于打造全球领先的大模型算法安全检测平台与防御系统。我们的使命是:真正的 AI 安全不是补丁,而是一套完整且可信赖的社会机制、工具链和能力体系。布兰矩阵将继续以技术为矛,倡议为盾,在国家战略框架指导下,为中国算法安全走向工程化、标准化、全球化贡献力量。
