
大模型的“三重门”,AI的尽头是什么?
1956年夏天,美国新罕布什尔州的达特茅斯学院迎来了一场特殊的学术聚会。当数学教授约翰·麦卡锡在会议提案中首次写下“Artificial Intelligence”这个术语时,恐怕连他自己也未曾料到,这场原本计划用两个月“彻底解决机器模拟智能问题”的讨论,竟会开启一场跨越将近七十年的认知革命。
不久前,阿里巴巴集团CEO吴泳铭在财报会议上抛出了一个颇为大胆的论断,他说:“一旦AGI真正实现,其所催生的产业规模,极有可能问鼎全球之首,甚至有可能深刻地影响、乃至部分取代当下全球经济构成中近半壁江山的产业形态。” 这话语中的分量,似乎预示着一种历史转折的关键时刻正在来临。
在大众的视野里,惊喜与担忧总是相伴而生。人们一边学着接纳和拥抱人工智能,一边又惴惴不安地猜测着通用人工智能(AGI)何时能够降临。然而,一个值得冷静思考的问题是:作为掀起这轮AI浪潮的主角,大语言模型或许还仅仅是个探路者。它离真正的AGI相距甚远,甚至可能根本就不是通往AGI的正途。那么,我们究竟离那个“圣杯”还有多远?

谁是AGI的起点?
“通用人工智能(AGI)”这个术语,最早可以追溯到北卡罗莱纳大学的物理学家Mark Gubrud。1997年,他在一篇关于军事技术的文章中将AGI定义为“在复杂性和速度上与人脑相媲美或超越的AI系统,能够获取一般性知识,并以其为基础进行推理和操作”。换句话说,人类一直以来期待的,并不是一个只会下棋或者只会聊天的工具,而是一台真正能够像人一样感知、推理、创造并适应复杂环境的机器。
从GPT-4的对话能力,到Sora的视频生成,近年来AI技术的进步确实让人眼花缭乱。但冷静下来看,现在的AI系统虽然在特定任务上表现惊艳——比如文本生成或图像识别——本质上依旧停留在“高级模仿”的阶段。它们缺乏对物理世界的真实感知,也缺少自主决策的能力。这背后隐含的逻辑是:AI的核心,是把现实世界的现象翻译成数学模型,通过语言让机器理解数据和世界的关系。而AGI则更进一步,它要求AI具备跨领域学习和迁移的能力,从而展现出真正的“通用性”。
那么,当下的大语言模型到底卡在了哪里?问题至少有三个层面。
第一,能力边界有限。大模型只能处理文本领域的任务,无法与物理或社会环境进行有效的互动。换句话说,像ChatGPT、DeepSeek这样的模型,本质上是一种“文弱书生”,它们没有身体去体验三维空间的触觉、重力、温度,因此也就不能真正地“理解”语言背后所指代的物理世界。
第二,缺乏自主性。大模型需要人类为每一个任务进行明确的定义和引导。这就像一个训练有素的“鹦鹉”,只能模仿它被训练过的那些话语。而真正自主的智能,应当更像“乌鸦智能”——乌鸦能够自主完成复杂的任务,甚至能利用工具,这种能力是当下任何AI系统尚未具备的。
第三,道德坐标的缺失。虽然ChatGPT在浩如烟海的文本数据中进行了训练,其中包含大量隐含着人类价值观的内容,但它并不具备理解或内化这些价值的能力。说白了,它没有“道德指南针”。
不过,这并不妨碍科技巨头对大模型的推崇。OpenAI的CEO萨姆·奥特曼就多次高调宣称,GPT系列模型是通往AGI的重要突破。按照OpenAI自己提出的AGI五级标准:L1是聊天机器人——具备基本的会话能力;L2是推理者——能解决人类级别的复杂逻辑问题;L3是智能体——能代表用户自主采取行动;L4是创新者——能够助力发明和科技进步;L5是组织者——能够执行复杂的组织管理任务。
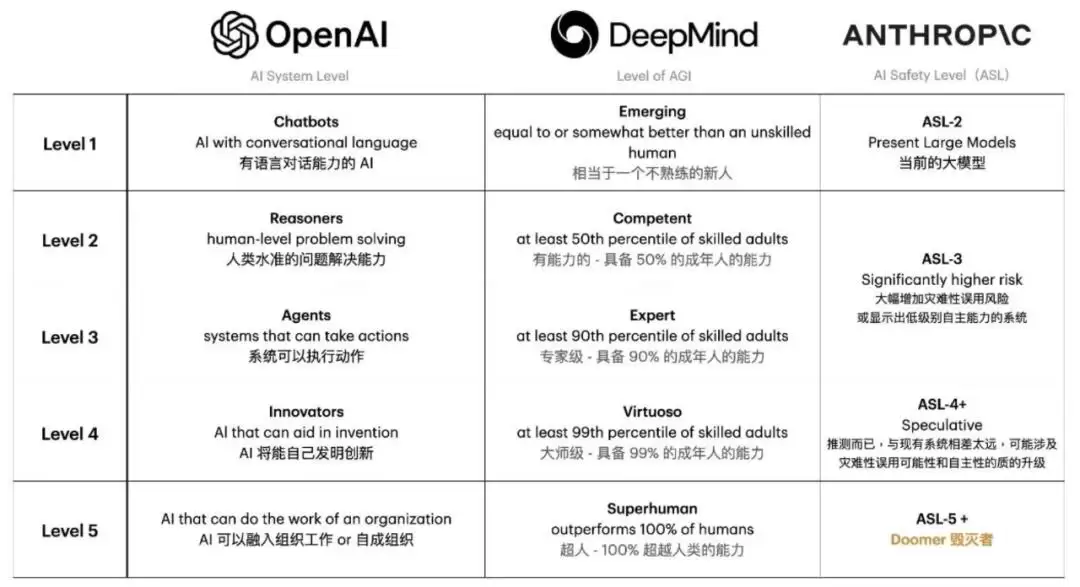
按照这个划分,当前的技术水平正从L2向L3跃迁。2025年被业内视为“智能体(Agent)”应用的爆发之年,像ChatGPT、DeepSeek、Sora这类应用已经开始逐步融入人们的日常工作与生活。但路径上的问题依然不容回避:大模型偶尔出现的“幻觉输出”,暴露了它对因果关系理解的局限性;自动驾驶汽车在面对极端场景时的决策困境,则折射出现实世界的复杂性与伦理悖论。
这就好比人类智能的进化,其实塑造的是多层架构:既有本能层面的快速反应,也有皮层控制的深度思考。要让机器真正理解“苹果为什么会落地”,需要的不仅仅是数据之间的关联,更是对物理世界建立起一个完整的心智模型。这种根本性的认知鸿沟,很可能是我们目前难以想象的深度。
通向AGI的必经之路
关于大模型的演进路径,业内有一个相对清晰的共识,那就是它会经历三个阶段:单模态 → 多模态 → 世界模型。
早期,语言、视觉、声音各模态独立发展;当前,我们正处于多模态的融合阶段。例如,GPT-4V能够理解输入的文字与图像,而Sora则可以根据文字、图像和视频生成新的视频内容。
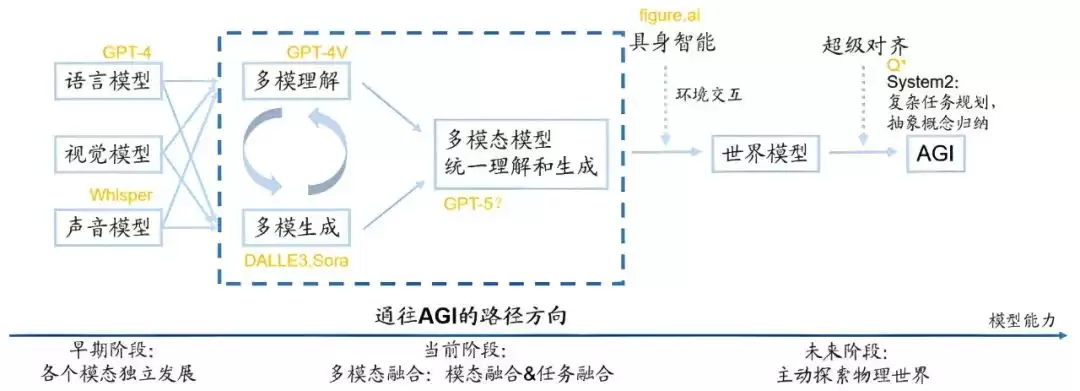
但这里有一个关键问题:现阶段的多模态融合并不彻底。“理解”与“生成”这两个核心任务是被分开处理的。结果就是,GPT-4V的理解能力强,但生成能力弱;而Sora生成能力强,但有时候理解能力很差。从技术逻辑上讲,让多模态的理解与生成实现真正意义上的统一,才是走向AGI的必经之路。这一点非常关键,值得反复强调。
为什么不走这条路不行?因为人与现实世界的交互,天然就涉及多种模态的信息。所以,AI也必须能够处理和理解图像、文本、音频、视频等多种形式的数据。更进一步说,要想模拟动态环境的变化,并做出预测和决策,同样需要强大的多模态生成能力。
不同模态的数据,往往包含的是互补的信息。比如在图像标注任务中,文本信息可以帮助模型更好地理解图像内容;而在语音识别中,视频里的唇动信息则能有效提升识别的准确率。通过融合这些信息,模型可以建立起更泛化的特征表示,从而在面对陌生的复杂数据时,展现出更好的适应性和泛化能力。
目前,多模态模型的研究大概有几种技术路径:基于对齐的方法,把不同模态的数据映射到同一个特征空间;融合方法,将多模态数据整合进不同的模型层;自监督技术,在未标记的数据上进行预训练;以及通过噪声添加来增强模型的鲁棒性。组合使用这些技术,模型在处理现实数据方面的能力已经相当可观。
案例并不难找。比如微软近期开源的多模态模型Magma,不仅能跨数字和物理世界处理图像、视频、文本,还能推测视频中人或物体的意图和未来行为。再如阶跃星辰的Step系列,已经与吉利汽车的星睿AI大模型完成了深度融合,开始推动AI在智能座舱和高阶智驾中的应用。而蘑菇车联推出的MogoMind,则更进一步——它整合了物理世界的实时数据,具备多模态理解、时空推理和自适应进化的能力,甚至可以通过城市基础设施中的摄像头、传感器和车路云系统,对物理世界进行实时感知与认知反馈。
但话说回来,多模态的发展并非一路坦途。数据获取和处理的难度、模型设计本身的复杂性、以及模态间的不一致和不平衡问题,都是非常现实的挑战。获取高质量且标注精准的多模态数据,成本本身就很高;而设计一个能够有效融合多种模态的深度学习模型,其复杂程度远超单模态模型。不同模态之间,信息量可能差别很大——有的丰富可靠,有的稀疏含噪——如何平衡这些信息,同样是模型设计中的难点。
当前一种值得关注的趋势是,从训练之初就打多数模态数据,实现端到端的输入与输出,也就是所谓的“原生多模态”技术路线。这种路线试图在训练阶段就对齐视觉、音频、3D等不同模态的数据,从而构建出一个更加协同统一的智能系统。
将AI拉回现实世界
对于目前大模型的路线,Meta的首席AI科学家杨立昆(Yann LeCun)一直持保留态度,他认为这根本无法通往AGI。在他看来,现有的大模型本质上仍是一种“统计建模”技术,它们通过海量数据学习统计规律,但并不具备真正的“理解”和“推理”能力。
他所推崇的“世界模型”,才更接近真正的智能。看看人类的学习过程就知道了:一个孩童在成长中,更多是通过观察、触摸、互动来认知这个世界,而不是单纯地被“注入”知识。第一次开车的人,在过弯道时会很自然地知道提前减速;儿童只需要学会一小部分语言,就能掌握整门语言的规则;动物不懂物理学,却会本能地躲避高处滚落的石块。
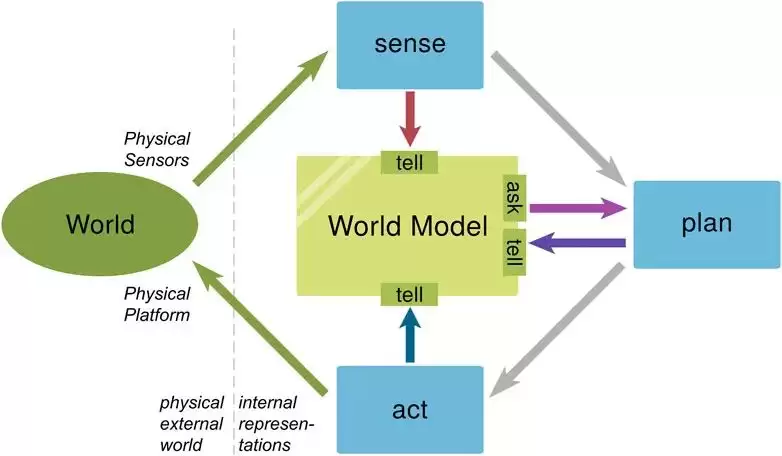
世界模型之所以广受关注,正是因为它在试图回答那个最根本的问题:如何让AI真正地理解世界?它试图通过模拟和补全视频、音频等外部感知数据,让AI也经历一个类似于人类自主学习的过程,从而形成“常识”,最终走向AGI。
那么,世界模型和多模态大模型的根本区别是什么?主要有两方面。其一,世界模型主要通过摄像头、传感器等设备直接感知外部环境信息,输入的是实时的感知数据;而多模态大模型更多是处理图片、文字、视频、音频这类与人交互的静态或历史信息。其二,世界模型的输出,通常是时间序列数据,可以直接用来控制机器人执行物理动作;而多模态大模型输出的,往往是过往信息的沉淀,对实时性要求不高。
从这个意义上说,世界模型被行业人士视为实现AGI的一道曙光,也就不难理解了。
当然,世界模型的发展也并非一帆风顺。挑战之一,是它在模拟环境动态与因果关系方面的能力,特别是“反事实推理”——也就是假设环境中的某个因素变了,结果会如何?比如在自动驾驶中,模型需要能够预测:如果某个行人突然改变方向,车辆的行驶路径会受到怎样的影响?目前的世界模型在这方面的能力还相当有限。
另一个大挑战,是对物理规则的精确模拟。Sora可以生成一段物体运动或光反射的视频,但在流体力学、空气动力学这些更复杂的物理现象上,它的准确性和一致性依然远远不够。想要克服这个挑战,研究人员可能需要在模型中内置更精确的物理引擎和计算模型。
此外,泛化能力也是一个关键的评估标准。这里强调的不只是数据的内插,更重要的是数据的外推。比方说,真实的交通事故或者极端的驾驶行为,在训练数据中是非常罕见的。一个优秀的、具备世界模型的系统,是否能够通过已有的认知,去“想象”出这些罕见的情况?做到这一点,模型才能真正应用于现实的复杂世界。
说到底,对于AI来说,让机器人亲自“拧开一次瓶盖”所获取的物理直觉,往往比观看百万次操作视频建立得更加真实。通过在模型训练过程中融入更多真实场景的实时动态数据,AI才能更好地理解三维世界中的空间关系、运动行为和物理规律。最终,AGI的到来可能不会像奇点理论所预言的那般石破天惊,它更像晨雾中的群山,在数据洪流的不断冲刷下,渐次显露出它们的轮廓。
AI的尽头,并不是一个固定的终点,而是一段人类与技术共同书写的未来叙事。它可能成为工具,可能成为伙伴,也可能带来某种威胁,甚至可能超越我们现有的所有想象。但关键的问题或许不在于“AI的尽头是什么”,而在于——“人类希望以什么样的价值观去引导这场变革?” 正如斯蒂芬·霍金所警示的那样:“AI的崛起,可能是人类历史上最好或最糟糕的事件。” 答案并不在技术的演进中,而恰恰取决于我们今天的决策与责任。届时,AI将重新认识世界,而我们也要重新想象未来的人机交互方式。
