
深入解析 SuperSonic:下一代 AI+BI 平台的架构与应用
来源:互联网
时间:2026-06-27 13:53:40
先抛个结论:SuperSonic正在重新定义AI+BI的协作方式。它巧妙地将自然语言能力和语义层设计合二为一,让数据分析这件事变得前所未有的直观。具体来说,它提供了三个核心能力:可以用自然语言直接查询数据、基于语义模型构建逻辑层而不必动底层物理数据,以及通过Ja va SPI让架构保持灵活可扩展。简单讲,就是既要“聊天式BI”的便捷,又要“无头BI”的严谨——两者互相成就,Chat BI借助语义模型获取精准上下文,Headless BI则让自然语言接口直接服务于查询。
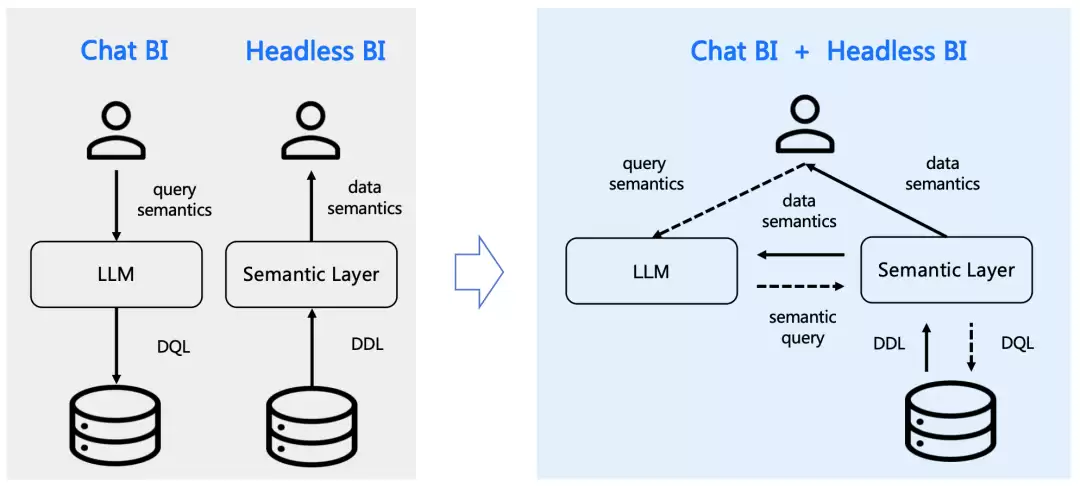
为什么选择 SuperSonic?
区别于一堆还在概念阶段的方案,SuperSonic的价值在于它已经经历了生产环境的验证——在腾讯音乐的实际业务中跑通了全流程。它的Text2SQL技术让大模型在数据查询中的潜力落地,语义层设计让查询一致性不再是空谈,而插件化的Ja va SPI架构则意味着团队可以按需扩展功能,不用被固定框架绑死。
SuperSonic 架构解析
整套架构走的是模块化路线,每个组件各司其职,性能与扩展性都考虑得比较周全。下面拆开来说。
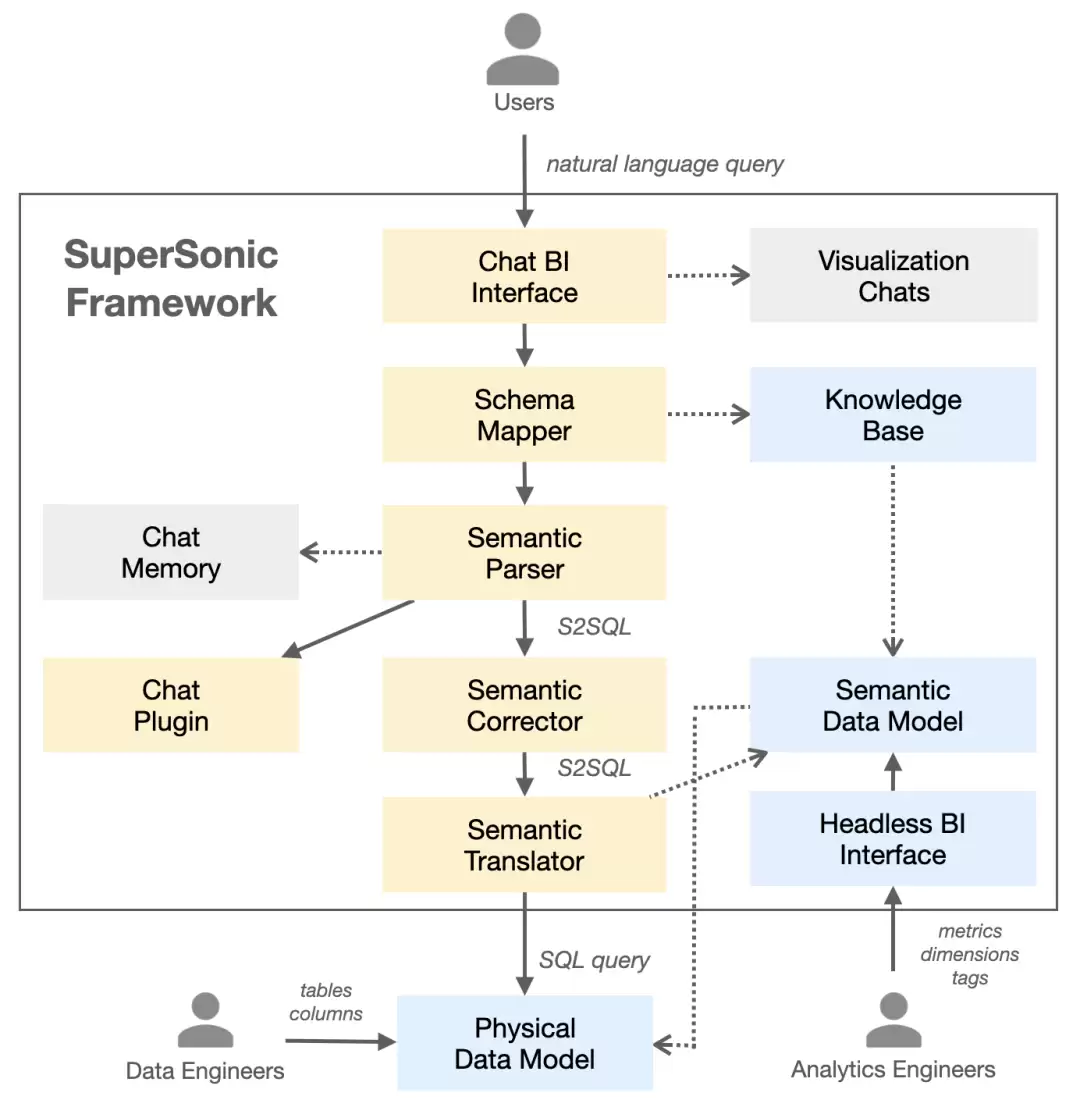
1. 知识库(Knowledge Base)
- :定期从语义模型里提取模式信息——像表结构、列名这些,建成字典和索引。
功能
- :快速把自然语言查询映射到数据库模式,查得快、准头也好。
作用
- :知识库充当数据元信息的中枢,让Schema Mapper的匹配过程更顺畅。
技术细节
2. 模式映射器(Schema Mapper)
- :把用户的自然语言输入(比如“上个月销售额”)跟知识库里的表、列对上号。
功能
- :架起用户语言和数据库术语之间的桥梁。
作用
- :通过索引和上下文分析,尽可能减少歧义,匹配精度拉高。
技术细节
3. 语义解析器(Semantic Parser)
- :解析用户查询,提取语义,生成中间查询语言S2SQL。
功能
- :把自然语言结构化,变成系统能处理的查询表示。
作用
- :S2SQL作为中间表示,让后面的优化和翻译更干净。
技术细节
4. 语义校正器(Semantic Corrector)
- :验证并优化S2SQL,修掉潜在的错误或歧义。
功能
- :保证查询逻辑有效,减少生成无效SQL的可能。
作用
- :靠规则和上下文校验,提升鲁棒性。
技术细节
5. 语义翻译器(Semantic Translator)
- :把S2SQL翻译成能在物理数据库上直接跑的SQL。
功能
- :完成从语义表示到实际执行语句的转换。
作用
- :支持多种数据库方言,兼容性有保障。
技术细节
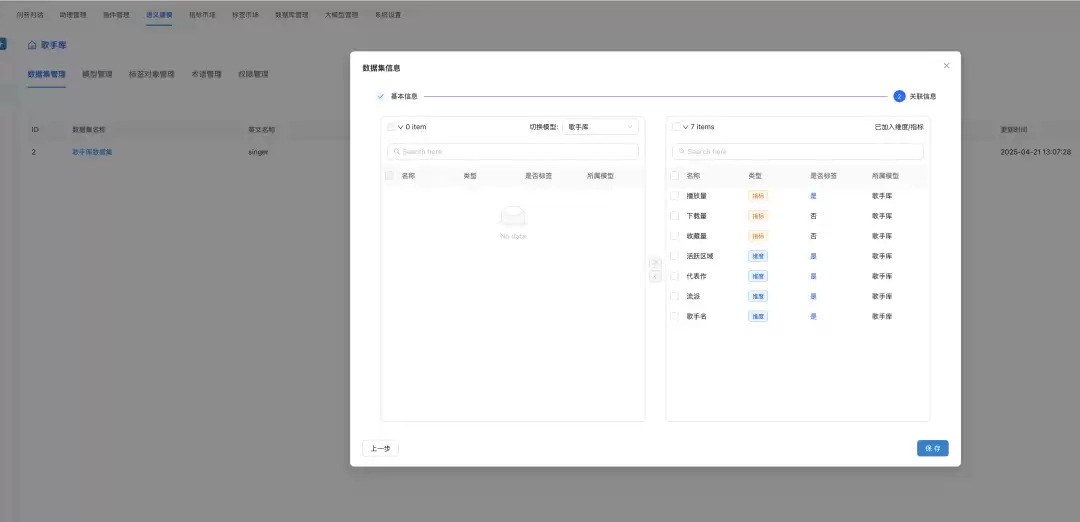
6. 聊天插件(Chat Plugin)
- :通过集成第三方工具扩展能力,大模型会根据查询内容选择合适的插件。
功能
- :让系统更灵活,定制空间更大。
作用
- :基于Ja va SPI实现,开发者加新插件比较方便。
技术细节
工作流程
SuperSonic的查询处理大致走这么几步:
- 用户输入自然语言,比如“上个月销售额是多少?”
- 借助
模式映射器
识别相关的表和列。知识库
- 生成S2SQL。
语义解析器
- 优化一下。
语义校正器
- 转换成最终SQL。
语义翻译器
- 系统执行SQL,取数据并生成可视化结果。
部署与上手
SuperSonic提供了好几种部署方式,方便不同需求的开发者快速跑起来。
前置条件
- :最快上手用。
Docker
- :如果要自己从源码构建。
Ja va
- :了解SQL和数据模型会更容易理解系统逻辑。
数据库知识
方式 1:Docker 部署
最简单的方式,适合快速体验。
- :参考官方文档。
安装 Docker 和 Docker Compose
- :
下载 Docker Compose 文件
wget https://raw.githubusercontent.com/tencentmusic/supersonic/master/docker/docker-compose.yml - :
启动容器
docker-compose up -d - :浏览器打开
访问系统
http://localhost:9080,自带示例语义模型,可以直接尝试自然语言查询。
方式 2:本地构建
适合想深入研究代码的开发者。
- 去 SuperSonic 发布页面下载最新的预构建二进制文件。
- 启动服务:
bash assembly/bin/supersonic-daemon.sh start - 同样访问
http://localhost:9080。
探索源代码
- :
克隆仓库
git clone https://github.com/tencentmusic/supersonic.git - :看
模块分析
pom.xml,重点研究auth、chat、common、launchers和headless这些模块。建议从chat模块入手,理解 Chat BI 的实现细节。 - :
Ja va SPI
common模块里有 SPI 接口和实现,可以直接学习插件化开发的套路。
应用场景与扩展
SuperSonic 能用在不少地方:
- :用自然语言降低 BI 工具的门槛,非技术人员也能上手。
企业数据分析
- :基于 Headless BI 构建定制化的数据应用。
数据产品开发
- :探索 Text2SQL 和语义层结合的新玩法。
AI 技术研究
如果想进一步扩展,开发者可以:
- :利用 Ja va SPI 开发新功能,比如自定义可视化组件或数据处理逻辑。
自定义插件
- :调整大模型参数或语义解析策略,提升复杂查询的准确率。
优化 Text2SQL
- :通过聊天插件接入第三方服务。
集成外部工具
挑战与局限性
功能虽强,但有些地方还需要留意:
- :复杂场景下自然语言的歧义还是会导致 SQL 生成出错。
Text2SQL 可靠性
- :多表、多关系的数据库会增加模式映射的复杂度。
大规模模式
- :自然语言处理和 SQL 生成在高并发时可能成为瓶颈。
性能优化
应对这些挑战,可以从优化知识库、调整大模型参数或者改进语义校正逻辑入手。
总结
SuperSonic 是一个把 AI 和 BI 融合得相当到位的平台。Chat BI 和 Headless BI 的结合,让数据查询有了全新的体验:模块化架构、Text2SQL 技术、语义层设计——无论你是想快速部署体验一下,还是打算深入源码研究,它都能带来不少启发。

资源
- SuperSonic GitHub
- 官方文档
- 发布页面
