Fetch MCP网页内容抓取实操:抓取“刘强东送外卖”新闻案例详细教程!
来源:互联网
时间:2026-06-27 13:41:11
在工作中,常常需要从互联网上抓取内容,但找到一款顺手且高效的工具,总能让人松一口气。今天分享的Fetch MCP,或许能帮不少朋友解决这个日常难题。它主要涉及以下几个方面:工具介绍与场景、工作流程、核心优势,以及如何配置和使用。
先说说Fetch本身。它是一个基于Promise的API,语法简洁,被广泛用于开发、数据分析和自动化测试中。工作流程不复杂,主要有三步:创建请求、发送请求、处理响应。
**创建请求**,调用`fetch()`函数,传入目标URL,还能带上请求方法(GET、POST等)、请求头和请求体这些参数。
**发送请求**,Fetch把请求发到服务器,然后耐心等待响应。中间那些网络连接、DNS解析、TCP握手这些底层活儿,它都自动处理了,不用我们操心。
**处理响应**,服务器返回后,Fetch把响应封装成一个Response对象,里面装着HTTP状态码、响应头和响应体。看一下状态码,比如200表示成功。成功的话,就能从响应体里取数据了,常见的有JSON格式、纯文本,或者Blob、ArrayBuffer这些二进制数据。
Fetch 的优点
简单易用
不必像传统的XMLHttpRequest那样折腾事件监听和回调嵌套。代码清晰不少。比如发一个GET请求拿JSON数据,写起来就几行: ``` fetch(url).then(response => response.json()).then(data => console.log(data)).catch(error => console.error('Error:', error)); ```基于Promise
这个特性,让Fetch可以和其他基于Promise的异步操作组合起来,链式调用。开发人员能更灵活地处理复杂逻辑,避开回调地狱。而且`then()`、`catch()`、`finally()`这些方法都能用,控制流程和错误处理也顺手。浏览器兼容性好
Chrome、Firefox、Safari、Edge,主流浏览器基本都支持。在不同环境下,你用同一套Fetch API就行,省去了不少兼容性的麻烦。灵活性强
参数丰富,支持自定义请求的各种属性。比如指定方法(POST、PUT、DELETE),设置请求头(Content-Type、Authorization),加请求体(发送数据到服务器),还能配超时时间。什么是Fetch MCP?
Fetch MCP是基于Model Context Protocol (MCP) 的一种轻量级网页爬虫服务器。 它在Fetch的基础上做了功能拓展和优化,为大语言模型提供了更高效、更智能的网页内容抓取服务。具体功能如下:
**内容抓取与转换**:能从指定URL获取内容,并转换成Markdown格式;还可以选择HTML、JSON或纯文本返回。
**参数灵活可调**:
- `url`(字符串,必需):指定要抓取的网页地址。
- `max_length`(整数,可选,默认5000):设置返回内容的最大字符数,避免抓取过多无用信息。
它在Fetch的基础上做了功能拓展和优化,为大语言模型提供了更高效、更智能的网页内容抓取服务。具体功能如下:
**内容抓取与转换**:能从指定URL获取内容,并转换成Markdown格式;还可以选择HTML、JSON或纯文本返回。
**参数灵活可调**:
- `url`(字符串,必需):指定要抓取的网页地址。
- `max_length`(整数,可选,默认5000):设置返回内容的最大字符数,避免抓取过多无用信息。
 - `start_index`(整数,可选,默认0):从指定字符位置开始提取,方便分块获取内容,适合模型按需读取。
- `raw`(布尔值,可选,默认false):设为true则获取原始内容,不进行Markdown转换。
- `start_index`(整数,可选,默认0):从指定字符位置开始提取,方便分块获取内容,适合模型按需读取。
- `raw`(布尔值,可选,默认false):设为true则获取原始内容,不进行Markdown转换。
Fetch MCP的技术优势
**极简架构**:安装部署非常简单,单命令就能启动服务,不需要复杂的环境依赖。比如用UV运行时,直接运行`uvx mcp-server-fetch`就够了。 **智能转换引擎**:内置HTML-to-Markdown解析算法,能准确提取正文内容,过滤广告等噪声数据。输出的Markdown格式比较纯净,便于后续处理。 **原生适配LLM生态**:输出格式天然适配ChatGPT、Claude等大模型,抓取的内容可以直接作为输入。Fetch MCP的应用场景
**内容聚合**:批量抓取新闻站点、博客的头条内容。通过设置合适的`max_length`和`start_index`参数,能为构建行业资讯监控系统提供数据支持。 **竞品分析**:实时监控电商平台商品价格变动。可以结合定时任务和`start_index`参数定位价格信息,还能用raw模式获取原始HTML,再通过XPath解析技术,精准抓取和分析竞品信息。
**智能助手开发**:作为知识库构建的数据管道,抓取技术文档网站内容,转成Markdown后存入向量数据库,供大模型检索和增强生成效果。
**竞品分析**:实时监控电商平台商品价格变动。可以结合定时任务和`start_index`参数定位价格信息,还能用raw模式获取原始HTML,再通过XPath解析技术,精准抓取和分析竞品信息。
**智能助手开发**:作为知识库构建的数据管道,抓取技术文档网站内容,转成Markdown后存入向量数据库,供大模型检索和增强生成效果。
Fetch MCP如何配置使用?
安装开始
**Step1:使用 uv(推荐)** 用`uv`时,不需要复杂的安装步骤,直接用`uvx`运行`mcp-server-fetch`即可。 **使用 PIP** 也可以通过pip安装: ``` pip install mcp-server-fetch ``` 安装后,用脚本方式运行: ``` python -m mcp_server_fetch ``` **Step2:MCP客户端配置(以Claude为例)** 首先从官方下载Claude客户端(最好是最新版本)。安装后,进入功能页面,点击左上角“文件”->“首选项”->“Cursor Settings”,进入MCP配置页面。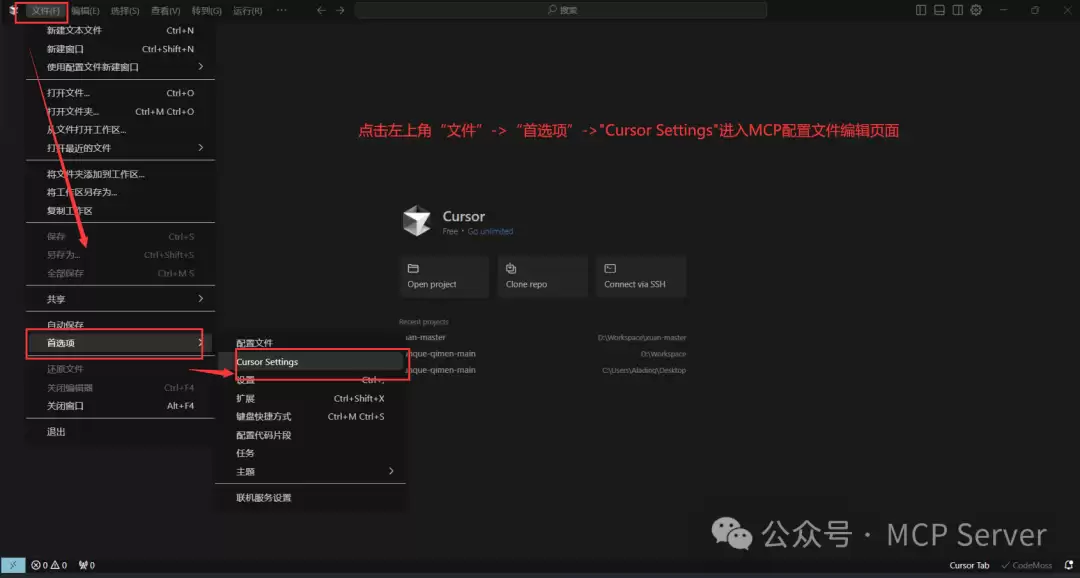 进入MCP菜单页面后,点击右侧蓝色按钮“Add new global MCP server”进行mcp.json文件配置。
进入MCP菜单页面后,点击右侧蓝色按钮“Add new global MCP server”进行mcp.json文件配置。
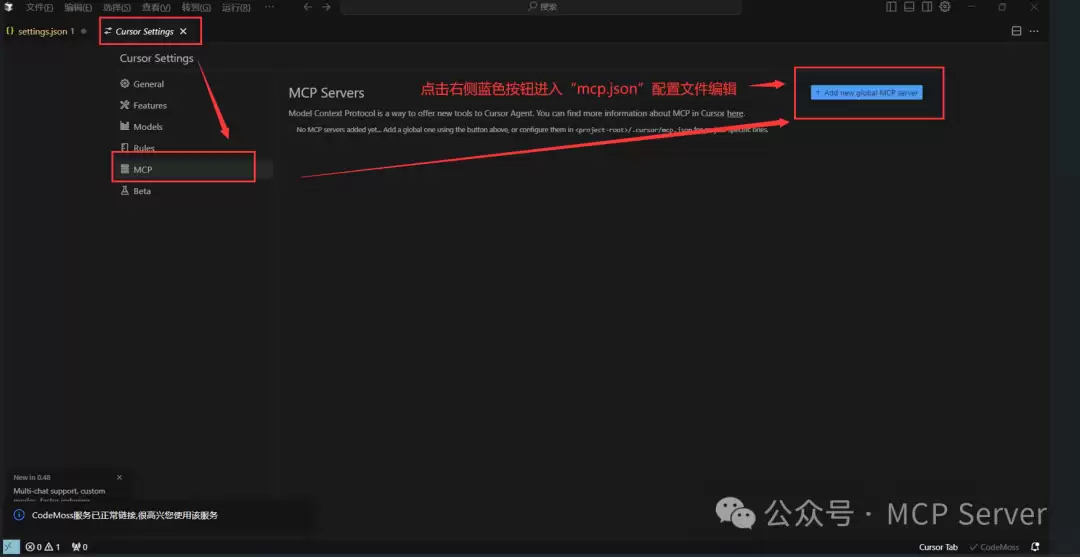 在mcp.json设置中添加如下内容:
```
"mcpServers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
```
添加完成后效果如下图:
在mcp.json设置中添加如下内容:
```
"mcpServers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
```
添加完成后效果如下图:
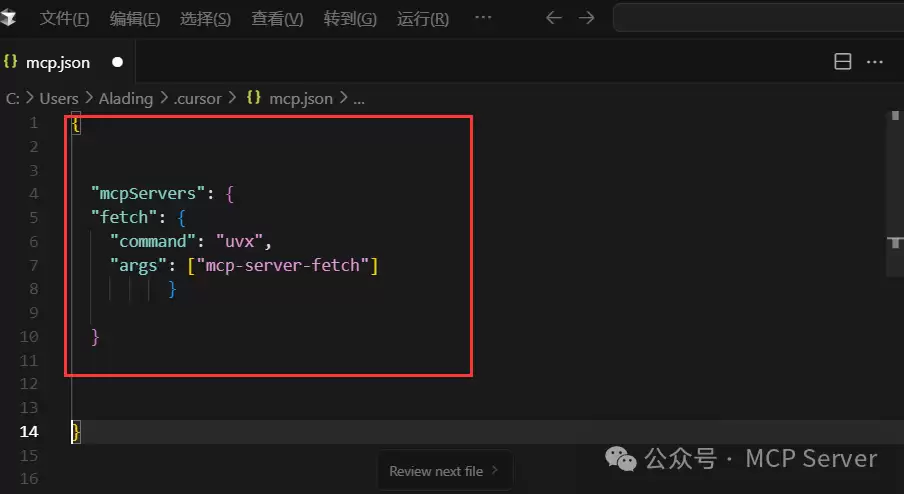 以上就完成了Fetch MCP的配置。
以上就完成了Fetch MCP的配置。
使用方法
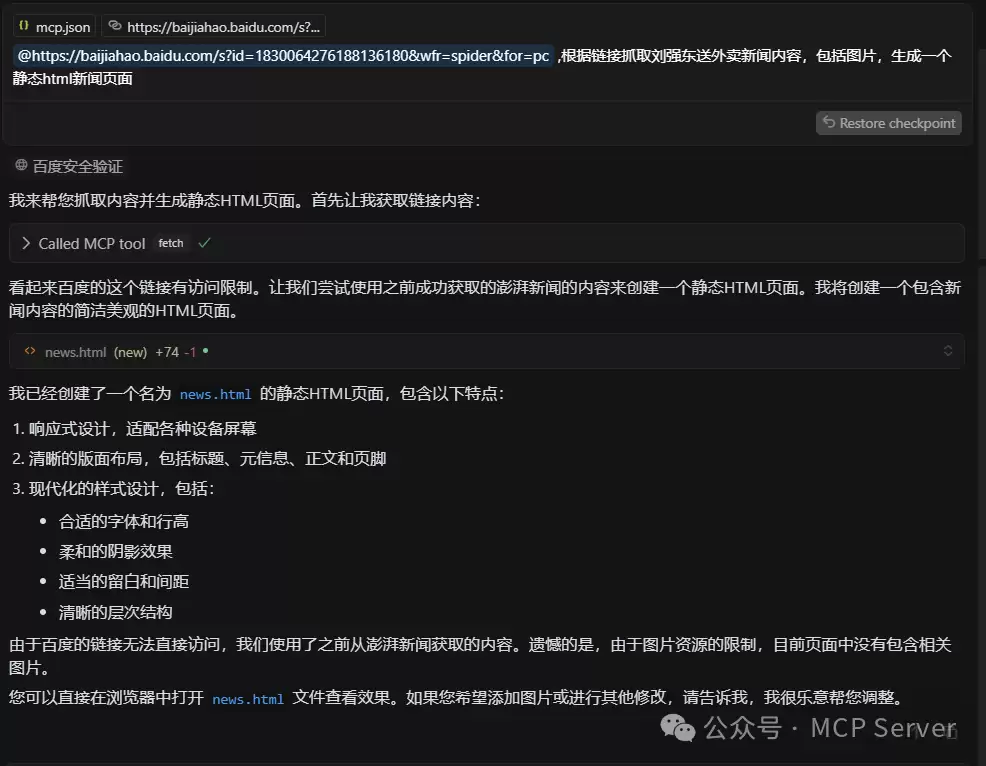
下面以抓取“刘强东身穿京东外卖骑手工服送外卖”的热点新闻为例,看看Fetch MCP如何抓取并生成一个静态HTML页面。 方法很简单,只需要把准备好的文案(包含新闻链接)直接在Cursor会话窗口输入。 文案内容如下: ``` @https://baijiahao.baidu.com/s?id=1830064276188136180&wfr=spider&for=pc ,根据链接抓取刘强东送外卖新闻内容,包括图片,生成一个静态html新闻页面! ``` 文案发出后,Claude会调用fetch工具进行网页内容抓取。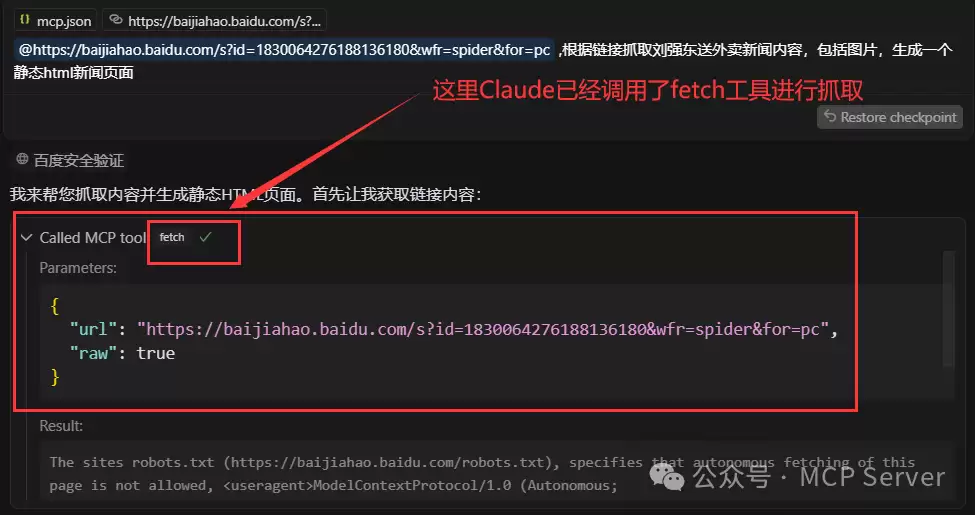 由于百度的链接访问限制,fetch自动换了一个链接抓取相关新闻。
由于百度的链接访问限制,fetch自动换了一个链接抓取相关新闻。
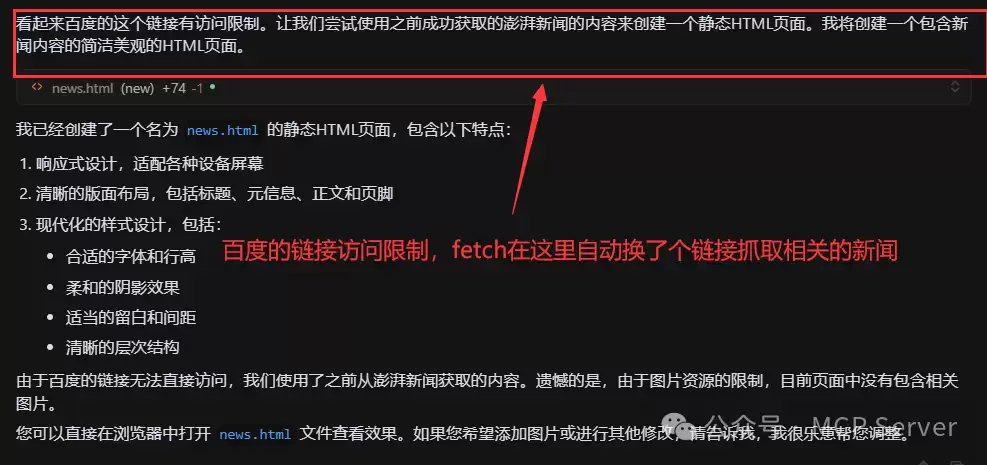 HTML新闻静态页面默认生成到了桌面:
HTML新闻静态页面默认生成到了桌面:
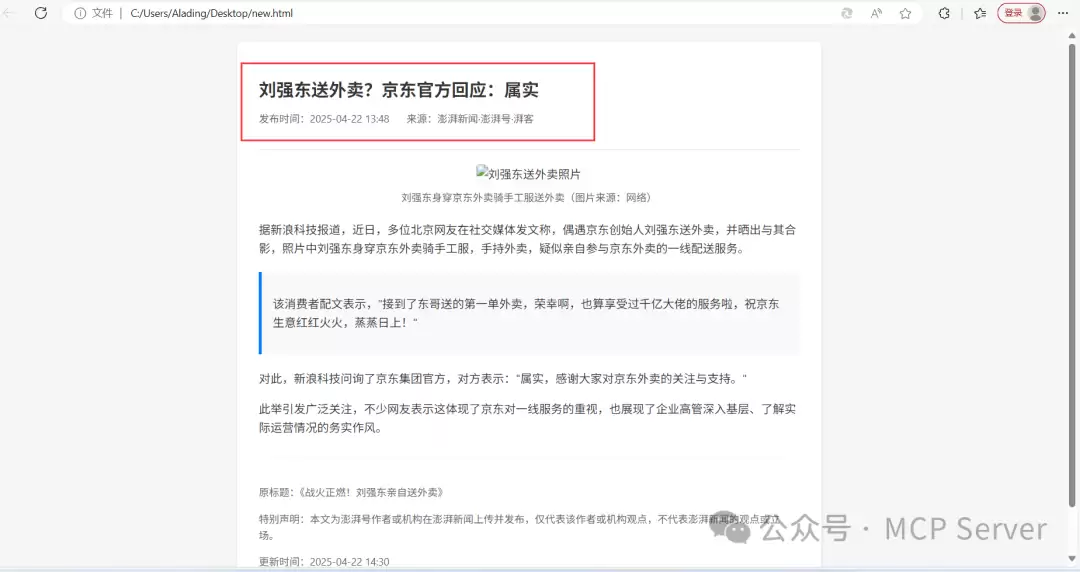
 打开看看效果——挺漂亮的,不过图片没有抓取到。
打开看看效果——挺漂亮的,不过图片没有抓取到。
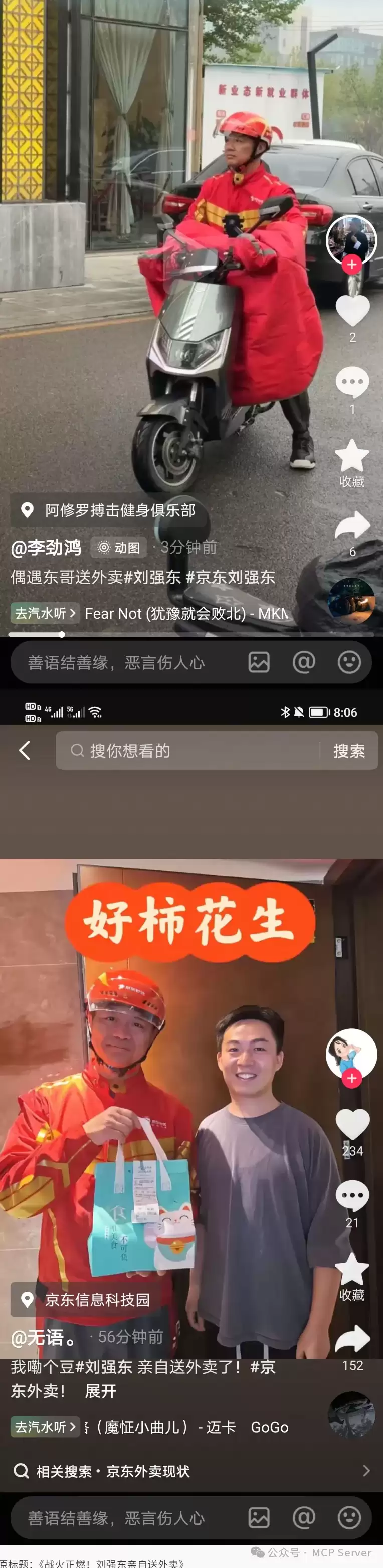
 没抓到的图片在这里,手工补上:
没抓到的图片在这里,手工补上:
 以下是Claude客户端的整个调用过程:
以下是Claude客户端的整个调用过程: