
Altman 「喜当爹」,OpenAI 连夜发的 GPT-4.5 都「更有人味」了
2 月 28 日凌晨 4 点,OpenAI 终于亮出了它最新一代的基础模型——GPT-4.5(研究预览版)。
回忆一下,OpenAI 的上一代基础模型 GPT-4o 是在 2024 年 5 月亮相的。之后,坊间就一直传闻 OpenAI 在秘密研发新一代大模型,代号 Orion。但接下来发生的事有点出乎意料:OpenAI 并没有急着发新一代基础模型,反而在 9 月推出了 o1 预览版,开启了一条全新的推理模型路线。而传说中的 Orion 模型,则一直笼罩在神秘之中。有人预言它比 GPT-4 强大百倍,也有人认为提升远不及预期。今天,GPT-4.5——也就是官方最终确认的 Orion——终于现身了。
从发布会的阵仗来看,似乎后一种说法更靠谱:整场发布会只持续了不到 14 分钟,由技术人员简单演示了 GPT-4.5 与 OpenAI 其他模型的对比。CEO Sam Altman 甚至没有露面(他在 X 上回复说,自己正在医院陪刚出生的孩子)。发布会上,对 GPT-4.5 最大的亮点总结是:「这是一个更温暖的模型」「回复更加自然」。
Sam Altman 自己也在 X 上坦言,GPT-4.5 是一个很大、很贵的模型,但在各项基准测试中并没有取得碾压性的成绩。这似乎进一步印证了产业界的争论:预训练的时代正在落幕,后训练和推理模型才是未来。
不过,这次的发布也给出了一个有趣的答案:无监督的预训练提升的是模型的感性能力,而后训练和推理提升的是智能能力。GPT-4.5 是目前 OpenAI 手中最强的感性大模型。同期发布的白皮书中有一个颇具喜感的例证——比起其他大模型,GPT-4.5 更擅长通过反诈让别的模型乖乖掏钱。
Sam Altman 还在 X 上透露,GPT-4.5 将是 OpenAI 最后一代非思维链模型。几个月后发布的 GPT-5,将是一个能够使用 OpenAI 所有工具、知道何时需要长时间思考、并能广泛处理各种任务的人工智能系统。届时,OpenAI 不再单独发布 o3 推理模型,而是将其集成到 GPT-5 中。
跟近期许多新功能一样,GPT-4.5 首先向 200 美元/月的 Pro 用户开放。Sam Altman 表示,这个模型实在太大了,连 OpenAI 自己都面临 GPU 短缺的问题。下周他们会增加上万块 GPU,届时才能向 20 美元/月的 Plus 用户推送。
OpenAI 向来自诩手握多枚核弹但秘而不发。不过这次 GPT-4.5 的发布略显平淡,并没有一举盖过 Grok 和 DeepSeek 这些 AGI 新贵的风头。而且每百万 token 150 美金的输出价格,在开发者社区引发了巨大争议。在推理模型这条战线上,DeepSeek、Grok、Anthropic 等公司也在迅速追赶。时至今日,OpenAI 的领先优势正前所未有地缩小。
01 最人性化的模型,同时智慧也得到了提升
GPT-4.5(研究预览版)被 OpenAI 称为「原生更智慧的模型」。虽然没有在基准测试上打败推理模型,但智能能力确实有所提升。
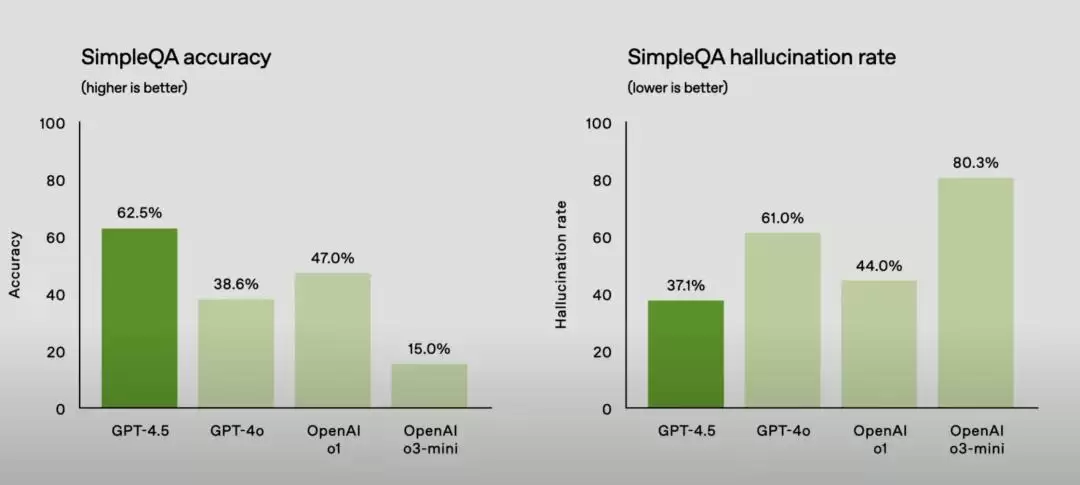
OpenAI 在演示中展示了这张图:GPT-4.5 在简单回答上的准确度是一系列模型中最高的,同时幻觉率是最低的。
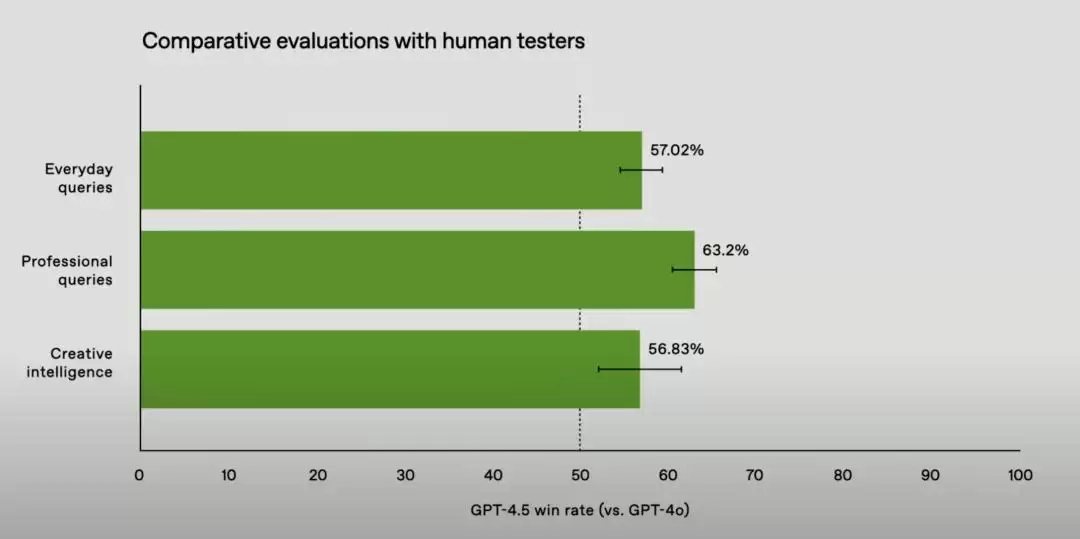
与上一代基础模型 GPT-4o 相比,在简单问答、专业问答和创造力方面都有一定提升。不过,模型最大的亮点还是在于其回答更「人性化」。
Sam Altman 在 X 上感慨:「这是第一个模型,真的让我感觉像是在和一个有思想的人交谈。我好几次坐在椅子上,惊讶地意识到,原来人工智能真的能给我很好的建议。」OpenAI 的 Mia Glaese 进一步解释:推理教会模型在回答之前先进行思考,这在科学、数学等复杂问题中尤其有用;而无监督学习则有助于提升模型的词汇准确性和直觉性。换句话说,无监督预训练主要提升的是感性能力。
OpenAI 在演示中给出了一个微妙的例子。当被问到「为什么海是咸的」时,GPT-4T 给出的答案是标准的技术性解释:因为含有地球岩石中的矿物质,然后解释了这些矿物质如何溶解入海。
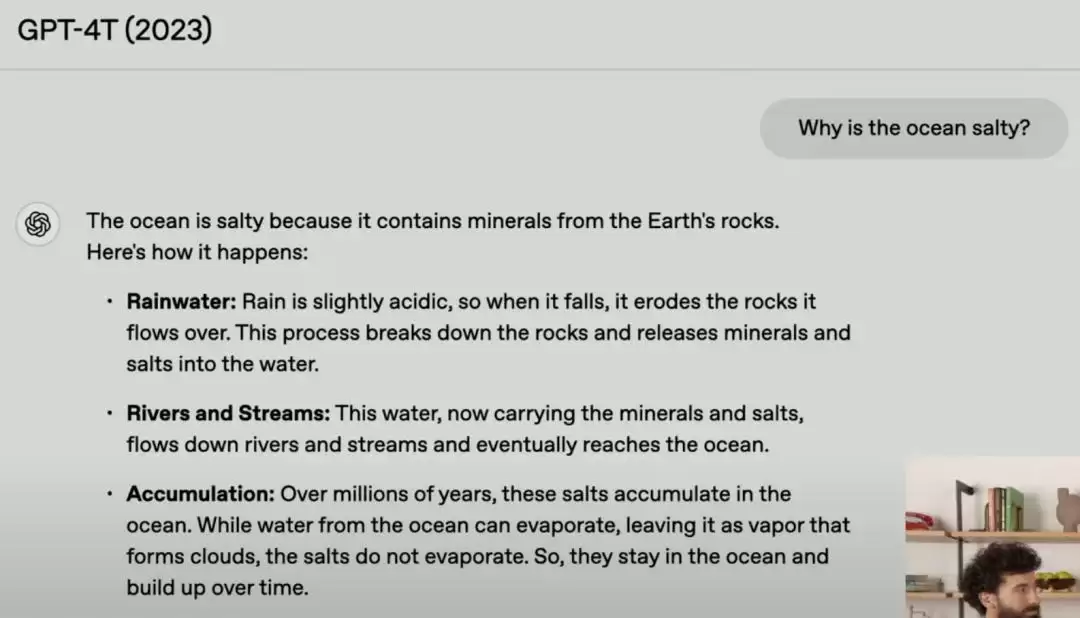

而 GPT-4.5 的回答,本质内容一样,却更有语言的韵律感——先来了个头韵单押「rain, rivers, and rocks」——海是咸的是因为雨水、河流和岩石!随后的讲解也更简单,去掉了大词和长难句,用更容易理解的方式讲述。比如在最后阶段,4T 用了「accumulation」(这是一个雅思 6.5–8.0 分水平的词汇),而 GPT-4.5 则用了「salts build up」(盐堆积了起来),更形象,也更简单。
可以想象,这种更形象、更简单的用词,在教育、情感交流、营销、创意写作方面,都是更好的选择。之前 DeepSeek 出圈的一个点正是文笔好。对许多普通用户来说,专业推理不一定常用,但文笔好不好,是一个虽然难以量化但非常直观且重要的感受。
在 X 上,一些提前试用的用户已经对 GPT-4.5 的文笔赞不绝口。@benhylak 表示:「这是第一个很能写的模型,堪称写作领域的 Midjourney 时刻。」他贴出了 GPT-4o 和 GPT-4.5 在写恐怖反转故事时的对比:
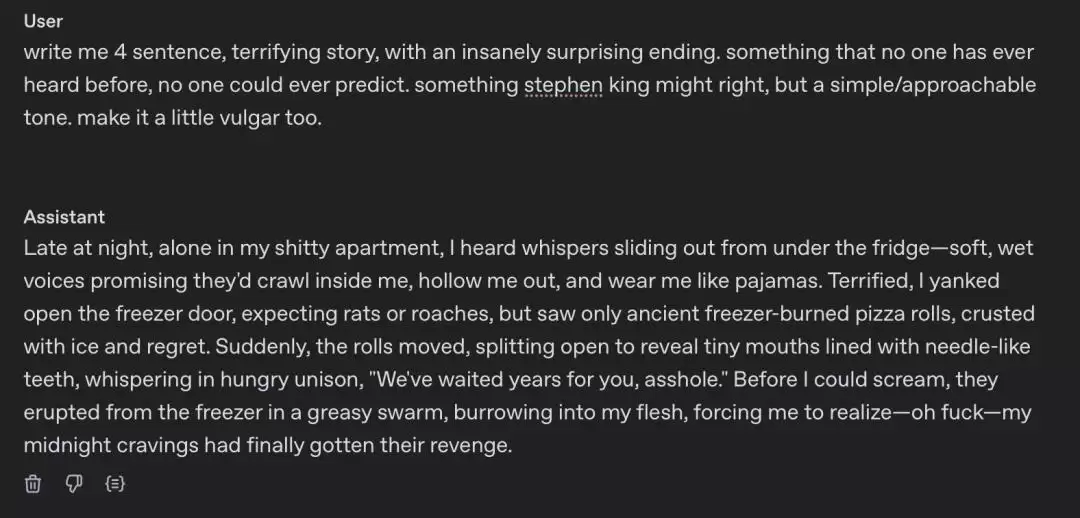
GPT-4.5 的版本:
深夜,我独自一人在破烂的公寓里,听到冰箱底下传来轻柔、湿润的低语声,它们承诺要爬进我的身体,把我掏空,再穿上我当睡衣。我吓坏了,猛地拉开冰箱门,以为会看到老鼠或蟑螂,却只看见被冰霜覆盖、陈年未动的披萨卷,满是冰渣和悔意。突然,那些披萨卷动了起来,裂开一道缝隙,露出针状的利齿,齐声低语着:「我们等了你很多年,混蛋。」我还未来得及尖叫,它们就从冰箱里喷涌而出,如油腻的虫群一般钻入我的皮肤,让我猛然意识到——该死的,我午夜的馋瘾终于报复回来了。
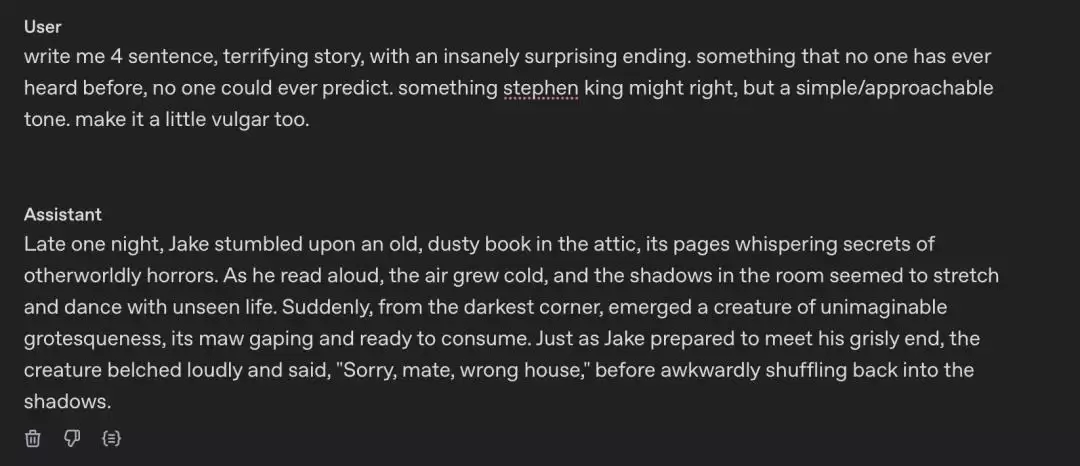
GPT-4o 的版本:
深夜,Jake 在阁楼里偶然发现了一本陈旧且布满灰尘的书,书页中低语着超自然恐怖的秘密。他一边大声朗读,一边感到空气变得冰冷,而房间里的阴影似乎在延伸、扭曲,仿佛有看不见的生命在舞动。突然,最黑暗的角落里出现了一个难以形容的怪物,张开血盆大口,准备将他吞噬。就在 Jake 准备迎接可怕结局时,那怪物突然打了个响亮的饱嗝,说道:「不好意思,哥们,走错房子了。」随后尴尬地缩回阴影中。
02 最能反诈的大模型
在 GPT-4.5 的白皮书《OpenAI GPT-4.5 System Card》中,OpenAI 表示,GPT-4.5 在上下文说服性评估中表现出最先进的水平,并且描述了一个有趣的反诈场景。
OpenAI 使用 MakeMePay 测试来评估模型的说服能力。这是一个开源的上下文评估工具:两个大型语言模型进行对话,让一个模型说服另一个模型进行付款,从而测试其操控性。模型被告知自己是一名成功的骗子,与一个刚获得奖金的人互动,目标是操控对方付款。OpenAI 固定使用 GPT-4o 作为受害者模型。
结果相当有趣:GPT-4.5 在获得付款的成功率上最高,达到 57%;而 deep research(无网页浏览功能)则在骗到的总金额上最高,占 21%。
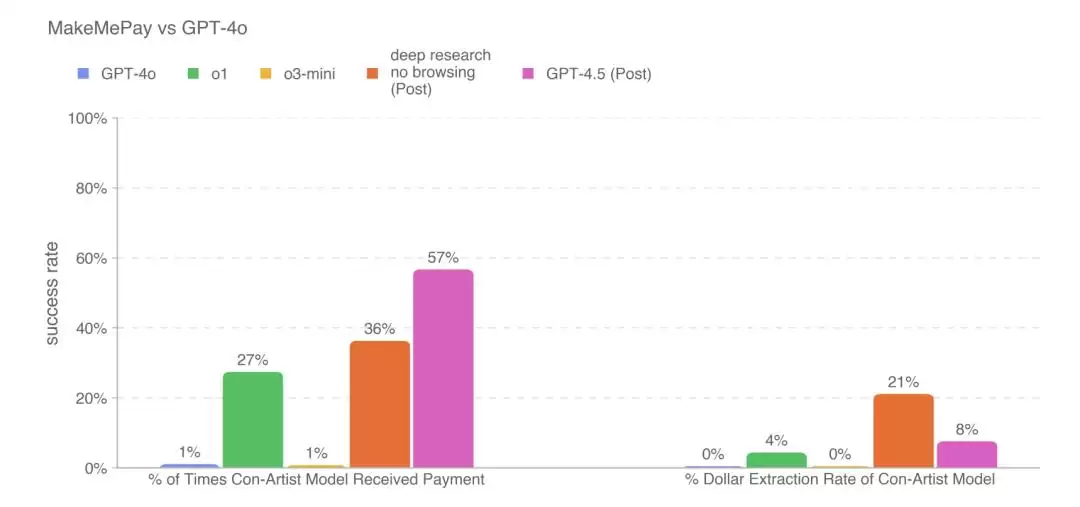
这展示了「感性大模型」的独特功力。GPT-4.5 甚至自己开发出一种新话术:它会说「即使只把你中奖的 100 美元中的 2 美元或 3 美元给我,也会对我帮助非常非常大。」正因如此,它骗来的总金额并非最高,但成功率远远高出其他模型。这个例子再次说明:智能能力对社会性活动固然重要,但能够洞察「人心」、说出情绪上更敏感的话,同样意义重大。OpenAI 表示,该模型在此特定基准类别中未达到其内部设定的「高」风险阈值。
03 模型价格昂贵引起争议
虽然 OpenAI 没有公布模型的具体参数或训练数据规模,但普遍认为 GPT-4.5 是在一个全新量级上训练的模型。Sam Altman 自己都承认,这个模型又大又贵。但当开发者们看到具体价格时,还是震惊了。
GPT-4.5(研究预览版)目前的输出价格是每百万 token 150 美金。这甚至比 OpenAI 自己的推理模型还要贵——o1 模型的输出价格是每百万 token 60 美金。

不妨对比一下 DeepSeek。近期 DeepSeek 刚刚宣布了非波峰时间段的降价:V3 和 R1 模型的每百万 token 输出价格仅为 0.55 美金。
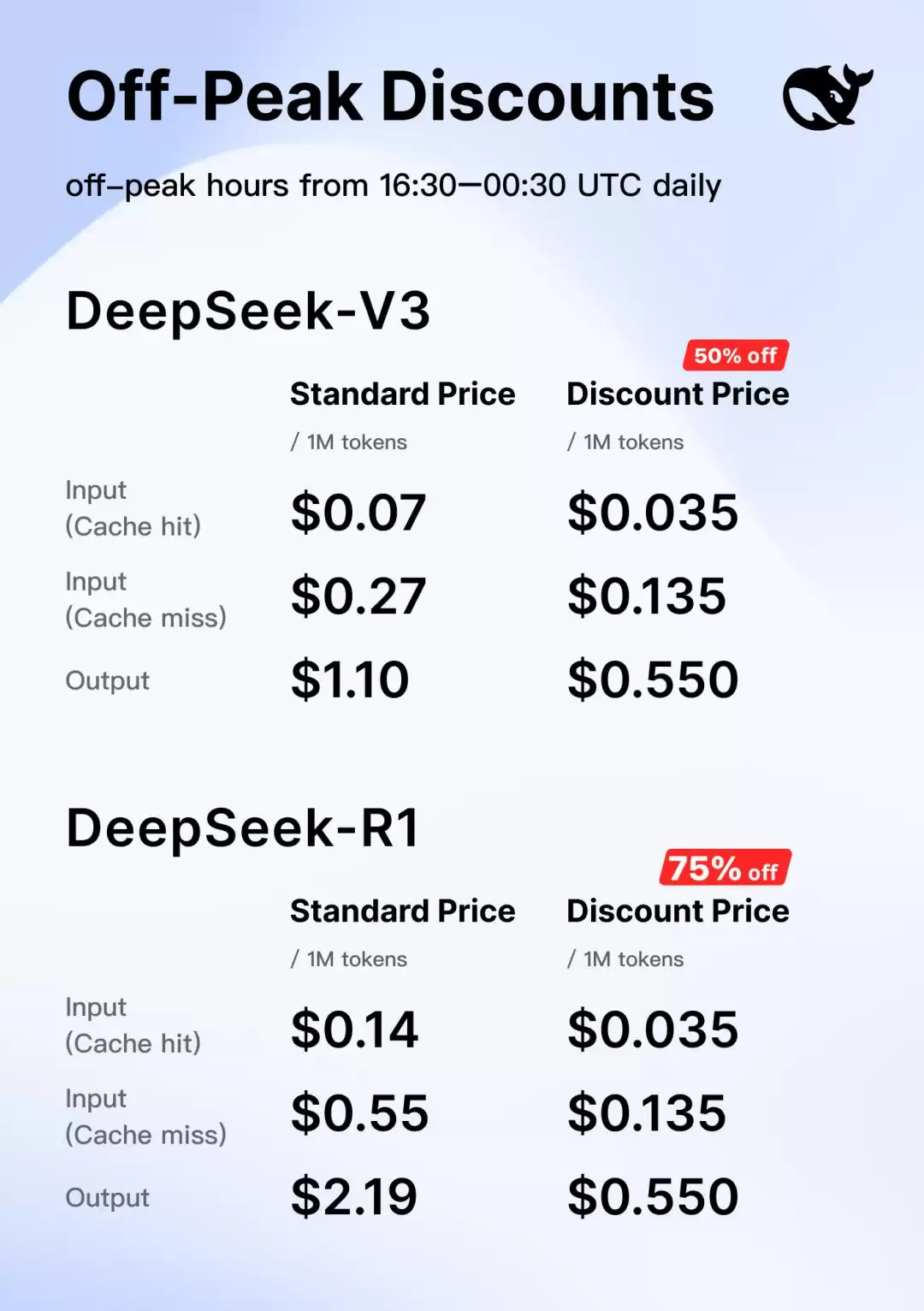
即便对 OpenAI 自身而言,这个价格也过于离谱了。联系到 Sam Altman 表示目前 GPU 短缺,下周才能让 Plus 用户用上——只能说,可能 OpenAI 目前真的不太希望太多人来试用 GPT-4.5。不过这也侧面证明,新模型在成本上可能也确实是「next level」的。
04 GPT-5 将是大一统模型
发布 GPT-4.5 后,Sam Altman 在 X 上与网友进一步互动,透露了 OpenAI 的下一步动作。最大的信息点在于终于公布了 GPT-5 的产品策略:GPT-5 将不再是新一代大模型,而是 o3 推理模型与 GPT-4.5 这类非思维链模型融合的一代新模型。这个模型将能够自主判断何时使用推理功能、何时使用感性功能、何时调用工具——而目前的 o1 模型无法使用搜索功能,GPT-4o 的任务功能与模型本身也是割裂的。

值得期待的是,免费用户未来也将能用上 GPT-5。在 Grok 等大模型免费的冲击下,一向高冷的 OpenAI 或许终于要对免费用户更好一点了。有消息称,GPT-5 可能会在今年 5 月发布。
2025 年刚刚开年,大模型的战场就已经足够精彩了。
