
开源的风吹到视频生成:阿里开源登顶VBench的万相大模型,一手实测来了
这段视频展示的是万相在文本对齐能力上的一个典型表现。为了呈现多元种族,画面中既有白人小哥,也有黑人小姐姐,他们跳舞、畅饮,即便是多主体的运动镜头,画面也没有崩坏,保持了相当高的稳定性。更值得一提的是,万相不仅理解中文指令,对英文同样处理得很好。

物理建模
让模型从海量视频数据中学习并内化物理规律,是所有视频生成模型共同追求的目标。道理很简单:一旦画面中间出现椅子凭空飞起这类违背常识的场景,观众立刻就能识别出“这是AI生成的”。万相大模型在这一维度的表现,让人看到了视频生成模型在理解物理规律上的实质性进展。
来看下面这个例子。我们给出的提示词是:“透明玻璃杯在桌面倾倒,牛奶缓慢流出,液体在桌面形成蜿蜒流动轨迹,微距镜头展现液体表面张力,写实风格”。从生成的视频中可以看到,模型不仅捕捉到了牛奶流到桌面后的动态痕迹,甚至考虑到了牛奶自身的粘稠度。杯壁的反光特性,以及牛奶与杯壁接触后留下的那层液膜,都得到了相当自然的还原。

再看下面这个草莓入水的视频,模型很好地处理了草莓和水之间复杂的相互作用力,水珠的透明质感也表现得非常到位。结合对特写和微距摄影技巧的运用,它几乎完整地呈现了草莓坠入水中的那一刻,那种稍纵即逝的物理之美。

提示词:一颗草莓坠入清澈透明的水中,草莓轻轻旋转下沉,特写镜头捕捉这一刻的动态美,微距摄影风格,强调水珠的透明感和草莓的鲜艳色泽。
万相大模型核心技术创新
那么,万相大模型是怎么实现这种生成能力突破的?本质上,要归功于两大核心创新:一个是高效的因果3D VAE,另一个则是视频Diffusion Transformer。
高效的因果 3D VAE
万相团队自研了一种专为视频生成设计的新型因果3D VAE架构。这套架构通过组合多种策略,在时空压缩效率、内存使用优化以及时间因果性保证上,都做了系统的改进。
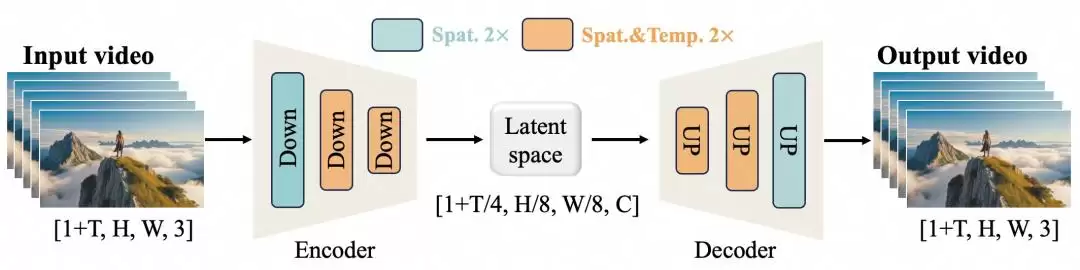
实验数据很能说明问题。在相同的硬件环境(单张A800 GPU)下,万相的视频VAE重建速度比当前最先进的方法(如HunYuanVideo)快了2.5倍,各项评估指标也展现出极强的竞争力。
视频 Diffusion Transformer
在整体架构上,万相采用了主流的视频DiT结构,凭借Full Attention机制来确保对长时空依赖关系的有效建模,从而实现时空一致的视频生成。模型的训练过程则采用了线性噪声轨迹的流匹配(Flow Matching)方法。
从模型架构图来看,它首先使用多语言umT5编码器对输入文本进行语义编码,然后通过逐层的交叉注意力层,把文本特征向量注入到每个Transformer Block的特征空间中,实现细粒度的语义对齐。另外,研究人员通过一组在所有Transformer Block中共享参数的MLP,将输入的时间步特征T映射为模型中AdaLN层的可学习缩放与偏置参数。实验发现,在相同参数规模下,这种共享时间步特征映射层参数的方法,在保持模型能力的同时,能显著降低参数量和计算开销。
配合可扩展的预训练策略、大规模数据链路构建以及自动化的评估指标,这套组合拳共同把万相大模型的最终性能推到了一个新的高度。
Qwen + 万相,阿里已实现全模态开源
把时间拨回到2023年。当时,如果有人说开源模型有机会追上闭源模型,恐怕很多人都会摇头。但正是在这种背景下,一些顶尖的AI公司毅然走上了开源的道路,Meta和阿里都是其中的典型代表。
两年之后,阿里的Qwen衍生模型数量已突破10万个,超越了Meta的Llama系列,成为全球最大的AI模型家族之一。更引人注意的是,在Huggingface最新发布的开源大模型榜单(OpenLLMLeaderboard)上,前十名全部被基于Qwen开发的衍生模型包揽——中国开源模型的活力由此可见一斑。
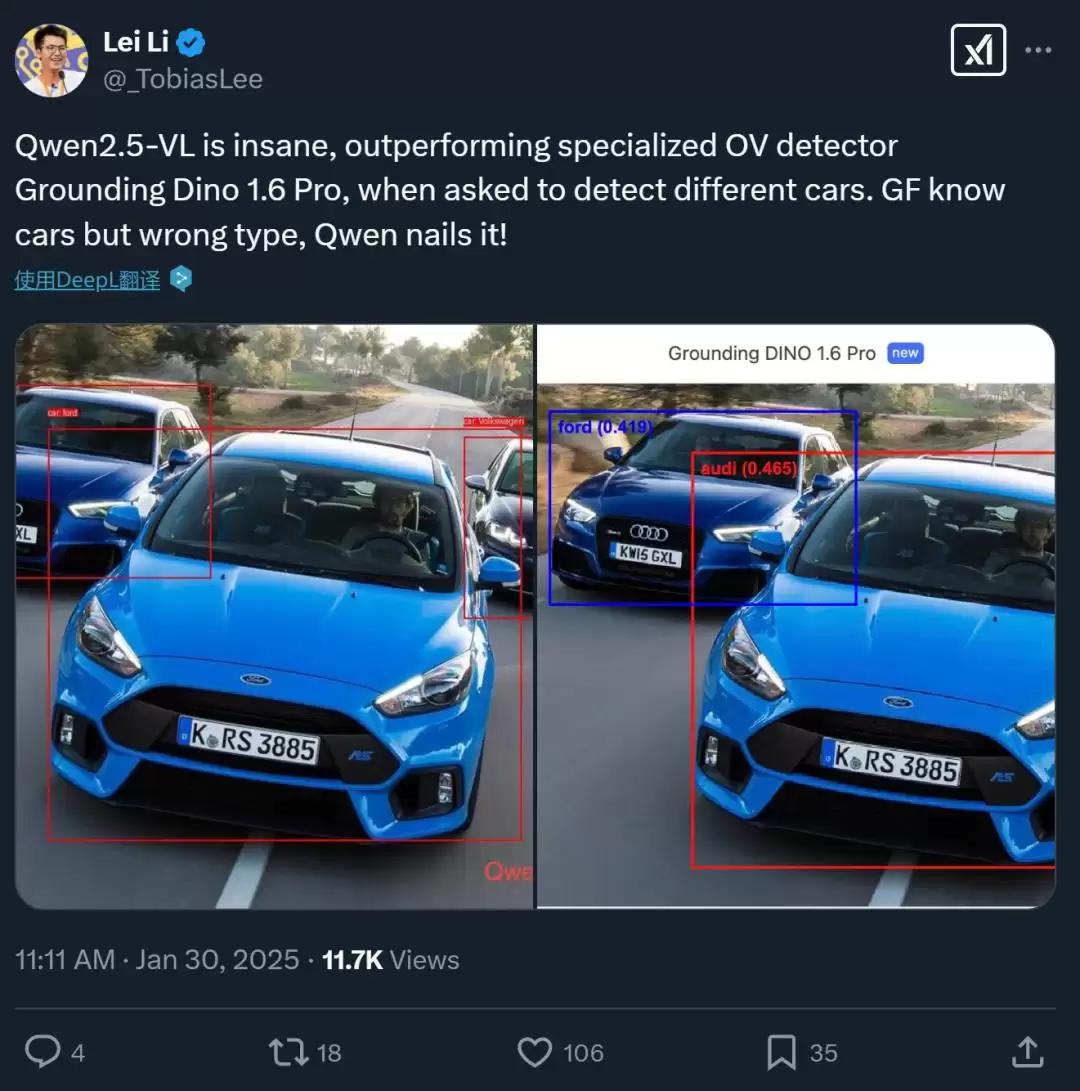
阿里的开源之路不止于语言。在多模态领域,它也处于领先地位:今年1月开源的视觉理解模型Qwen2.5-VL,一举拿下了OCRBenchV2、MMStar、MathVista等13项评测冠军,全面超越了GPT-4o和Claude3.5,在“开源不如闭源”的固有认知上撕开了一道口子。
如今,随着万相的开源,阿里的两大基础模型已经全部开源,实现了真正意义上的全模态开源,这在当前的AI巨头中可以说独树一帜。
目前,万相已经登陆GitHub、HuggingFace和魔搭社区,全面对接主流框架。从Gradio的快速体验到xDiT的并行加速推理,再到即将接入的Diffusers和ComfyUI,这个模型为开发者提供了相当全面的支持,既降低了技术门槛,也为不同场景的需求提供了灵活的解决方案。
阿里的开源大模型家族还在壮大,这确实值得期待。
