
用 DeepSeek 识别分析“TOP SQL”
在日常的数据库运维工作中,TOP SQL 是 DBA 们几乎每天都要打交道的话题。通常来说,那些执行频次高、单次耗时长、资源开销大的语句,往往会被认为是优化的优先级。但这里要思考一个问题:这些指标异常的SQL,就一定是需要优化的对象吗?
实际经验表明,如果一个系统的SQL执行状态是“稳态”的,哪怕它本身负载很高,也未必需要过于紧张。这种稳态运行下,它不会成为未来影响稳定运行的“X因素”。真正值得警惕的,反而是那些不稳定的、正在变差的语句,以及那些出现“毛刺”或“拐点”的语句——它们才是潜在的雷区。但遗憾的是,大多数常规监控平台和工具只能展示前者(稳态),而对后者缺乏有效的捕捉手段。
这篇文章想分享一个不同的思路:通过 DeepSeek 对日志文件进行分析,将过去需要复杂编程处理的任务,简化到只需用文字交互即可完成的阶段。换句话说,让AI帮你做数据分析,你只负责出想法。
1. 环境准备:模拟日志 + 文字交互
为了降低理解门槛,我们用最简单的模拟环境来演示。用BenchMark数据作为基础测试数据,同时运行两个小程序:一个模拟应用定时执行指定SQL,另一个跑BenchMark来制造系统噪声,最终将执行结果记录到两个日志文件里。每条记录包含两个字段:执行时间和SQL执行时长。两组数据分别对应“单独执行SQL”场景和“加环境干扰”场景,然后将日志上传给 DeepSeek。
先放上提示词,让DeepSeek干活:
提示词
上传文件是两组时序数据,针对这些数据进行分析并图形化展示。
要求很明确,包括数据格式(逗号分隔,第一列执行时间,第二列执行时长)、图形输出格式(HTML,带完整数据,铺满窗口,折线图光滑,两组数据上下分列且量程一致)。最终呈现的结果,直观展示了第一组数据执行平滑、第二组数据波动剧烈,后者是因为在执行过程中施加了环境干扰,导致语句执行时间明显增长。
2. 了解整体执行情况 — 统计分析
有了基础数据,先来个整体概览。这里借助DeepSeek的统计分析能力,用一组标准的统计函数对第二组数据做一次分析。
提示词
针对上面第二组数据,使用Python3分析其SQL语句执行特征,以图形化的方式输出,包括但不限于执行时长的平均值、中位线等指标。
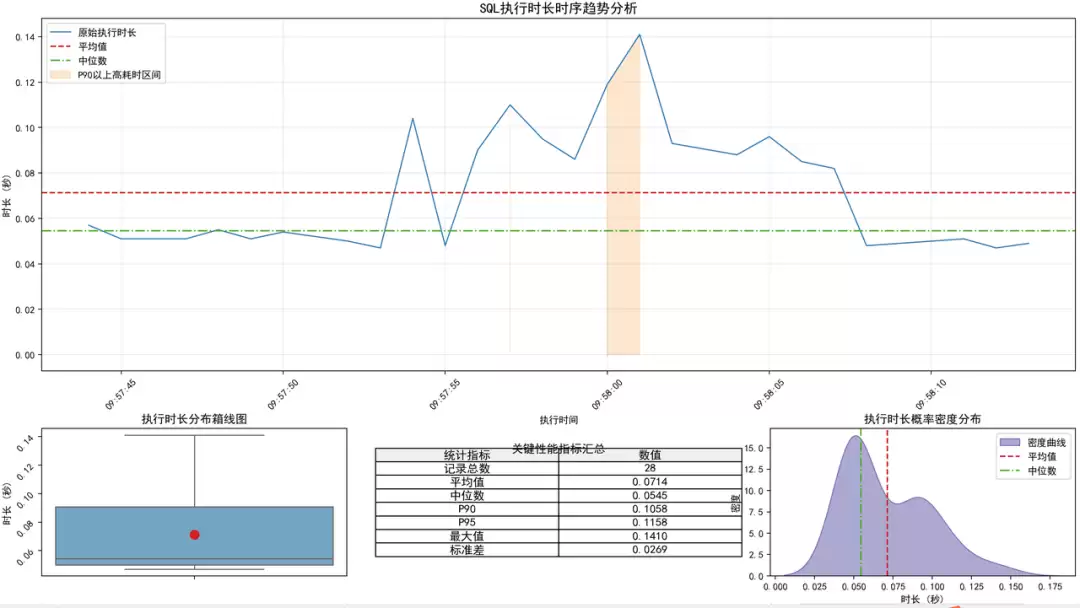
从DeepSeek给出的输出来看,信息量很丰富。除了运行时长、平均值、中位数这些常规指标,还包含了密度分布图、箱式图等。从中我们可以观察到一些关键特征:平均值大于中位数,意味着数据存在右偏分布,即少量的高耗时查询拉高了整体均值。另外,执行时长的密度分布图出现了双峰现象,说明系统中确实存在两种典型的执行模式——“快查询”和“慢查询”。
3. 反映运行稳定度指标 — 时间方差
方差(Variance)是衡量数据离散程度的经典统计量,用来反映数据偏离平均值的程度。方差越大,数据波动越大;方差越小,说明分布更集中,稳定性更高。在SQL执行分析的语境下,方差可以作为一个直观的“稳定度指标”来用。
低方差意味着执行平稳,高方差则说明执行时间波动大,可能存在偶发性性能问题,比如索引失效、锁竞争、资源瓶颈等。为了更直观地展示两组数据的差异,这里引入箱式图(Boxplot),它能展示数据的最大最小值、中位数以及上下四分位数。把两组执行数据提交给DeepSeek做方差分析,并让它用箱式图展示结果。
提示词
针对上面数据做方差分析,并将结果通过箱式图来展示。
结果非常直观:第一组数据的时间分布高度集中,第二组则明显发散,方差差异显著。这说明第二组在执行过程中间出现了明显的抖动。同时箱式图还附带展现了极值、中位数等常用统计指标,一目了然。
4. 找到语句运行“拐点” — PELT算法
拐点,指的是SQL执行特征发生前后剧变的时刻。通常这类拐点对应着性能恶化或恢复正常的场景。如何在大量日志中快速定位这些关键拐点,对于事后排查来说至关重要。DeepSeek在处理这个问题时,经过思考选择了PELT(Pruned Exact Linear Time)算法。
提示词
针对上面数据做拐点分析,并将结果图形化展示出来。
PELT算法的原理其实不复杂:它是一种高效的变点检测方法,通过动态规划结合剪枝策略,实现线性时间复杂度下的突变点搜索。算法以最小化分段成本加惩罚项为目标,递归地在时间序列中寻找最优的变点组合。这种算法特别适合处理金融波动分析、物联网设备监测等场景,在检测精度与计算效率之间做到了很好的平衡。
直接看实际应用效果。针对测试数据,PELT算法成功找到了两个关键拐点:第一个时间点,系统开始出现高延迟查询,平均执行时长从0.051秒飙升至0.097秒(上涨90%);第二个时间点,系统恢复正常,平均时长下降50%。从效果来看,PELT在数据库SQL性能分析中,就像一个智能巡检员——自动识别SQL执行过程中的异常波动时刻,帮助管理员快速定位性能瓶颈。具体来说,它的核心作用体现在三个方面:
- 通过扫描SQL执行时间序列,智能识别执行时长突然飙升的时间节点,这些拐点往往对应缓存失效、锁竞争或索引缺失等典型问题。
精准捕捉突变时段。
- 相比传统阈值告警(比如固定0.1秒为慢查询),PELT通过动态惩罚机制能过滤掉日常负载波动,专注检测非正常的突变。
区分自然波动与真实异常。
- 一旦算法标记出异常拐点,管理员可以直接调取该时段的执行计划、资源监控日志,快速锁定是SQL写法缺陷、硬件瓶颈还是并发冲突所致。
提升根因分析效率。
5. 找到语句运行“毛刺” — 异常点检测
毛刺,是执行特征明显有别于绝大多数正常情况的异常点。这些点虽然出现频率不高,但用户体验上就是突然变得非常卡顿。事后排查时,这种毛刺常常让人无从下手。DeepSeek对此的处理方式是采用多维算法融合机制进行异常点检测:Z-score、滑动窗口统计和孤立森林三重策略组合,逻辑或的关系共同判定异常点。
- 基于正态分布假设,计算每个执行时长与整体均值的标准差距离,能识别突破3σ阈值的全局离群点。
Z-score
- 动态计算局部均值与标准差,适合捕捉持续较长时间的异常窗口,比如缓存失效引起的连续性高延迟。
滑动窗口法
- 通过构建随机二叉树快速隔离异常路径,对非高斯分布的隐蔽异常有独特的敏感性。
孤立森林
需要注意的是,初始点存在被误标为异常的情况,这是由于算法对早期孤立波动的敏感性导致的。整体上看,这种机制在实际业务场景中能有效识别三类典型问题:索引失效引发的全表扫描(Z-score异常),锁竞争导致的持续阻塞(滑动窗口连续异常),以及内存泄漏引发的渐进式性能劣化(孤立森林异常)。可视化模块中的95%分位线和异常热力图,让DBA能快速定位出现异常的时间段。
6. 物以类聚,有的放矢 — 聚类分析
前面讲的都是针对单条语句的分析,但实际场景中,我们往往需要面对的是全量语句特征的分析。聚类分析在这里就派上了用场。它是一种无监督机器学习方法,旨在根据数据特征的相似性将样本划分为若干簇,同一簇内的样本高度相似,不同簇之间有显著差异。
在SQL分析场景中,选取执行频次(单位时间执行次数)和平均执行时长作为特征,通过标准化处理消除量纲差异后,利用聚类算法将SQL语句划分为不同的执行模式类别。模拟场景中,我们准备了四类SQL语句的日志文件(sql1、sql2、sql3、sql4),让DeepSeek按执行频次和执行时长两个维度做聚类分析。
结果清晰地将SQL分成了三类:
- (如sql2):频繁执行但耗时短,重点是确保其执行计划稳定,避免索引失效或资源争用。
高频低耗型
- (如sql3、sql4):执行次数少但单次耗时长,应是优先优化的对象,可通过重构查询逻辑、添加索引或缓存结果来处理。
低频高耗型
- (如sql1):频次和时长均居中,需要监控潜在的性能劣化风险。
过渡型
聚类结果直观展示了不同SQL的性能影响权重,也指导DBA按“低频高耗 > 高频低耗 > 过渡型”的顺序来制定优化计划,从而最大化投入产出比。当然,聚类分析的效果依赖于特征选取(比如是否增加峰值时长、资源消耗指标)和簇数设定(通常用肘部法则选择最佳K值)。另外,一定要结合业务场景来解读结果,避免单纯依赖数学划分而忽略实际语义。比如,一个低频率的高耗时SQL,可能是某个关键报表查询,这时需要保障它的稳定性,而不是一味追求缩短时间。
综合来看,聚类分析为SQL优化提供了一个科学的分类框架,帮助DBA从海量日志中快速定位重点问题,也算是实现数据库智能调优的一个实用手段。
