
智能运维新时代:如何打造你的专属知识库
智能运维知识库的构建秘籍,助力企业数字化转型。
核心内容:
1. 智能运维知识库的重要性与构建难点
2. 运维知识库构建的步骤与技术路径
3. 大语言模型在运维知识库中的应用优势
引言
知识库,听起来是一个挺老的概念——说白了一个组织或机构用来集中存储和管理知识的系统。它就像一个结构化的知识管理工具箱,专门用来收集、整理、存储和分享文档、手册、指南、案例等等。核心目标只有一个:让知识随手可得,让工作效率真正提上来。尤其到了运维领域,这事儿就更关键了。
一、构建运维知识库的难点和优势
传统知识库怎么建?说起来并不复杂:先确定范围和目标,再收集整理资料,然后组织结构和分类,选一个趁手的工具平台,接着设计界面和搜索功能,再建个维护机制,最后就是不断迭代改进。就这么几个步骤。
落到运维这个具体场景,知识库里通常要装些什么?系统架构图、拓扑图、配置文档、操作手册、故障排除指南、备份恢复策略、性能优化建议、更新维护日志、常见问题解答……说白了,就是运维团队要干的所有事儿的知识底座。有了它,团队能快速理解系统、处理故障。
构建运维知识库的难点
但真正动手去建,就会发现到处都是坑。第一关:知识整理与分类。海量的信息要分门别类,分类标得不对,后面检索就是灾难。第二关:更新和维护。知识库像活物,必须定期加新内容、改旧的、删过时的,否则就成了没人看的僵尸库。第三关:用户体验和搜索。界面好不好用?搜起来快不快?这些直接决定了运维人员愿不愿意用。第四关:安全和权限。不少运维资料涉及内部敏感信息,怎么既开放又保密?得有精细的权限控制。
运维知识库与大语言模型结合的优势
传统方案磕磕绊绊,但大语言模型(LLM)的出现给了新思路。通过对大规模文本的训练,LLM能理解语言、生成文本,在自动问答、摘要、语义分析上大放异彩。把它跟知识库结合起来,能带来几个实打实的优势:
- :LLM可以从语料里自动识别实体、关系和概念,帮忙构建分类结构和标签。
自动化知识提取和分类
- :用户问什么,模型就能直接回答——在运维场景里,这意味着秒级精准定位知识点。
自动问答和问题解答
- :长篇技术文档,模型能提炼出核心信息,帮运维人员快速消化。
文本摘要和知识提炼
- :把相似文本归到一起,还能做关联推荐,方便运维人发现隐藏的知识链接。
聚类和关联分析
- :模型生成的内容和人工整理的知识互补,覆盖更广,质量更高。
知识增强和补充
头部企业在这方面的积累很深。他们手里有海量且高质量的运维数据集,覆盖信息安全、应用程序、系统架构、软件架构、中间件、网络、操作系统、基础设施、数据库等常见领域。每个领域又细分为多个任务,比如运维知识问答、部署、监控、故障诊断、性能优化、日志分析、脚本编写、备份和恢复。在这些高质量数据的基础上,再结合企业内部的私域运维数据,就能快速搭建起基于LLM的运维知识库,让运维解决问题的能力直接上一个台阶。
二、构建运维知识库的技术路径
运维知识库的整体建设方案
运维知识库的建设方案分四步走,如图1所示。
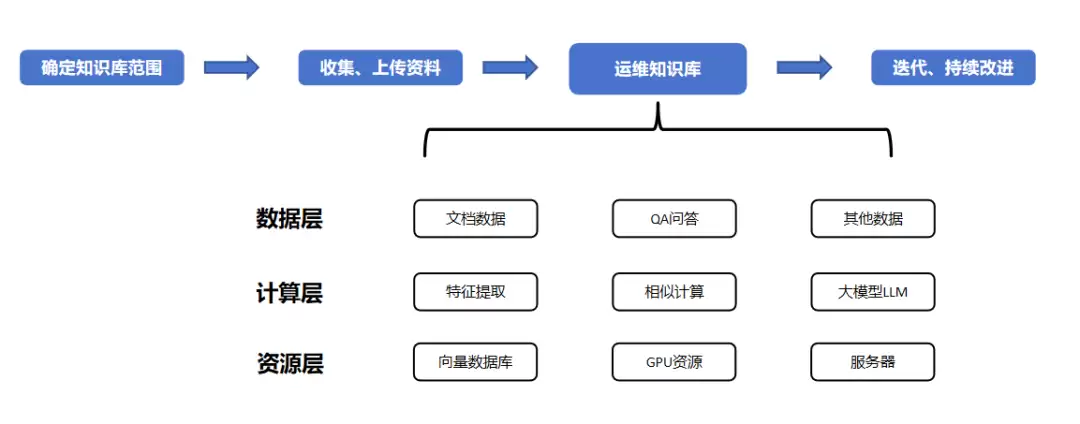 图1 运维知识库的整体建设方案
图1 运维知识库的整体建设方案
第一步,需求分析:明确知识库的目标、范围和受众。第二步,数据收集:从企业内外部的各种来源获取文档。第三步,制定方案:做数据预处理,把文档拆分和存储,让大语言模型能更好地理解;然后部署模型并调度算力,充分利用已有资源。第四步,迭代更新:定期评估和优化,别想着一次建好就能用一辈子。
文档结构化拆解算法
建知识库时,数据大部分是文档——docx、pdf、txt、csv……样式多变、质量参差不齐。怎么处理这些文档,直接决定了问答效果好不好。关键在文档结构化拆解算法:必须充分识别并理解文档的语义和结构信息。
通常的做法是从标题层级做精确分割,同时保留上下文和结构信息。这种方法特别适合报告、教程这类结构化文档,能提升文本向量化的效果。面对海量知识,算法必须考虑整体上下文和文本内部句子之间的关系,才能产生更全面的向量表示,帮模型抓住更广的含义和主题。相关的拆解步骤如图2所示。
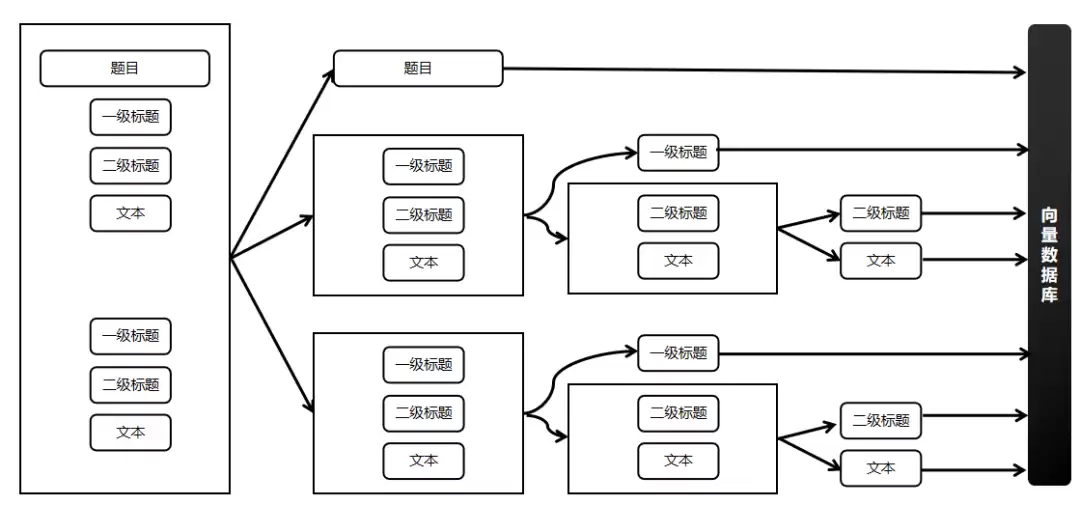 图2 文档拆解步骤
图2 文档拆解步骤
另外,为了应对多步推理的需求,业界也在探索能否动态选择那些高频、典型、重要的路径——这些路径很可能在后续问答中被反复用到。基于这个思路,出现了基于路径的剪枝方法,能在空间和计算资源上取得更好的平衡。
很多企业实践中发现,他们已经部署了自己原有的知识库系统,比如Wiki、Confluence等。经过多年积累,这些系统里沉淀了大量内部知识。出于使用习惯和数据安全考虑,企业往往不愿意迁移。好消息是,大语言模型可以直接对接这类内部知识库,对相关结构化文档进行拆解。具体流程如图3所示。
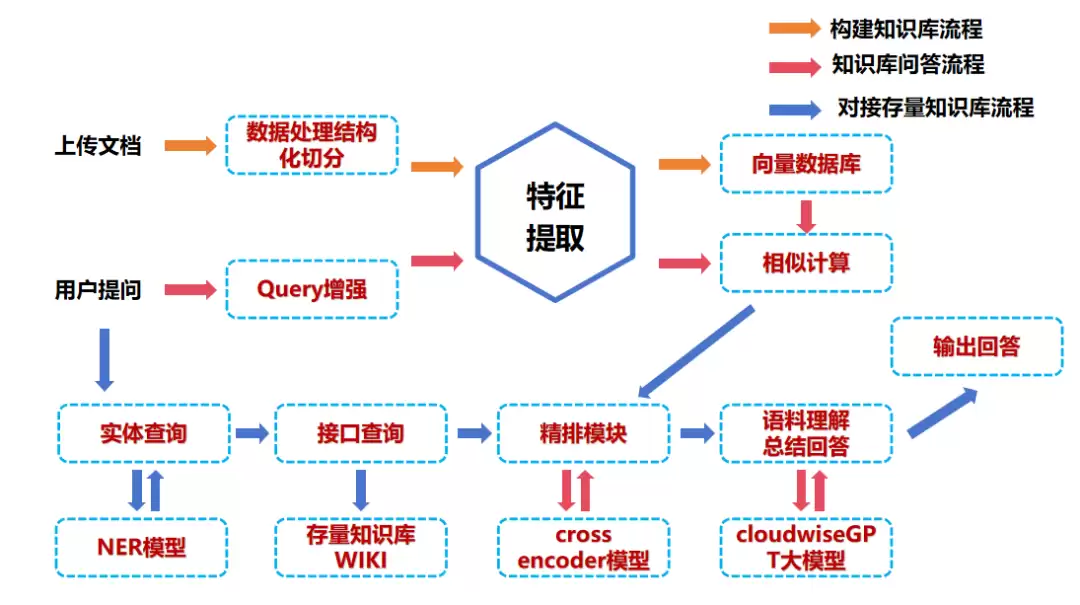 图3 结构化文档的拆解流程
图3 结构化文档的拆解流程
一个完整的运维知识库建设过程包括三个主要流程:构建知识库流程、知识库问答流程、对接存量知识库流程。
在构建知识库阶段,利用结构化拆分算法对用户上传的各类文档(docx、pdf、txt等)进行切分和存储。然后用一个embedding小模型把拆分后的文档片段向量化,存入向量数据库。
在知识库问答阶段,用户输入的问题会先做“Query增强”处理——利用大语言模型对问题进行扩充,以便检索到更多相关文档片段。接着基于结构化拆分算法,查找对应片段的上下文。得到充分的文档片段后,再经过一个精排模型筛选排序,过滤掉干扰信息。最终将这些文档片段加上精心设计的提示词(Prompt),调用大语言模型生成回答,返还给用户。
在对接存量知识库时,利用外部知识库的检索接口特点,先对用户输入做实体识别(使用NER模型),提取出关键词,然后调用存量知识库的检索接口获取对应文档内容。
智能运维知识库的构建意义重大。虽然建库之路困难重重,但融合大语言模型的优势,再借助合理的整体建设方案和精细的文档结构化拆解算法,足够让蓝图落地。它正在重塑运维生态,把知识整合成真正的智能交互。展望未来,随着技术和业务的发展,它还会持续进化——深化与前沿技术的协同,拓展知识边界,甚至预判问题,助力运维人员开展创新,把企业数字化推向新高度。
