
5.2k星星爆火开源!你的知识库迎来了史诗级更新,「像素级原生搜索」来了
为什么你需要像素级搜索?传统RAG的痛点
做知识库都要用到RAG,之前的做法是先把网页、PDF、文档解析成文本,再切块、向量化、检索、交给大模型回答。这个流程对纯文本内容很有效,但一旦遇到表格、图表、版式、信息图、复杂网页布局,就很容易丢失关键信息。
人类理解网页时是看页面,为什么AI检索一定要先把页面拆成文本?PixelRAG把网页和文档渲染成截图,再基于图像内容进行检索,让模型保留页面原本的视觉结构。
PixelRAG 核心原理:以截图替代文本解析
PixelRAG是一个像素原生的开源视觉RAG项目,把网页、PDF、图片等文档渲染成截图切片,并直接对这些图像建立向量索引和检索,从而让大模型能够利用表格、图表、布局、信息图等传统文本解析容易丢失的信息来回答问题。
不仅按文本内容搜索文档,还能按文档看起来是什么样
功能特点
1. 以截图替代文本解析
PixelRAG的核心不是先把网页HTML或PDF解析成纯文本,而是把页面渲染成截图切片。这样可以最大程度保留页面原始的视觉信息,比如表格结构、图表位置、页面布局、字号层级和信息密度。
2. 更适合处理复杂视觉文档
传统RAG在处理复杂表格、图表、论文截图、仪表盘、网页报告时,经常会因为解析失败或结构丢失而答错。PixelRAG通过视觉检索,让模型看到更接近人眼观察到的页面内容,特别适合处理视觉结构强的知识材料。
3. 支持网页、PDF和图片等多种输入
项目提供pixelshot命令,可以把网页、PDF、本地文件渲染成截图tiles。用户可以对单个网页截图,也可以把本地文档批量转成可检索的视觉数据。
4. 内置完整检索流水线
PixelRAG不只是截图工具,还提供从文档渲染、切块、嵌入、构建FAISS索引到启动搜索API的完整流程。
5. 使用视觉嵌入模型进行检索
使用经过网页截图数据LoRA微调的Qwen3-VL-Embedding模型,把页面截图嵌入到可检索的向量空间中。相比普通文本向量,这种方式更适合检索页面里的视觉内容。
6. 可作为 Claude Code 插件使用
PixelRAG提供pixelbrowse插件,让Claude Code可以通过截图方式查看网页,不是只读取网页HTML。这样AI就可以更好地理解网页里的图表、表格和页面排版。
DEMO 演示:2800万张维基百科的视觉检索
为了展示像素原生检索的威力,官方做了个很牛的演示,来证明这套方案行得通。
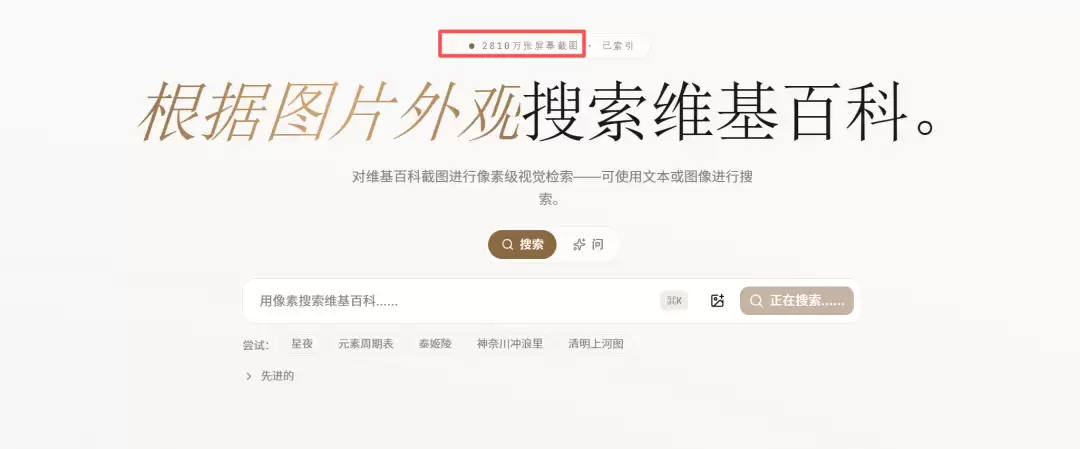
直接截了2800多万张维基百科的图片。
比如搜元素周期表,只要2秒
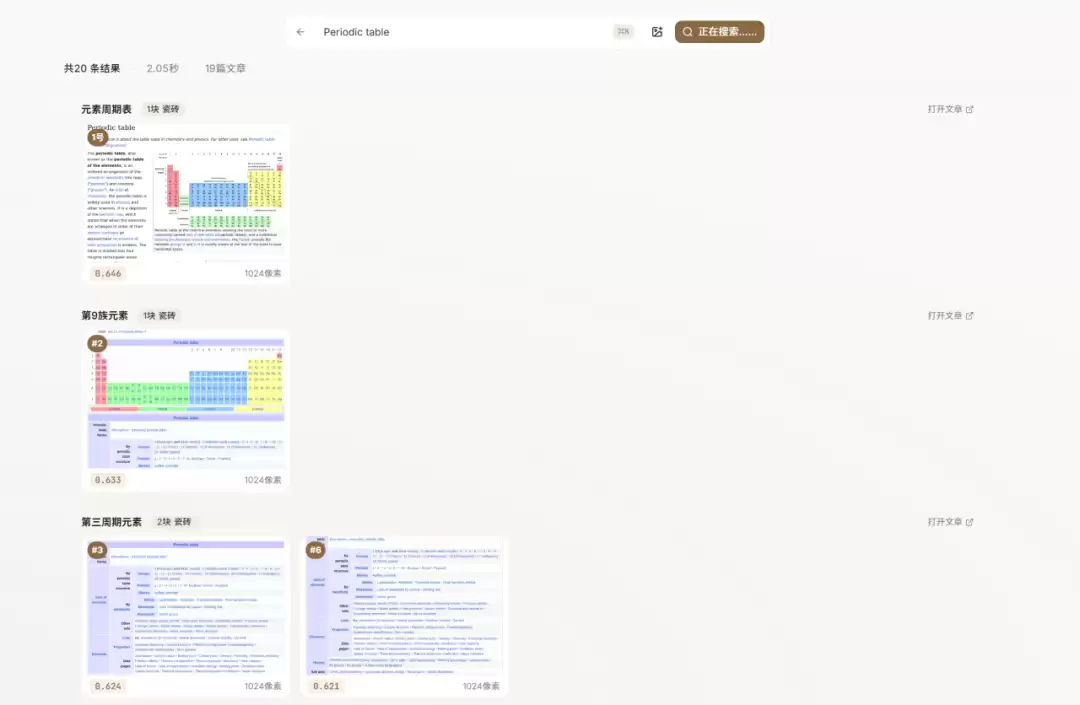
说这个方案更好,但不一定是更便宜,因为这2800w张图片的向量化不是我去做的,我也不知道成本如何。
传统RAG的那种信息、样式丢失的感觉真的很不好。现在直接就可以搜出来有样式的内容,就非常好。
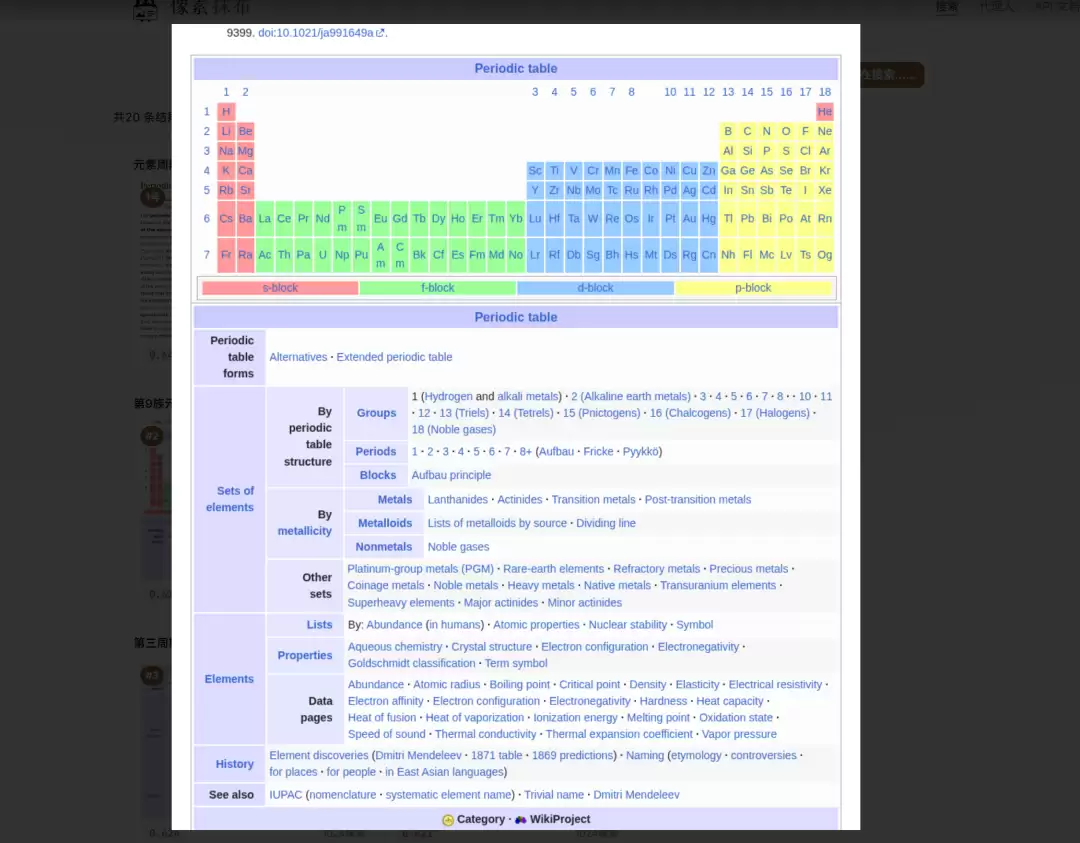
如果要对数据进行处理,就用视觉模型来做下一步了。
小提示
- :如果你的知识库中包含大量表格、图表、信息图、复杂网页截图(如产品说明、研究报告、学术论文),PixelRAG比传统RAG效果显著提升。
适用场景
- :截图切片需要一定的渲染能力(如使用Playwright或Puppeteer),建议在服务器上配置好浏览器环境。
部署注意
- :视觉嵌入模型(Qwen3-VL-Embedding)的向量化计算成本高于文本嵌入,但检索精度更高。对于小规模文档(几千页以内),成本可控。
成本权衡
- :安装
与Claude Code集成
pixelbrowse插件后,Claude Code即可“看到”网页截图,适合需要AI理解网页设计、数据可视化的场景。
常见问题
Q1:PixelRAG 是否支持所有类型的PDF或网页?
A:
Q2:PixelRAG 的检索准确率比传统RAG高多少?
A:
项目链接
https://github.com/StarTrail-org/PixelRAG