
京东和Open AI前CTO Mira Murati,押注了同一个AI赛道
试想这样一个场景:
一位独居老人在客厅不慎滑倒,疼痛让他无法呼救。此刻,他身上的智能设备或家中的摄像头“看”到了异常,AI没有等待任何语音指令,便主动发出预警,迅速联系了家人或急救中心。
或者,你正在观看一场激烈的足球比赛,关键进球发生的瞬间,你来不及回放和提问,AI眼镜便自动为你提供了慢动作分析和战术解读。
这些场景不是未来,而是京东刚刚开源的
全球首个全栈开源视觉语言交互模型——JoyAI-VL-Interaction

过去两年,大模型的能力边界被不断拓宽,但主流的交互方式仍停留在“用户提问,模型回答”的回合制逻辑。这种模式很高效,但问题在于,很多场景下它并不合理。那些重要的事件往往发生得太快,用户来不及提问;而那些真正需要帮助的时刻,有时连一句语音指令都没有。
今年,一个判断正在成为行业共识:AI正在从“预测下一个Token”,走向“预测下一个物理状态”。这意味着,AI需要从被动的信息处理者,进化为主动的参与者。
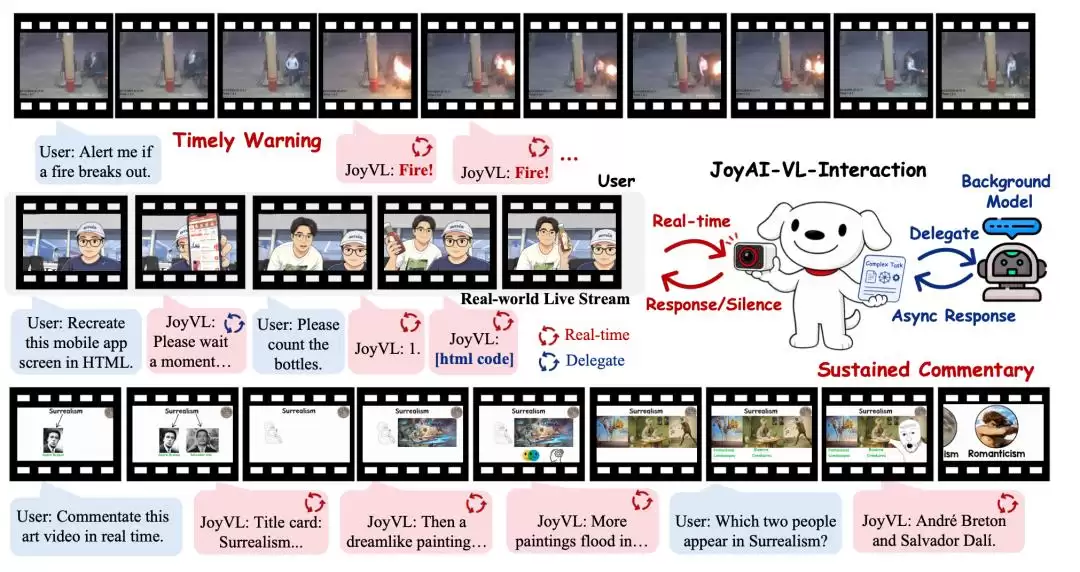
就在这个节点上,京东开源了JoyAI-VL-Interaction。它是全球首个全栈开源的实时视觉语言交互模型,能够在连续视频流中自主判断:何时回应、何时保持沉默、何时把复杂任务交给后台模型。
简单来说,JoyAI-VL-Interaction想证明一件事:真正进入物理世界的AI,不应该一直被动等待被问。它应该学会看见、主动判断,并在合适的时刻提供帮助。
这也是京东AI释放出的更大信号:从模型能力到产业场景,AI竞争正在从屏幕里的问答,走向真实世界。
为什么是视觉语言交互?
为什么是视觉语言交互?
在真实的物理世界里,大量关键信息都发生在用户来不及提问的时刻。这种“来不及”,有些时候是体验问题,但更多时候,是模式范式带来的能力边界问题。
行业并非意识不到这个局限性。2026年上半年,实时交互成了多模态AI最热门的关键词。行业大致沿着两条路线前进:一条是把回合制对话做得更快,另一条是让语音通话更自然。
前者强调低延迟或任意输入输出,但内核依然是“你问它才答”;后者让模型可以边听边说、随时被打断,体验更接近真人通话,但重心始终在语音场景。
问题在于,真实世界的大量变化并不会先变成一句话。火情、摔倒、车辆靠近、屏幕内容变化、生产线异常——这些事件都是画面先于语言出现的。AI如果只能等人开口,就很难真正“在场”。
值得注意的是,Mira Murati创办的Thinking Machines Lab几乎在同一时间做出了相同的判断。5月11日,这家公司提出了“interaction models”的概念,并发布了研究预览Demo,指出交互模型的自主响应范式,相较于传统一问一答,存在更大的想象空间。
两个团队同时收敛到同一种思路,这件事本身就值得关注:把交互性作为模型自身的能力来规模化,是行业未来几年绕不开的方向。
差异在于,京东把视觉语言放在了更核心的位置,将语音抽离成可插拔的输入输出模块,让视觉语言成为模型自主决策的“一等驱动模态”。
也就是说,从摄像头开启的那一刻起,JoyAI-VL-Interaction会持续“观看”物理世界的画面变化,并自主判断该不该开口、该说什么、该不该把任务交出去。
<iframe class="entity-iframe" style="height:250px;width:450px;" data-type="video" data-id="3866820375172097" scrolling="no" frameborder="0"> </iframe>
这也是视觉交互真正的想象力所在:它可以用于老人和儿童看护、盲人辅助、AI眼镜、赛事解说、门店巡检、仓储物流、机器人协作等场景。用户不需要先把问题组织成一句话,AI就能从环境变化中捕捉需求。
所以说,视觉不只是另一种输入方式,而是AI走向“预测下一个物理状态”时,不可替代的感知通道。
在京东JoyAI-VL-Interaction的技术报告里,这一点也得到了强化。报告显示,在六个真实流式场景中,JoyAI-VL-Interaction对阵国内头部模型胜率达77.6%,对阵国外模型胜率达87.9%;在最考验事件捕捉能力的监控预警场景中,胜率达到100%。报告认为,差距的核心不在于回答质量,而在于模型能否在正确的时刻行动。
不过,完成视觉主动交互确实更难。语音交互的数据获取相对直接,大量语音指令数据集让模型可以学习人类在什么时候说话、如何打断、如何接话。但视觉交互需要的数据完全不同——模型要学的是,在连续变化的画面中,什么信号值得回应、什么信号应该保持沉默。
<iframe class="entity-iframe" style="height:250px;width:450px;" data-type="video" data-id="3866821134734593" scrolling="no" frameborder="0"> </iframe>
更深的壁垒在于场景定义能力。语音交互有一个天然的触发边界——用户开口说话,就是交互的开始。但视觉交互没有明确的开始和结束,模型必须自己在无边界的信息流里判断边界。
京东的独特之处也正在于此:这家公司并不是在抽象实验室里寻找场景,而是天然运行在零售、物流、健康、工业等真实的业务网络中。这意味着,京东AI面对的不是单一聊天入口,而是海量的真实任务:货物如何流转,设备如何协同,机器人如何与人配合,异常如何被提前发现。模型可以在真实需求中学习,在真实反馈中迭代。
尽管技术路线有取舍,但未来通用AGI的交互形态一定是主动智能——智能体必须具备环境感知、自主决策和实时响应的完整循环。也正是因为如此,不少公司不是不想做视觉交互大模型,而是目前还缺少让视觉交互长出来的土壤。这也是为什么资本和算力先涌向了语音交互赛道。
所以,京东选择从视觉切入,不只是技术路线的选择,更是由战略位置决定的。相比许多大模型玩家,京东更接近物理世界的运营现场,也需要一种能主动感知和实时响应的AI。想让这一天来得更快,就需要有人出发得更早。
轻量、开源、可部署
轻量、开源、可部署
全球首个全栈开源,意味着什么?
重新定义交互范式,听起来宏大,但落到真实应用中,第一道门槛其实很朴素:AI不能总是打扰人,也不能在该提醒时沉默。
人们通常期待AI越能说越好,但在实时视觉交互的场景里,一个不停插话的模型并不聪明。真正有价值的能力,是在关键时刻主动出现,在无关时刻保持安静。
因此,JoyAI-VL-Interaction把“沉默”也训练成了一种能力。模型需要掌握三层判断:什么场景下应该主动响应,什么场景下应该保持沉默,什么场景下应该把任务分发出去,交给其他模型处理。
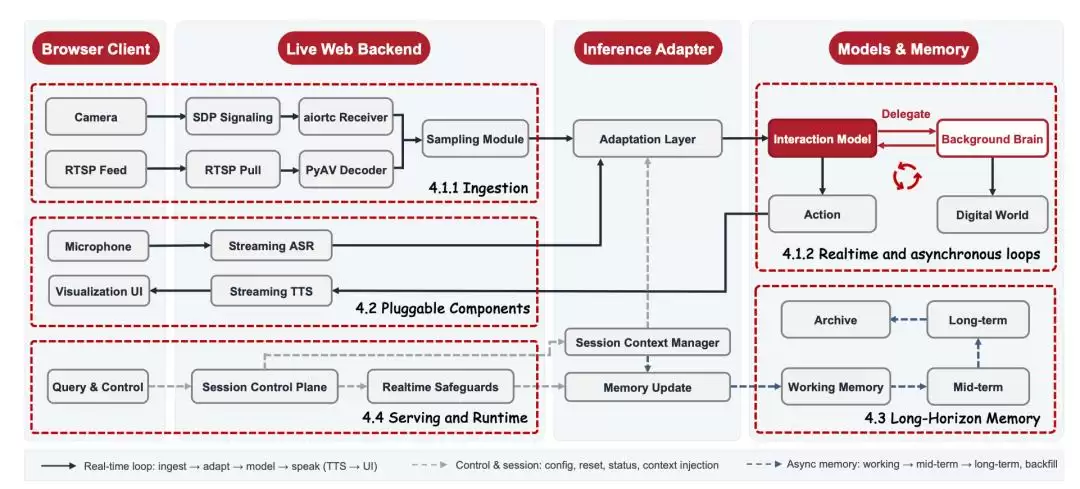
这套能力如果只能停留在论文里,价值无疑有限。京东此次强调“全栈开源”,关键就在于把模型、推理系统和应用搭建路径一起开放,让开发者能够真正跑起来、改起来、用起来。
京东选择的是更容易扩散的工程路线:8B参数模型,单张3090显卡就能完成部署。在这个参数下,个人开发者能跑、消费级硬件能承载、端侧设备能落地。
对于实时视觉交互来说,这种轻量化并不意味着能力缩水,而是分工更清晰。JoyAI-VL-Interaction更像一个前置交互层,负责看见环境、判断时机、完成简短沟通,遇到需要深度推理的复杂任务,就自动分发给后台用户自选的Agent(比如OpenClaw、Codex、Claude Code等)。所以,8B模型足够了。
举个例子:模型可以先对用户说“让我想想”,然后把难题交给后台,自己继续保持在场;后台返回结果后,再把答案同步给用户。在这个过程中,它还可以继续帮用户完成其他即时交互。
京东在底层系统上也做了轻量化设计:通过视频编码、长程记忆和上下文压缩,模型可以在较低成本下持续观看长视频流,并把端到端延迟控制在亚秒级。对普通读者来说,重点不是这些技术名词,而是结果:AI能更长时间、更低门槛地留在真实场景里。
高性价比、可落地的选择,也直接导向了京东的开源策略。只有模型足够轻量、系统足够完整、部署门槛足够低,实时视觉交互才可能从少数团队的实验,变成更多开发者和企业共同探索的应用生态。
京东已经开源了这套推理系统,目标很明确:让拥有3090及以上显卡和摄像头的任何人,都能快速搭建一套属于自己的实时视觉交互应用。
JoyAI-VL-Interaction获得了vLLM-Omni的day-0支持,已经原生合入vLLM-Omni主线。
让AI回到物理世界
让AI回到物理世界
开源的目的,是把应用想象力交给更大的市场。因为技术突破的价值,最终还是要由现实世界来检验。
JoyAI-VL-Interaction的第一批应用场景已经非常直观:赛事直播中,AI可以在关键进球或绝杀瞬间自动解说;股票盯盘时,它可以持续观察屏幕变化并提醒异常;家庭看护中,它可以在老人摔倒、儿童靠近危险区域时主动预警;搭配AI眼镜,它可以帮助用户识别道路、商品、屏幕和周围环境;服务视障人士时,它能把视觉信息转化为实时辅助。
对京东来说,更期待的是这些能力能落到机器人身上:一个懂得何时开口、何时沉默、何时求助后台系统的模型,能让机器人更高效,也更接近人们期待中的“有分寸感”的智能助手。
京东之所以敢在这个节点上“搅动”这个领域,根本原因在于它握着其他大模型玩家不具备的物理世界数据资产。放在2026年的行业坐标里,物理世界数据资产的分量格外重。
2026年被业界称为“具身智能数据元年”。但在这个宏大背景下,一个尖锐的矛盾浮出水面:高质量的物理交互数据极其稀缺,远不能满足大规模训练需求,算法迭代的瓶颈正从模型端全面转移到数据端。
正是在这个时间点上,京东宣布要在两年内积累1000万小时高质量真实场景视频数据,动员60万人参与采集。
京东拥有3000多个真实业务场景,覆盖零售、物流、健康、工业等领域。今年,还在宿迁创新出了社区网格采集模式,批量部署自研的JoyEgoCam头戴终端,动员周边中小企业和居民在真实作业场景里采集数据。
布局速度很快。3月,京东宣布在宿迁建成全球首个具身智能数据采集中心;4月,发布行业首个覆盖采、存、标、训、评、仿、测全链路的具身数据基础设施;5月,JoyEgoCam实现量产,持续采集第一视角数据。
这些数据,是训练具身模型和视觉交互模型最稀缺的燃料。随着具身数据加入训练,JoyAI-VL-Interaction的价值也会从“一个能主动看见的模型”,进一步落到机器人、无人车、仓储、门店和家庭等更具体的物理空间。
在模型与应用之间,京东在6月3日开源的JoyAI-Echo同样扮演着关键角色。Echo擅长长视频的实时生成,Interaction擅长实时理解与交互。一个月内连续开源两个模型,意味着京东已经打通了视频多模态的输入与输出两端,并把AI进军物理世界放到了更长期的战略位置。
今年618启动发布会上,京东说要做“全球最大物理世界运营中心”。在人机交互时代,行业越来越关注AI如何理解物理世界,而京东的解题逻辑与大多数大模型玩家都不同——这家公司本身就运行在物理世界之中。
仓储、配送、零售、健康、工业,这些都是AI和具身智能的训练场和试验场。仅仅是京东物流,五年内就将计划投入300万台机器人、100万台无人车、10万架无人机。这些硬件,也会成为JoyAI-VL-Interaction的用武之地。
无论是语音还是视觉,交互模型本质上就是为了连接物理世界和数字世界:理解物理世界,调度数字世界。
开源,则是京东向外打开的第一扇窗。在这个需求推动技术的赛道上,京东把模型、训练数据和完整系统一起放出来,赌的是一件更长远的事:让主动交互从少数团队的判断,变成AI走向物理世界的一条主航道。
