
聊一聊检索即推理:基于LLM-Wiki的自演化智能体原生检索
来源:互联网
时间:2026-06-25 13:04:11
好的,作为在AI和系统架构领域摸爬滚打多年的老兵,最近读到腾讯WeChat部门的这篇《Retrieval as Reasoning: Self-Evolving Agent-Native Retrieval via LLM-Wiki》(检索即推理:基于LLM-Wiki的自演化智能体原生检索),我确实觉得眼前一亮。这篇文章的切入点很准,它本质上是在“革传统RAG的命”。
怎么说呢?它指出了一个很直白的道理:现在的AI检索,很多时候就像“瞎子摸象”,只摸到一块碎片就急着下结论;而真正聪明的AI,应该像人一样去“逛维基百科”——边看边想,边想边点链接,如果搜不到就换条路继续找。
 ### 第一部分:这篇论文到底在讲什么
#### 1. 痛点:为什么现在的RAG搞不定“脑筋急转弯”
想象一下,你问一个需要绕好几道弯的问题,比如“《The Gamecock》和《Monster A Go-Go》的导演,谁更老?”。传统RAG拿到问题后,只会把“导演”和“电影名”这些关键词丢到向量库里比对。结果呢?它能搜出一堆关于这两部电影的介绍,但导演的**出生日期**这种关键信息,往往藏在导演的个人传记里。导演的名字跟电影名之间,语义距离太远了,向量检索根本捞不着。
结论很扎心:**问题不在于AI本身不够聪明,而在于你给它的“资料库”——那些被切得支离破碎的文本块,实在太死板、太扁平了。**
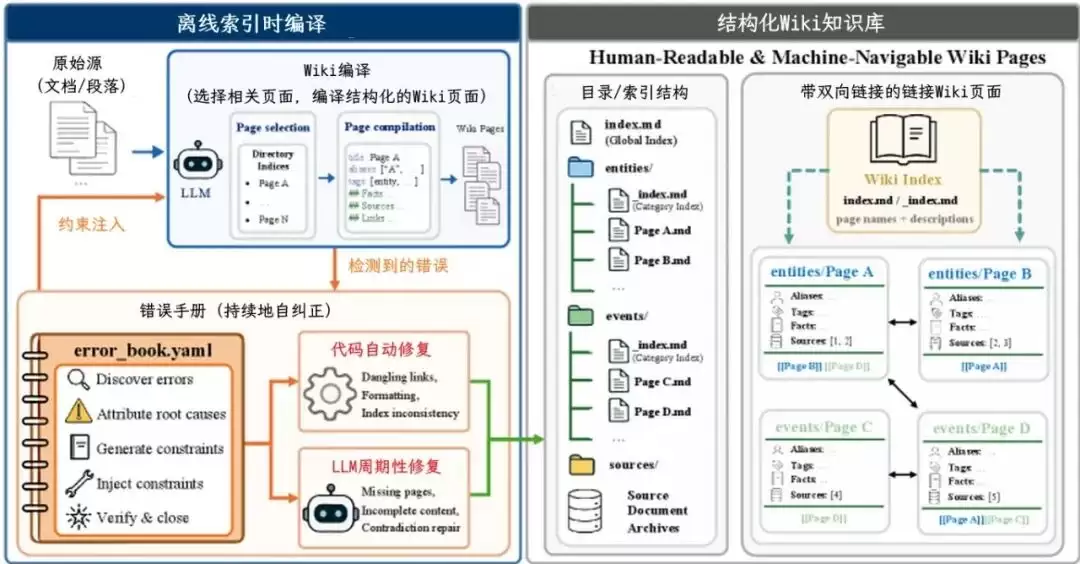
#### 2. LLM-Wiki的绝招:把资料库变成“活的维基百科”
LLM-Wiki的思路是,不再简单地把文档切成碎片。它直接让大模型当“总编辑”,把原始文档**编译(Compile)** 成一个带有双向链接的动态Wiki页面。
这个改变是根本性的:
* **以前**,你给AI的是一座散落在各处的文件堆,全是A4纸;
* **现在**,你直接给AI一个带目录、带超链接、带标签的**维基百科网站**。
每个Wiki页面里,不仅有具体的实体、别名、事实描述和来源引用,而且像`[导演](链接)`这样的信息,会非常显眼地变成可点击的跳转按钮,引导AI去挖掘更深层的信息。
### 第一部分:这篇论文到底在讲什么
#### 1. 痛点:为什么现在的RAG搞不定“脑筋急转弯”
想象一下,你问一个需要绕好几道弯的问题,比如“《The Gamecock》和《Monster A Go-Go》的导演,谁更老?”。传统RAG拿到问题后,只会把“导演”和“电影名”这些关键词丢到向量库里比对。结果呢?它能搜出一堆关于这两部电影的介绍,但导演的**出生日期**这种关键信息,往往藏在导演的个人传记里。导演的名字跟电影名之间,语义距离太远了,向量检索根本捞不着。
结论很扎心:**问题不在于AI本身不够聪明,而在于你给它的“资料库”——那些被切得支离破碎的文本块,实在太死板、太扁平了。**
#### 2. LLM-Wiki的绝招:把资料库变成“活的维基百科”
LLM-Wiki的思路是,不再简单地把文档切成碎片。它直接让大模型当“总编辑”,把原始文档**编译(Compile)** 成一个带有双向链接的动态Wiki页面。
这个改变是根本性的:
* **以前**,你给AI的是一座散落在各处的文件堆,全是A4纸;
* **现在**,你直接给AI一个带目录、带超链接、带标签的**维基百科网站**。
每个Wiki页面里,不仅有具体的实体、别名、事实描述和来源引用,而且像`[导演](链接)`这样的信息,会非常显眼地变成可点击的跳转按钮,引导AI去挖掘更深层的信息。
 #### 3. 智能体怎么干活?——“检索即推理”的两条腿走路
在这个新框架下,AI智能体不再是“一次性”检索。它手里握着两件核心工具(`wiki_search`和`wiki_read`),像侦探一样办案,整个过程充满了决策:
* **搜索优先路径**:先搜“The Gamecock”,在页面里找到导演名字后,立刻点击名字的链接跳转到导演的专属页面,去查他的出生日期。
* **浏览优先路径**:如果问题是开放式的,比如“这个系列有哪些作品”,AI会先去读目录索引(`_index.md`),对整个知识体系有个大概了解,再挑几个看着靠谱的页面细看。
* **核心精髓**:AI自己决定什么时候查够了(基于一个内部评估机制来判断“证据充分性”),什么时候该换个关键词再搜。这成功地把一次性的“查找”,变成了一次**多轮对话式的逻辑推理过程**。
#### 3. 智能体怎么干活?——“检索即推理”的两条腿走路
在这个新框架下,AI智能体不再是“一次性”检索。它手里握着两件核心工具(`wiki_search`和`wiki_read`),像侦探一样办案,整个过程充满了决策:
* **搜索优先路径**:先搜“The Gamecock”,在页面里找到导演名字后,立刻点击名字的链接跳转到导演的专属页面,去查他的出生日期。
* **浏览优先路径**:如果问题是开放式的,比如“这个系列有哪些作品”,AI会先去读目录索引(`_index.md`),对整个知识体系有个大概了解,再挑几个看着靠谱的页面细看。
* **核心精髓**:AI自己决定什么时候查够了(基于一个内部评估机制来判断“证据充分性”),什么时候该换个关键词再搜。这成功地把一次性的“查找”,变成了一次**多轮对话式的逻辑推理过程**。
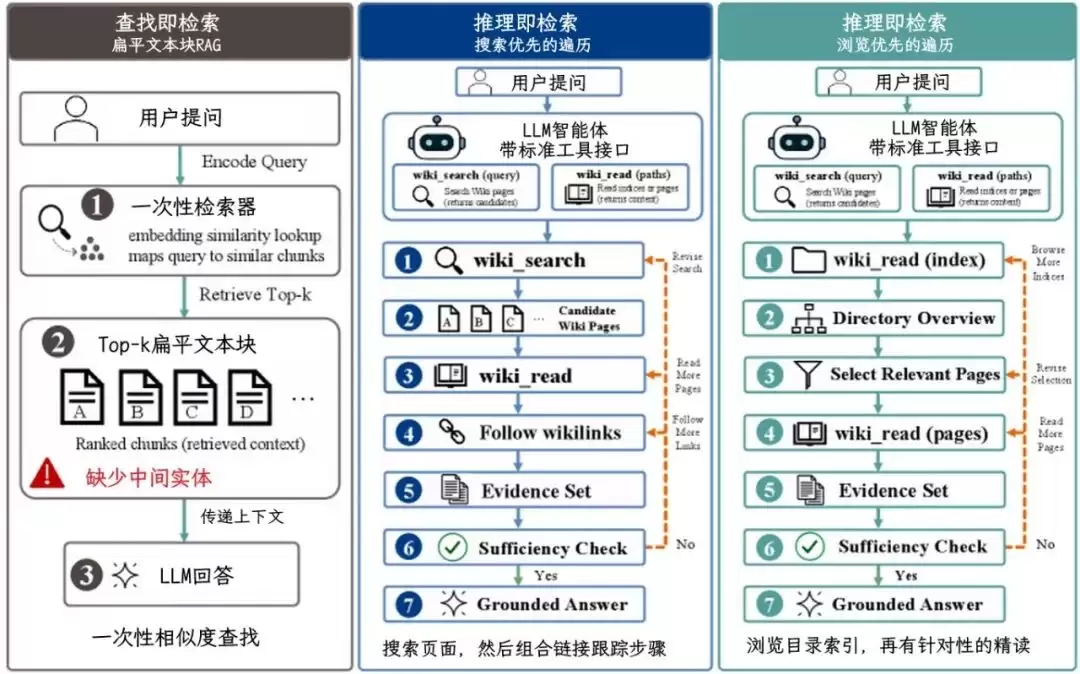 | 维度 | **检索即查找(老路)** | **检索即推理(新路)** |
| :--- | :--- | :--- |
| **检索次数** | **单次(One-shot)**,生死有命,富贵在天。 | **多轮迭代(Iterative)**,随时可以回头再来。 |
| **知识的形态** | **扁平块(Flat)**,所有文本被抹平,没有层级。 | **图结构(Graph/Wiki)**,有目录、有页面、有超链接。 |
| **AI的决策点** | **没有决策**,只有数学上的相似度计算。 | **处处是决策**,先搜还是先逛?读哪个页面?证据够了没? |
| **容错机制** | **无**,第一次错了,最终答案必然错。 | **有自愈性**,搜不到东西,AI会换个同义词再搜;读到的内容矛盾,AI会继续找第三方验证。 |
| **可解释性** | **黑盒**,你很难搞清楚AI为什么选那几段文字。 | **白盒(可追溯)**,AI的每一步操作(搜了谁、读了哪页、点了哪个链接)都有清晰日志,一目了然。 |
#### 4. 防崩坏机制:“错题本”(Error Book)让知识库越用越靠谱
这是整篇文章中最具工程智慧的一个亮点。大模型在编译Wiki时,难免会犯错,比如编造不存在的链接,或者不同页面里的信息相互矛盾。对此,论文提出了一个非常接地气的 **“错题本”**——一个YAML格式的规则文件。
这个“错题本”的工作流程如下:
* **发现错误**:在Wiki运行过程中,不断发现新问题,比如链接断了、某个事实没有依据。
* **归因并写成“约束规则”**:系统会分析错误原因,将其转化为一条精确的规则。例如:“严禁给目录里不存在的页面建链接”。
* **注入并修复**:当下次编译新文档时,这些规则会被写到Prompt里,警告大模型不要犯类似错误。同时,系统还会进行自动修复——代码层面修正格式,大模型层面定期处理语义矛盾。
这套机制形成了一个**持续集成的闭环**,保证了知识库不会因为不断灌入新资料而“熵增”腐烂。
### 第二部分:成绩单(实验结果说了啥?)
理论说得再好,也得看实战成绩。在HotpotQA、MuSiQue这些公认的“硬核”多步推理测试集上,LLM-Wiki相比最强对手LightRAG和HippoRAG 2,性能普遍提升了**2到8个百分点**。尤其是在高难度的**4跳问题**上,F1分数直接飙到了接近满分的**0.983**。在需要跨文档、结构化查询的AuthTrace数据集上,问题涉及的逻辑跳数越多,它的优势就越明显。消融实验也清晰地证明:**Wiki结构、智能体多轮遍历、错题本**这三个核心组件,缺一不可。
### 第三部分:一些值得深思的看法
表面上看,这是一篇关于检索技术的论文,但深入挖掘,它其实精准击中了AI工程化落地的几个核心命门。我有四点思考,或许能带来些启发:
**①(软件工程+数据治理):知识库需要“CI/CD流水线”而非“数据倾泻”**
传统RAG做数据治理,本质上就是“ETL(抽取-转换-加载)”,把原始数据一股脑倒进去就完事了。LLM-Wiki则把**知识编译**看作一次软件项目的**构建(Build)过程**,同时把**错题本**当成了自动化**单元测试(Unit Test)**。一旦编译失败(比如出现悬空链接),或者质量不达标(事实冲突),就立刻触发回滚或启动修复流水线。这预示着:**未来的AI知识库工程师,核心工作将不再是调参,而是写“数据质量断言”和维护“修复流水线”**。数据治理这件事,终于有了可以量化的工程标准。
**②(循环工程 Loop Engineering):反馈闭环不应只在“推理时”,更应在“编译时”**
现在流行的Reflexion、Self-RAG等框架,都是让模型在单次回答的“推理时”进行反思,这多少有点“亡羊补牢”的被动意味。LLM-Wiki的错题本则不同,它跨批次、持久化地积累经验,这是一种 **“治未病”** 的思路。循环工程的至高境界,不是让AI在犯错后道歉,而是让构建AI知识的**基础设施**,因为经历过错误而变得越来越 **“抗造”** 。这才是真正系统级的负反馈循环。
**③(驾驭工程 Harness Engineering):给智能体的不应是“万能工具箱”,而是“有序的迷宫”**
现阶段,大家都在忙着给智能体塞入各种各样的API工具,但往往忽略了一个问题:工具越多、环境越混乱,智能体就越容易陷入决策迷茫。LLM-Wiki最高明的地方在于,它通过**“编译”**这一步骤,主动限制了知识的混沌状态。它把海量的、非结构化的文本,**驾驭**(Harness)成了一个结构清晰的图(Wiki)。智能体在这个“有序迷宫”里,只需要掌握“搜索”和“阅读”两个基本动作,反而效率奇高。**驾驭工程的核心,也许不在于无限制地增强Agent的能力,而在于降低其所在环境的“认知熵值”。**
**④(成本的经济学):拿“索引编译成本”换“查询推理成本”**
论文自己也提到了一个局限性:编译成本很高。但我们需要算一笔总账。传统RAG为了弥补检索不准,常常需要在后面叠加很重的LLM推理逻辑(比如用昂贵的GPT-4做重新排序)。LLM-Wiki则反其道而行之,将重活儿(知识抽取、链接生成、消歧)全部挪到了**索引时(Index-time)**,而查询时,智能体仅仅需要用很轻量的方式去读页眉页脚。在当下这个“推理算力贵、存储算力相对便宜”的时代,**用预处理的结构化冗余,来换取查询时决策的极速精准**,对于系统架构师来说,这是一笔相当划算的“空间换时间”交易。
### 最后一句总结
这篇论文没有提出什么新的数学公式,它只做了一件**极度符合人类直觉**的事情:**让AI的知识库像Git仓库一样清晰可维护,让AI的检索行为像程序员查阅Stack Overflow一样富有逻辑**。它向我们表明,在Scaling Law边际效益递减的今天, **“结构化”和“可演化”** 才是AI应用走向深水区的免死金牌。未来评判一个RAG系统强不强,或许不是看它用了多大的模型,而是看它的Wiki维护得好不好,那本“错题本”够不够厚。
| 维度 | **检索即查找(老路)** | **检索即推理(新路)** |
| :--- | :--- | :--- |
| **检索次数** | **单次(One-shot)**,生死有命,富贵在天。 | **多轮迭代(Iterative)**,随时可以回头再来。 |
| **知识的形态** | **扁平块(Flat)**,所有文本被抹平,没有层级。 | **图结构(Graph/Wiki)**,有目录、有页面、有超链接。 |
| **AI的决策点** | **没有决策**,只有数学上的相似度计算。 | **处处是决策**,先搜还是先逛?读哪个页面?证据够了没? |
| **容错机制** | **无**,第一次错了,最终答案必然错。 | **有自愈性**,搜不到东西,AI会换个同义词再搜;读到的内容矛盾,AI会继续找第三方验证。 |
| **可解释性** | **黑盒**,你很难搞清楚AI为什么选那几段文字。 | **白盒(可追溯)**,AI的每一步操作(搜了谁、读了哪页、点了哪个链接)都有清晰日志,一目了然。 |
#### 4. 防崩坏机制:“错题本”(Error Book)让知识库越用越靠谱
这是整篇文章中最具工程智慧的一个亮点。大模型在编译Wiki时,难免会犯错,比如编造不存在的链接,或者不同页面里的信息相互矛盾。对此,论文提出了一个非常接地气的 **“错题本”**——一个YAML格式的规则文件。
这个“错题本”的工作流程如下:
* **发现错误**:在Wiki运行过程中,不断发现新问题,比如链接断了、某个事实没有依据。
* **归因并写成“约束规则”**:系统会分析错误原因,将其转化为一条精确的规则。例如:“严禁给目录里不存在的页面建链接”。
* **注入并修复**:当下次编译新文档时,这些规则会被写到Prompt里,警告大模型不要犯类似错误。同时,系统还会进行自动修复——代码层面修正格式,大模型层面定期处理语义矛盾。
这套机制形成了一个**持续集成的闭环**,保证了知识库不会因为不断灌入新资料而“熵增”腐烂。
### 第二部分:成绩单(实验结果说了啥?)
理论说得再好,也得看实战成绩。在HotpotQA、MuSiQue这些公认的“硬核”多步推理测试集上,LLM-Wiki相比最强对手LightRAG和HippoRAG 2,性能普遍提升了**2到8个百分点**。尤其是在高难度的**4跳问题**上,F1分数直接飙到了接近满分的**0.983**。在需要跨文档、结构化查询的AuthTrace数据集上,问题涉及的逻辑跳数越多,它的优势就越明显。消融实验也清晰地证明:**Wiki结构、智能体多轮遍历、错题本**这三个核心组件,缺一不可。
### 第三部分:一些值得深思的看法
表面上看,这是一篇关于检索技术的论文,但深入挖掘,它其实精准击中了AI工程化落地的几个核心命门。我有四点思考,或许能带来些启发:
**①(软件工程+数据治理):知识库需要“CI/CD流水线”而非“数据倾泻”**
传统RAG做数据治理,本质上就是“ETL(抽取-转换-加载)”,把原始数据一股脑倒进去就完事了。LLM-Wiki则把**知识编译**看作一次软件项目的**构建(Build)过程**,同时把**错题本**当成了自动化**单元测试(Unit Test)**。一旦编译失败(比如出现悬空链接),或者质量不达标(事实冲突),就立刻触发回滚或启动修复流水线。这预示着:**未来的AI知识库工程师,核心工作将不再是调参,而是写“数据质量断言”和维护“修复流水线”**。数据治理这件事,终于有了可以量化的工程标准。
**②(循环工程 Loop Engineering):反馈闭环不应只在“推理时”,更应在“编译时”**
现在流行的Reflexion、Self-RAG等框架,都是让模型在单次回答的“推理时”进行反思,这多少有点“亡羊补牢”的被动意味。LLM-Wiki的错题本则不同,它跨批次、持久化地积累经验,这是一种 **“治未病”** 的思路。循环工程的至高境界,不是让AI在犯错后道歉,而是让构建AI知识的**基础设施**,因为经历过错误而变得越来越 **“抗造”** 。这才是真正系统级的负反馈循环。
**③(驾驭工程 Harness Engineering):给智能体的不应是“万能工具箱”,而是“有序的迷宫”**
现阶段,大家都在忙着给智能体塞入各种各样的API工具,但往往忽略了一个问题:工具越多、环境越混乱,智能体就越容易陷入决策迷茫。LLM-Wiki最高明的地方在于,它通过**“编译”**这一步骤,主动限制了知识的混沌状态。它把海量的、非结构化的文本,**驾驭**(Harness)成了一个结构清晰的图(Wiki)。智能体在这个“有序迷宫”里,只需要掌握“搜索”和“阅读”两个基本动作,反而效率奇高。**驾驭工程的核心,也许不在于无限制地增强Agent的能力,而在于降低其所在环境的“认知熵值”。**
**④(成本的经济学):拿“索引编译成本”换“查询推理成本”**
论文自己也提到了一个局限性:编译成本很高。但我们需要算一笔总账。传统RAG为了弥补检索不准,常常需要在后面叠加很重的LLM推理逻辑(比如用昂贵的GPT-4做重新排序)。LLM-Wiki则反其道而行之,将重活儿(知识抽取、链接生成、消歧)全部挪到了**索引时(Index-time)**,而查询时,智能体仅仅需要用很轻量的方式去读页眉页脚。在当下这个“推理算力贵、存储算力相对便宜”的时代,**用预处理的结构化冗余,来换取查询时决策的极速精准**,对于系统架构师来说,这是一笔相当划算的“空间换时间”交易。
### 最后一句总结
这篇论文没有提出什么新的数学公式,它只做了一件**极度符合人类直觉**的事情:**让AI的知识库像Git仓库一样清晰可维护,让AI的检索行为像程序员查阅Stack Overflow一样富有逻辑**。它向我们表明,在Scaling Law边际效益递减的今天, **“结构化”和“可演化”** 才是AI应用走向深水区的免死金牌。未来评判一个RAG系统强不强,或许不是看它用了多大的模型,而是看它的Wiki维护得好不好,那本“错题本”够不够厚。 