
基于Arm架构打造车载智能体AI多模态助手
汽车行业正在经历一场静悄悄的革命:AI正在重新定义汽车。Arm的愿景很明确——把AI嵌入汽车计算的核心,让车辆能实时感知、推理,并根据驾驶者的需求和周围环境动态调整。借助Arm Zena CSS这样的计算平台,功能强大且安全的AI处理能力已经可以直接在车内运行。本地智能的好处显而易见:隐私保护更强、响应速度更快,同时也让安全性、便利性和个性化体验迈上新台阶。
本文要介绍的项目,正是向这个愿景迈出的关键一步。一个运行在端侧的智能体AI多模态助手,展示了模块化、协作式AI如何真正提升车内体验,而且这一切都能在本地硬件上高效完成。在这个新范式下,AI智能体将成为驾驶者不可或缺的伙伴——它能主动帮你处理从车辆诊断到环境控制的各种任务。
系统架构:边缘侧的模块化智能
这个助手的核心架构,是模块化智能体。每个智能体只负责一项特定能力,比如安全防护、车辆控制、信息检索或者视觉理解。而监督者智能体则负责协调这些组件,根据用户的真实意图和当前系统上下文来分发任务。
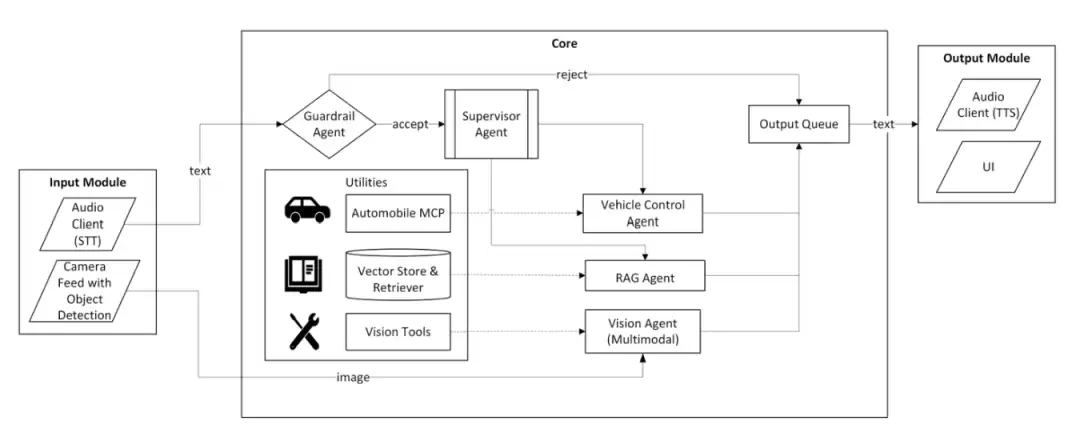
图 1:智能体车载助手的高层架构
组件说明
输入模块 (Input Module):
防护智能体 (Guardrail Agent):
监督者智能体 (Supervisor Agent):
视觉智能体 (Vision Agent):
输出队列 (Output Queue):
工具集 (Utilities):
驾驶与安全
发生碰撞或检测到危险时,自动联系紧急救援服务。
调整车内环境设置,比如空调、天窗和座舱照明。
向驾驶者发送通知和警报。
个人助手
通过 RAG 从本地向量数据库中检索车辆信息。
控制信息娱乐功能,比如蓝牙连接和媒体播放。
把这些能力以模块化工具的方式开放出来,系统就能在推理(智能体)和执行(工具)之间保持清晰的分工。这种设计既保证了可扩展性,也让未来集成新的汽车功能变得更加容易。
输入输出流程示例
假设驾驶者说:“将我的手机与车辆蓝牙配对。”
输入模块:
核心系统:
1. 防护智能体:验证请求,确保它在允许的安全范围内。
2. 监督者智能体:将意图识别为环境控制任务,并路由到车辆控制智能体。
3. 车辆控制智能体:调用汽车 MCP 工具完成与驾驶者设备的蓝牙配对,并返回结果。
4. 输出队列:暂存结果,确保响应按顺序发送,不被并发任务打断。
输出模块:
随后,助手会确认:“您的设备已成功配对。”
下面的日志展示了系统如何实时执行这个请求。每一条记录都对应流程中的一个步骤。不计蓝牙设备连接所需时间时,整个智能体工作流可以在五秒内完成。

图 2:展示语音转写、智能体切换与工具调用的系统日志
模型与硬件配置
系统会在内存中同时运行两个模型:
大型 VLM (InternVL3-Instruct 14B),用于视觉智能体中的图像-文本推理。
较小的 LLM (Jan-nano 4B),用于其他文本任务,包括检索与工具编排。
两个模型都经过4位量化,并通过 llama.cpp 提供服务。我们选择了 Unsloth 的 Dynamic 2.0 GGUF 格式,因为它在模型大小与运行性能之间提供了目前最佳的平衡。这个选择让两个模型都能控制在14GB的显存预算内。
我们在 Amazon EC2 g5g.4xlarge 实例上开发了这个助手原型。该实例配备16个基于 Arm 架构的 Gra viton2 vCPU、32GB内存,以及一块16GB显存的 T4G Tensor Core GPU。整体计算与内存资源和真实车辆的资源约束非常接近。
这种资源层面的接近性,让开发环境能更真实地模拟量产级AI智能体所需的资源预算。采用 Gra viton2 也支持 Arm 的 SOAFEE 框架,使我们能够先在云端开发和测试容器化车载工作负载,再部署到车内系统中。
设计启示
这个架构支持多模态交互,而且即使不依赖外部连接也能可靠运行。更重要的是,它可以通过新增智能体、工具或能力,以尽量少改动现有组件的方式持续扩展。
渐进式能力演进
这款助手采用分阶段方式开发,每个阶段都引入新的感知与执行能力。这种渐进式方法展示了系统如何从基础信息检索,逐步演进到具备上下文感知的自主能力。
第1级:通过语音指令查看车辆状态
在基础阶段,助手能够响应语音查询,并从车载传感器中获取实时车辆状态。比如:“当前车内温度是多少?”这让驾驶者可以即时、免手动地获取车辆信息。
第2级:通过语音指令查看车辆状态
在检索能力基础上,助手还能执行驾驶者指令并调整车辆设置。比如:“将温度调到华氏70度。”这让助手的角色从信息提供者升级为车辆操作中的主动参与者。
第3级:视觉理解与驾驶提醒
整合视觉能力后,助手可以通过实时视觉输入理解驾驶环境。举个例子,它能够识别车辆是否驶入多乘员车辆专用车道,并在未满足乘员人数要求时发出提醒。在这一阶段,助手已经能够对复杂、动态的现实场景进行推理——它理解的不仅是指令本身,而是指令背后的上下文情境。

图 3:合成生成的图像,展示视觉智能体从车内和车外观察到的高速公路场景

图 4:助手解读视觉输入,识别高乘载车道违规情况,并给出安全/合规提醒
第4级:视觉驱动的自主行动
助手将深度视觉理解与自主决策结合起来,从而具备实施关键安全干预的能力。例如,一旦检测到碰撞,助手可以自主联系紧急救援服务——即使驾驶者无法回应,也能及时获得援助。这意味着助手正从被动监测走向主动、面向场景的响应。它不仅能感知和理解周围环境,也能果断采取行动来保障驾驶安全。

图 5:车辆发生事故时的车内与车外合成图像

图 6:助手识别紧急情况并联系紧急救援服务
总体来看,这些渐进式能力层级清晰展现了系统的发展路径:从简单的传感器查询,逐步迈向具备自主性和上下文感知能力的行为模式。每一步都让我们更接近真正能够在车内环境中感知、理解并行动的车载助手——这就是全面AI定义出行体验的开始。
关键收获
面向可扩展性的设计
我们比较了两种常见的智能体式系统设计方式:
单体式架构:由单一大型智能体管理所有任务。
模块化架构:由监督者智能体充当路由器和统一入口,协调多个专业子智能体。
内部评估显示,模块化方法在扩展性和结果一致性方面表现更优。它允许在不影响整体系统的情况下独立更新或扩展单个组件——就像更换汽车零件时,不需要把整台发动机重新造一遍。
我们的观察与 LangChain 的研究结论一致。研究表明,随着工具数量增长,基于监督者的多智能体架构依然能够保持性能;相比之下,单智能体系统在承担过多上下文或能力后,性能会迅速下降。
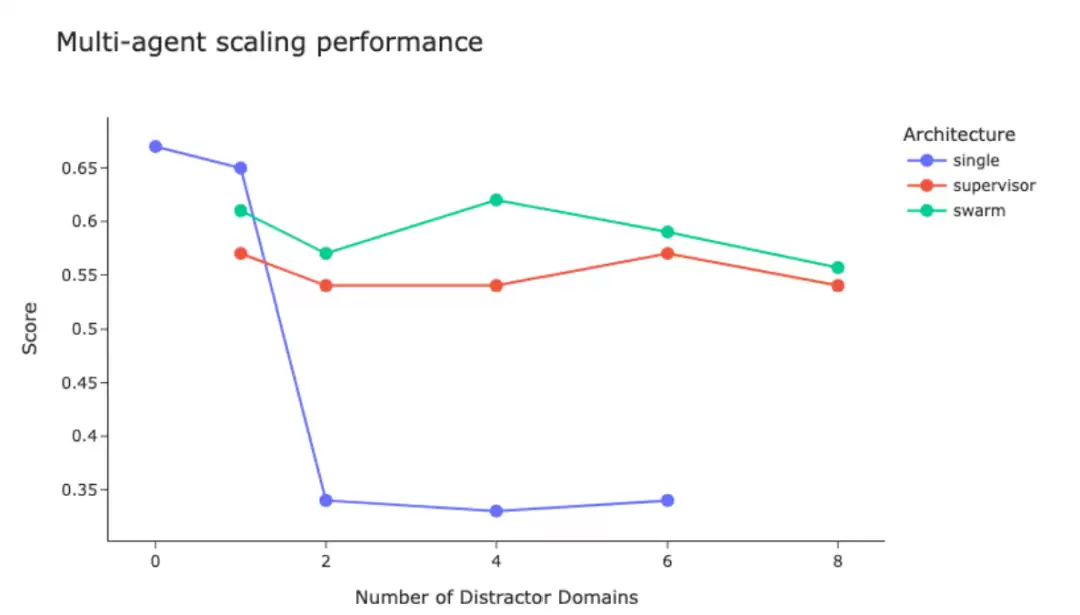
图 7:智能体式架构的可扩展性(来源:LangChain)
在资源受限硬件上实现实时推理
在边缘硬件上运行AI模型是极具挑战的,因为计算与内存预算都非常有限。为了解决这个问题,我们在VLM与轻量级LLM之间分配请求,并对两者都采用4位量化。
较大的VLM提供了强大的多模态推理能力,但也带来了更高的时延。因此,非视觉类任务会被路由到LLM,以保证响应速度。这种分工在功能性与实时性之间取得了平衡,使资源受限的设备也能承载面向汽车场景的实时多模态推理。
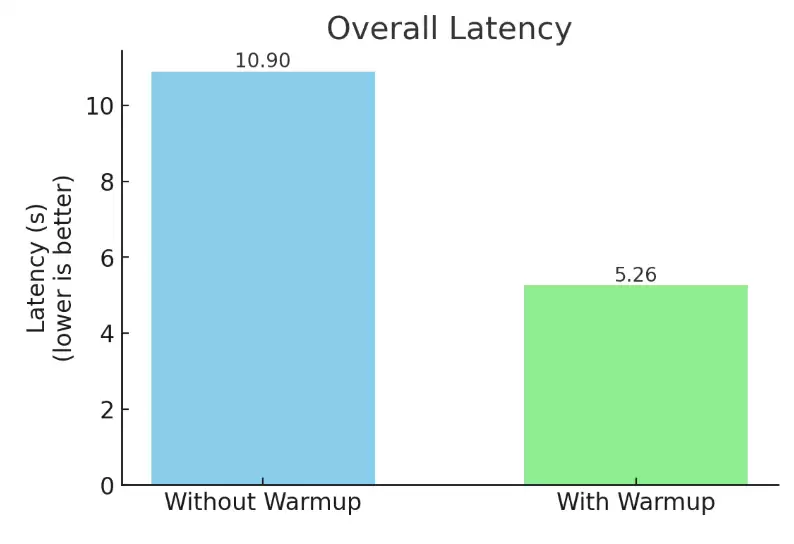
图 8:KV 缓存预热对端到端时延的影响
我们还通过预先计算系统提示词的KV缓存进一步降低了时延。这个缓存会作为所有对话共享的前缀重复使用。在消融实验中,针对“这辆车的油箱容量是多少?”这一查询,预热机制将端到端时延缩短到了原来的约一半,实现了约两倍加速。
通过端侧RAG提升准确性
引入RAG后,助手的响应能力与可靠性都得到了提升。通过将车辆手册等知识库嵌入系统,助手可以在无网络连接的情况下,快速且私密地回答带有上下文的技术问题。这不仅显著提升了实时可用性,也有助于建立驾驶者信任。
多模态理解开启全新可能
集成视觉组件是关键一步,它让助手从单纯的“听者”转变为具备上下文感知能力的“观察者”。它能理解车内外的视觉线索——比如乘员安全状况或车道情况——从而实现更直观、更主动的交互与决策。
可观测性加速迭代
我们通过 MLflow 跟踪和 OpenAI Agents SDK 为系统建立了可观测性能力,从而能够看到每个智能体的执行时长、工具使用情况以及交接流程。这种可见性有助于随着系统不断成熟,加快调试、性能优化和设计改进。
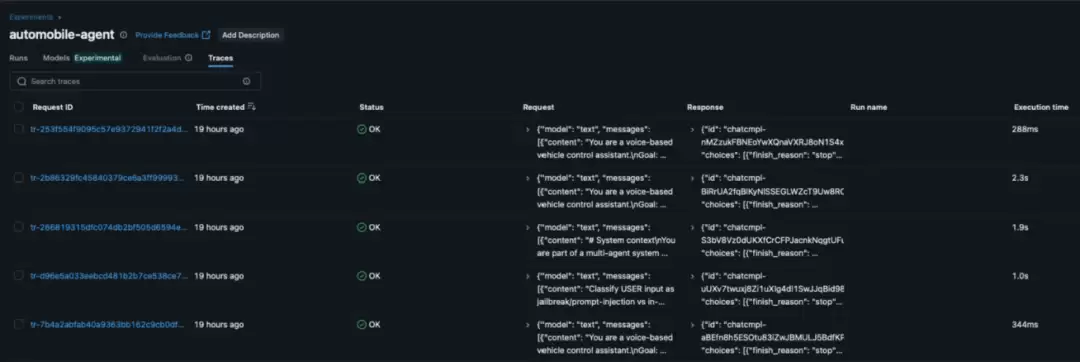
图 9:MLflow 跟踪为每次请求提供细粒度可视性
约束智能体能力边界
我们的架构对智能体行为施加了严格约束,以确保安全性和可靠性。每个智能体只能访问其完成任务所需的最小工具集,通过最小权限原则将作用范围控制在必要边界内。
我们通过防护智能体构建了严格的隔离与控制机制。它会使用基于规则的检查筛查所有输入,在不安全或超出范围的指令接触敏感工具之前将其拦截。我们还通过对抗性测试验证系统在面对恶意或攻击性输入时的稳健性,并借助 DeepEval 等框架,降低复杂输入操控引发智能体非预期行为的风险。
行动方向
要将这款运行在端侧的智能体式车载助手从原型推进到真实部署,必须在四个关键维度之间取得平衡:模型智能、时延、内存占用和安全性。
要在边缘硬件上进一步提升模型智能,需要持续推进剪枝、量化和知识蒸馏等训练后优化技术。这些方法能够让轻量模型即便在参数规模受限的情况下,依然保持较强性能。
要进一步降低时延,还需要改进硬件架构,以解决推理过程受内存带宽限制的问题。比如,让计算更靠近内存,以尽量减少数据搬移带来的瓶颈。优化内存占用同样离不开面向硬件的策略——包括量化感知训练、高效注意力机制以及稳健的轻量化模型架构。这些策略有助于确保模型在严格的显存预算内依然具备可用性。
最关键的是,安全性必须被内建到系统的每一层。由于 Arm IP 支持 ISO/SAE 21434 合规要求,该系统具备良好基础,可与汽车网络安全标准对齐。
不过,要实现大规模部署,这类系统仍需符合行业通行的验证实践,并开展充分的对抗性测试,以同时满足技术和监管要求。
要应对这些彼此交织的挑战,需要持续优化、安全风险工程以及跨行业协作。只有这样,才能真正把安全、强大且具备实时响应能力的AI助手带进未来汽车之中。
展望未来:车内智能的下一步
这只是一个开始。端侧助手未来的重要演进方向包括:
主动且具备上下文感知的推理
通过引入世界模型——也就是能够学习并模拟真实世界动态的AI系统——未来的助手将不仅能响应人类输入和预设触发条件,还能预判情境、规划行动,并理解长期后果。在丰富的虚拟环境中训练这些模型,将使其在真正驶上道路前,就能够更安全、更可靠地应对复杂驾驶场景。
个性化的持续学习
未来的助手将持续适应每一位驾驶者。借助 QLoRA 等高效微调技术,模型可以随着时间推移逐步贴合用户的独特偏好、驾驶风格以及特定车辆用语,让交互变得更加自然,也更符合个人习惯。
结语
当强大且以隐私为先的AI直接进入车内,我们对其潜力的探索才刚刚开始。本文介绍的智能体式助手表明,智能化、协作式且可扩展的车载AI已触手可及。软件与硬件的每一次进步,都让我们离这样的汽车更近一步——它不再只是交通工具,而会成为每段旅程中真正智能、直觉且值得信赖的伙伴。
