
中美AI对弈之下的算力难题
当整个AI大模型世界都在沿着Scaling Law一路狂奔时,中国玩家却不得不面对一个现实问题:高端芯片供应被卡了脖子。
以达里奥为首的一群“OpenAI 叛将”,已经把Anthropic推到了万亿美元估值俱乐部里。这个阵营里的Opus 4.6,长期扮演着大模型性能的度量衡角色。
更夸张的是它的后续型号——Mythos。这玩意儿强到什么程度?由于“性能太过骇人”,干脆没有被公开发布。它的参数规模直接干到了10万亿,训练数据量是300万亿token,单次训练成本估算就要100亿美元。美国政府的反应也很直接:以“国家安全”为由,暂停了所有外国公民对这款模型的访问。
反观国内,目前最拿得出手的DeepSeek V4 Pro,总参数量是1.6万亿。和美国十万亿级的产品相比,差距大约是6倍。有研究结论是,DeepSeek V4 Pro的能力落后美国前沿大约8个月。
“AI一天,地上一年”——这种代际差,根源就在高端算力的缺失上。
黄仁勋、马斯克这些国际大佬,嘴上对中国AI各种夸赞,但高端算力尤其是AI训练芯片的匮乏,就像一道深深的沟壑,始终横亘在中美AI竞赛的赛道上。
美国科技巨头们打得是一场“富裕仗”:巨额的资本开支、海量的顶级GPU集群、充沛的人均token量。光是Meta一家公司手里的GPU算力,就超过了中国所有AI企业的总和。美国科技巨头的AI投入,更是天文数字级别的。
在算力需求指数级飙升、存储芯片等硬件成本持续高涨的压力下,DeepSeek等国内大模型只能通过模型蒸馏来压缩成本。这种做法也引发了中美之间新一轮的博弈。
高端AI芯片进口受阻,市场需求却井喷式爆发。如何在不依赖进口、同时本土替代尚未成熟的情况下,找到一条可行的出路?这已经是整个中国AI产业绕不过去的必答题。
算力掣肘
算力掣肘
去年底以来,摩尔线程、沐曦股份、壁仞科技、天数智芯这些国产GPU厂商,在资本市场掀起了一波热浪。不过,二级市场的财富盛宴背后,有一条暗线越来越清晰,它引发的问题也越发迫切。
过去几年,国产AI芯片的阵地主要集中在相对安全但也很边缘的“推理侧”。比如近期豆包计划豪购天数智芯5万块芯片,就是用于推理运算,以满足它作为中国最大AI APP终端的高频调用。
但在AI训练这个算力金字塔的顶端,国产芯片目前只能参与一些边缘的“打杂”任务。
AI训练芯片,是用来教模型“学会知识”的。这个过程涉及海量的矩阵运算和参数调整,需要强大的计算能力和能效比。性能强,价格自然也高,英伟达的A100、H100、H200,以及AMD的MI300系列,都属于这类。
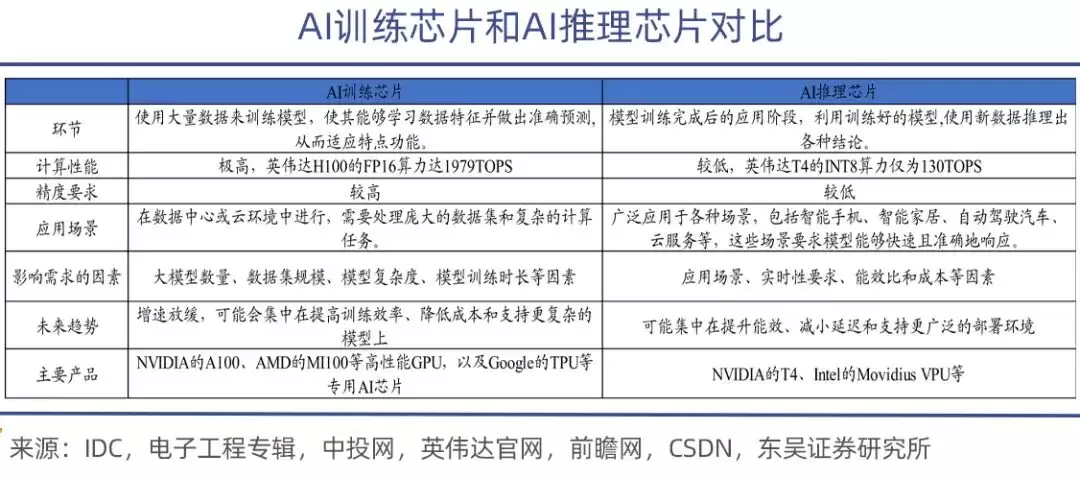
相比之下,推理芯片的任务要轻松很多。它主要负责模型训练完成后的部署阶段,执行模型的推理任务。这个环节对实时性要求高,需要在保证准确率的同时,做到快速响应和低功耗。
打个比方就是:训练是让AI“学知识”,推理是让AI“用知识”。
中美模型的差距,根源就在这些“看不见的地方”——尤其是高端训练芯片的缺席。
在大模型遵循Scaling Law的规律下,模型参数越大,算力需求就线性增长。而算力和硬件成本呈指数级膨胀,使得训练大模型成了少数科技巨头的“专属游戏”。
美国科技巨头里,光是Meta一家,就计划到2026年底部署超过120万张高端GPU,年投入超过1450亿美元。另据测算,谷歌拥有的AI总算力相当于500万块英伟达H100,一家企业就占了全球总量的四分之一。
Amazon、Microsoft、Alphabet、Meta,这四家公司今年的资本开支高达7250亿美元,同比猛增77%。这个规模,相当于美国全年私人国内总投资的13%。大摩更是预测,到2027年,美国科技企业的资本开支有望达到1.1万亿美元的历史纪录。
目前美国掌控着全球七成以上的高端GPU。芯片禁令之后,国内可用的高端芯片只有美国的八分之一。斯坦福AI Index Report 2026报告指出,美国的数据中心数量(5427个)是中国的10倍有余。
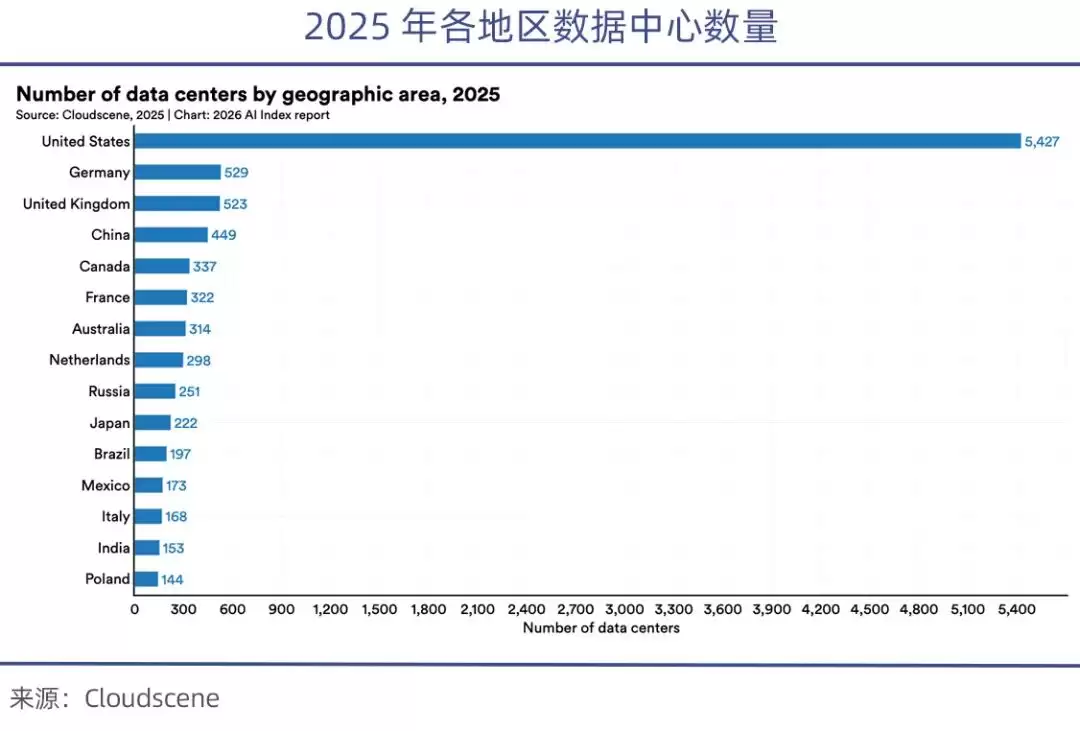
根据中国信息通信研究院的测算,截至2025年初,美国算力规模为2400 EFLOPS,中国是1053 EFLOPS,美国是中国的两倍多。
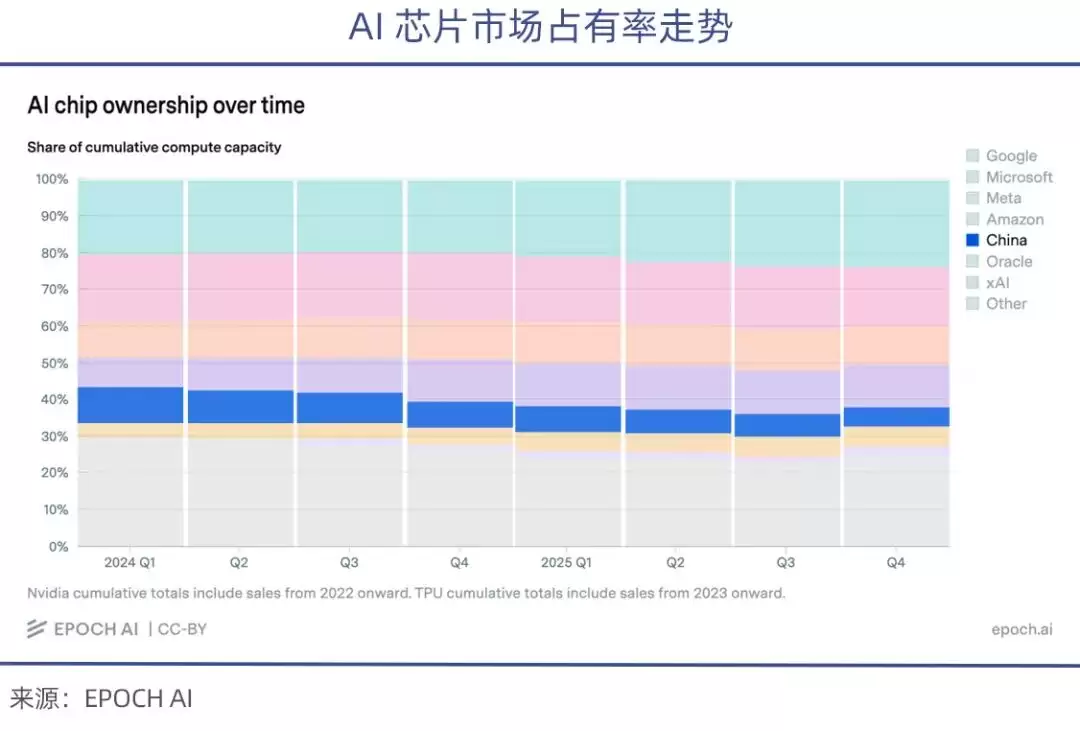
上述四家科技巨头,每一家单拎出来的算力规模,都已经超过了中国所有AI企业的总和。
这种碾压式的算力优势,让美国企业一年内就能完成十几轮大模型迭代实验。
马斯克的玩法就更奢侈了。他旗下的xAI拥有号称全球“首个GW级AI集群”的Colossus 2。因此他有底气宣称,正在同时训练7个模型——两个1万亿、两个1.5万亿、一个6万亿和一个10万亿参数模型。这种“暴力美学”,只有在算力极度充裕的情况下才能实现。
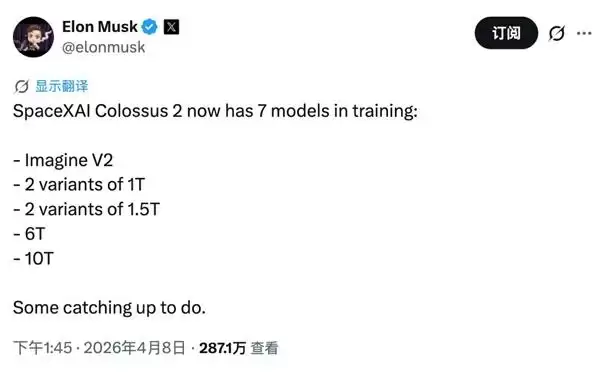
与此同时,美国在芯片出口上持续收紧。根据epoch.AI的统计,近年来出货的高端AI芯片中,中国企业获得的比例一直在下滑。
可以毫不夸张地说,算力基座的巨大差距,将导致中国AI长期处于追赶状态,也会让国产大模型追赶美国同行的过程变得更加艰难。
代际之差
代际之差
“中国创新的步伐不可阻挡”,“谁要是觉得中国做不出来(芯片),那就真的看走眼了。中美之间的差距只是纳秒级别”。
英伟达创始人黄仁勋不止一次在公开场合称赞中国半导体的进步。

马斯克也经常在X上表达类似观点——“中国一定会解决芯片卡脖子问题,人工智能算力领域,必将远超全球其他国家”,“中国会赢下地球上的AI竞赛”。
这些科技界大佬的溢美之词,听起来很提气,但很容易让人信以为真。这些言论,明显有“捧杀”的嫌疑。部分美国媒体也在不断宣扬“中美模型差距极小”的舆论,试图混淆事实、掩盖一些客观真相。
对此,国内AI相关领域都需要保持清醒和冷静。
如果说中国先进大模型在解决标准化问题时,和美国竞品的差别不大,那么一旦进入复杂的工业和企业环境,差距就会变得非常明显。
和美国Anthropic这类公司的前沿模型相比,中国仍然只能算是追赶者。美国CAISI评估认为,国内最强的DeepSeek V4 Pro落后美国前沿大约8个月。
李开复近期在接受《华尔街日报》采访时也指出,以Anthropic推出的Claude Fable 5等美国顶尖模型为标杆,
美国目前领先中国大约15个月。

大模型遵循Scaling Law,模型参数量越大、训练数据越多、投入的算力越大,性能就越好。如今,美国最前沿的大模型已经进入十万亿参数时代,迭代速度还在加快。
Anthropic最强的Mythos已经达到10万亿参数,训练它就要耗费100亿美元;xAI的Colossus 2正在同时训练7个模型,其中包括6万亿和10万亿参数模型;OpenAI迭代一轮4万亿参数模型的周期,只需要一个月。
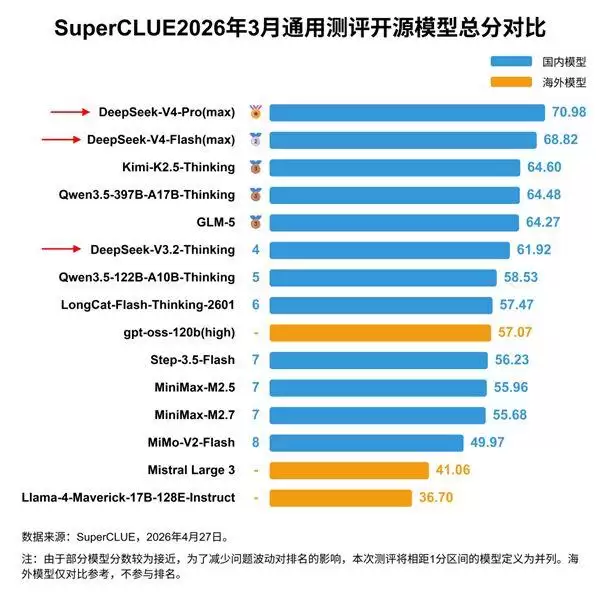
中国最强模型DeepSeek V4 Pro总参数量为1.6万亿,和美国十万亿级前沿产品相差约6倍。
Anthropic旗下的Claude系列,已经被公认为近两年最强的AI编程大模型。Mythos则又一次刷新了认知,它的性能比此前的旗舰Oups 4.6还要强。
更令人震惊的是,OpenBSD在业界一直有着“最安全系统”的美誉,结果Mythos找到了一个27年间都没被发现的漏洞。它还从FFmpeg、Linux内核中,挖出了几年甚至十几年都没被发现的漏洞,全程自主发现,没有依赖任何人类。
要知道,大模型的“预训练”决定了模型能力的上限。你不可能通过“后训练”,把一个万亿参数级别的模型,调到和10万亿参数模型一样的能力水平。而预训练的决定因子,就是高端算力芯片——它直接决定了参数规模和训练迭代速度。
科大讯飞董事长刘庆峰就坦言,目前各家顶尖大模型厂商,尤其是美国巨头,都在建超大规模算力平台。而国产算力目前确实面临阵痛期,导致在训练超长文本上下文时遇到了限制。
可见,
算力差距就是中美模型之差的根源。
国产崛起
国产崛起
一家企业垄断全球高端AI训练芯片90%的市场份额——这个事实,正是英伟达能一直稳坐全球第一大市值公司宝座的原因。它的总市值,一度超过了全球第三大经济体德国2025年的GDP。
集邦咨询的数据显示,2026年第一季度,全球GPU服务器市场,英伟达一家吃掉68%,AMD占5%-6%,而所有国产GPU厂商加起来,不足4%。
凭借先发优势、超强的技术壁垒、高速互联能力、软件生态,以及绑定台积电先进制程,英伟达几乎是独霸天下。在高端训练场景下,英伟达的GB300性能强于AMD的MI325,也好于寒武纪思元690、摩尔线程MTT40。尤其是在万亿参数大模型训练中,性能比竞品强出30%以上。
出口禁令之下,黄仁勋此前已经表示,英伟达在中国市场的新增份额已基本归零,只剩存量市场。在国产替代政策的支持下,包括华&为昇腾910、海光DCU深算2号、寒武纪思元370/590,以及摩尔线程、沐曦等企业,纷纷涌现。
其中,昇腾910是华&为最强的算力芯片,昇腾910B的算力达到640TOPS(INT8),可以媲美英伟达的A100芯片。
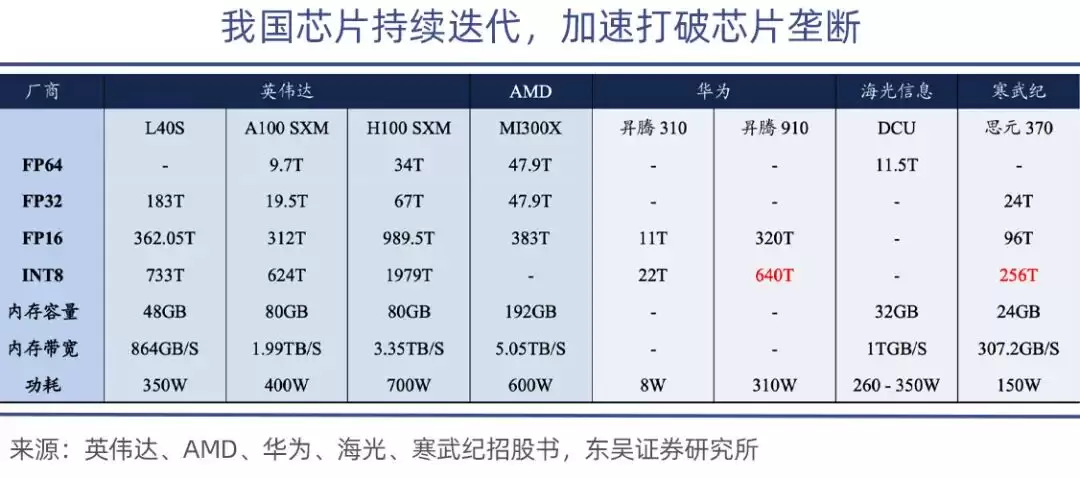
在绝对性能层面,国产GPU虽然有差距,但可以先从推理和边缘场景入手。目前国产GPU基本能满足国内政企的通用推理需求,和英伟达中端产品的差距已经缩小到15%-20%,具备替代的可行性。
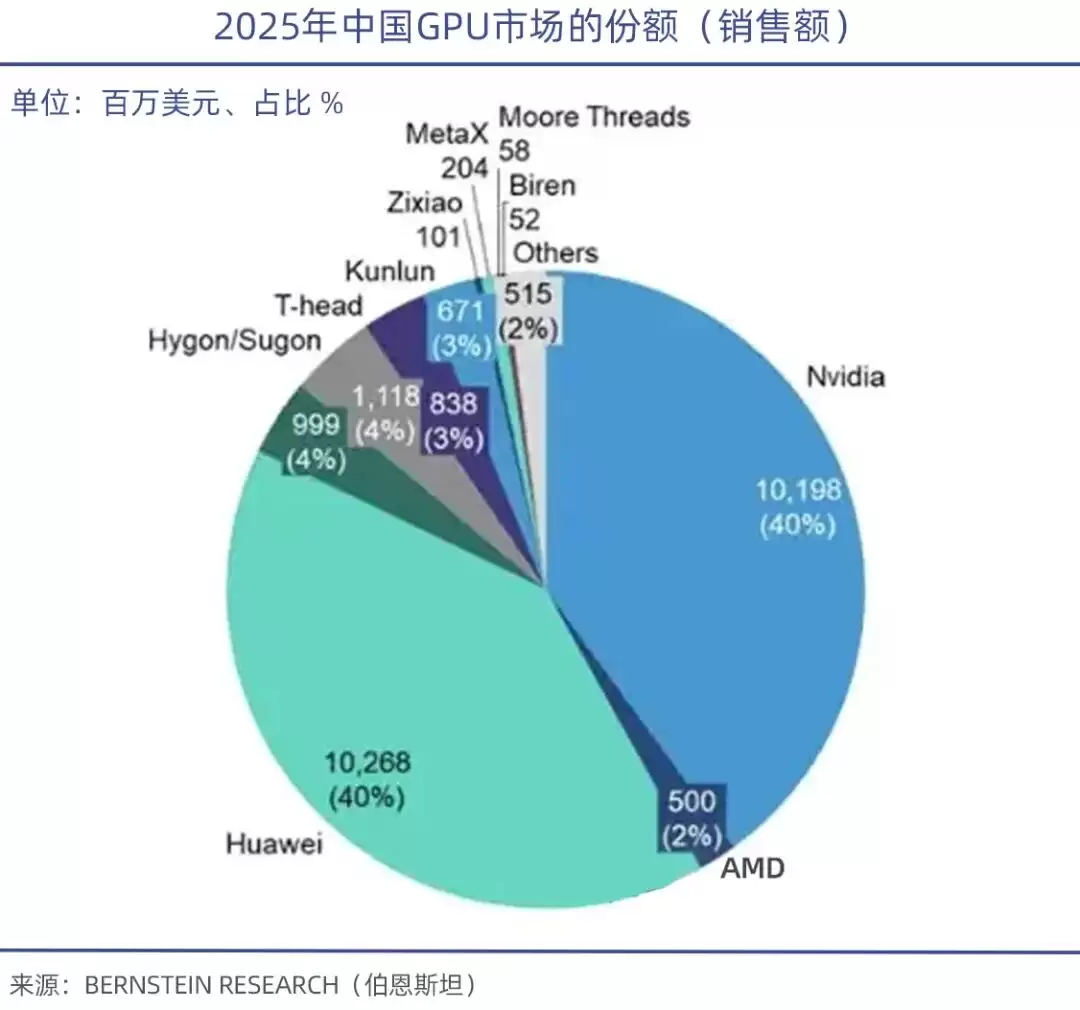
需要特别强调的是,算力性能固然重要,但背后的软件生态才是国产GPU的真正软肋。就像CUDA生态是英伟达GPU帝国的基础一样,中国工程院院士郑纬民就指出,
国产AI芯片的核心问题是生态不够好。如果生态好了,哪怕性能只做到60%,也会有人用。
可以说,软件生态是GPU赛道最硬核的壁垒。在这方面,英伟达的能力同样难以替代。
CUDA生态经过十余年的深耕,已经拥有超过400万开发者、数十万个开源模型、全品类的第三方工具链,覆盖AI训练、推理、图形渲染、科学计算。这个生态壁垒,强悍得几乎无解。
IDC数据显示,目前全球95%以上的AI模型都是基于CUDA生态开发的。而国产GPU,在政策支持之外,还需要和产业链长期协同,也需要媒体舆论和资本市场给予足够的耐心。
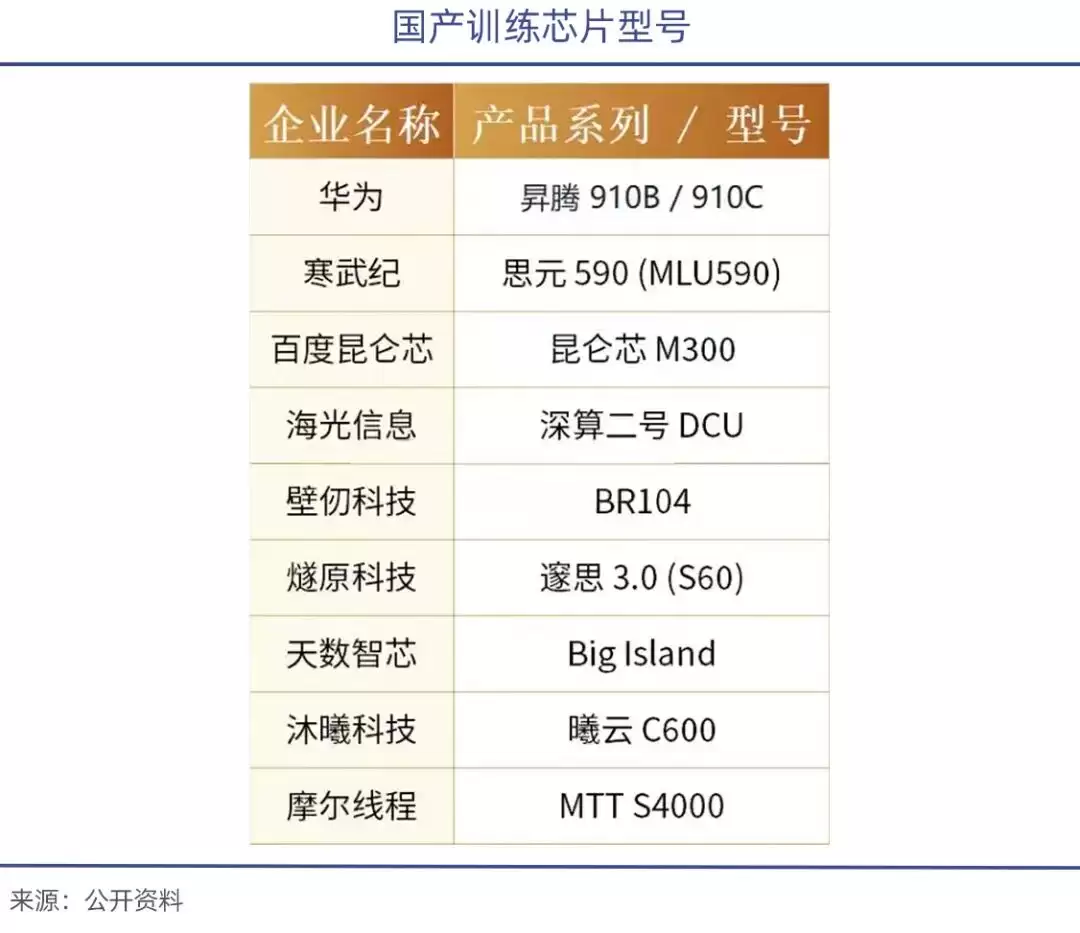
今年1月,智谱联合华&为开源了新一代图像生成模型GLM-Image。这个模型基于华&为昇腾Atlas 800T A2设备和昇思MindSpore AI框架,完成了从数据处理到模型训练的全流程闭环,是首个依托国产芯片实现全程训练的SOTA多模态模型。
摩尔线程也和北京智源人工智能研究院一起,基于MTT S5000智算集群与FlagOS-Robo框架,完成了智源自研的具身大脑模型RoboBrain 2.5的全流程训练。这个成果第一次验证了,国产算力集群在具身智能大模型训练中的可用性。
可以看出,国产GPU在适配性和生态构建方面已经有了突破,正从推理侧的“单点突破”,迈向训练侧的“逐步适配”。这本身就是一种长足的进步。
总结
总结
整体来看,在海外先进芯片进口受阻的背景下,最现实的做法是“中西结合”,两条腿走路:一边继续依赖可获得的资源,另一边重点扶持国内算力芯片,以满足迫切的市场需求。
需求的真实性毋庸置疑。虽然“泡沫论”依然存在,但声音并没有越来越大。全球市场对AI建设的热情,已经超越了此前任何一个产业早期的发展历程。
今年以来,全球资本市场再度掀起超级AI周期。三星、SK海力士、博通、台积电的股价屡创新高。国内市场上,以寒武纪为代表的硬科技股也是涨势凶猛,光模块巨头中际旭创的市值一度超过了茅台。
回顾韩国半导体的发展史——韩国以举国之力支持存储芯片产业,熬过至暗时刻,最终击败日本,成为世界存储产业的绝对王者。
无论存储芯片、手机芯片,还是当下的AI芯片,中国都还处于追赶阶段。这绝非一朝一夕之功。
但凭借巨大的市场、不断涌现的AI人才、庞大的资本实力,国产GPU已经开始展现出一定的适配性,能够解决许多AI企业的真实需求。
在这场关乎国运的AI对弈中,中美两国既是对手,同时也各自拥有对方所需的技术、市场和资源。
