
花五分钟,解决腾讯ima知识库识别超链接的问题
腾讯ima最近上线了知识库广场这个重磅功能,这不,赶紧去体验了一把(说白了就是冲着羊毛去的,不占用个人那2G空间)。
功能确实给力:
- 共享知识库发布到广场后,可以免费无限扩容——完全不占个人存储空间。
- 单个共享知识库的成员上限,直接扩到了100万。
用积累的一些资料,创建了一个嵌入式开发知识库(涵盖嵌入式开发指北、C语言、C++、Python、shell、Linux内核和驱动等内容和资讯),顺手发布到了知识广场。
让那些半沉睡的知识重新醒过来,也顺便省省自己的存储空间。
上传几份资料后,实际体验了一轮。ima准确给出了知识库中关于Python入门的推荐书目——但问题来了,文档里明明附带了书籍的在线阅读链接,点击即可直达,而ima只给出了书名,根本没有提取出链接地址。
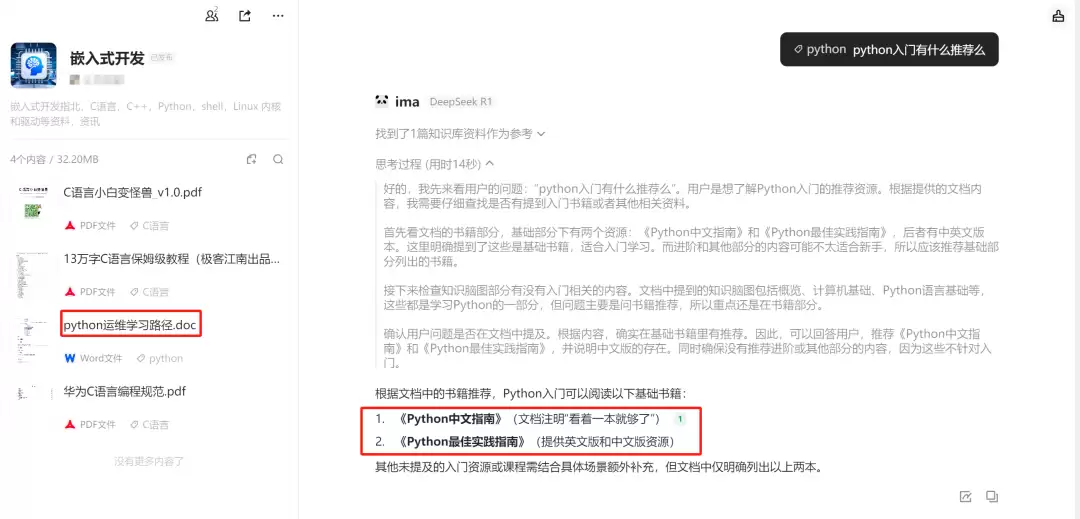
也许是ima一时犯了糊涂。接着追问:“请给出推荐书籍的资源地址”——结果,ima明确告知:文档中未明确提供《Python中文指南》和《Python最佳实践指南》的下载地址或在线资源链接,根据规则无法提供更多信息。
可实际情况是,源文档里那些书名本身就是超链接,点击就能跳转到在线阅读页面。
曲线救国
拿不到资源链接地址,这肯定不是想要的,也不是创建共享知识库的初衷。不方便、不快捷,绝对不行。怎么办?
先尝试把doc格式转为PDF再上传,耗时3分钟。结果ima给出的答案还是老样子,依然无法提供资源地址。
ima说我没提供,可我提供的明明是超链接。回归本质:直接给链接地址,简单直接,不绕弯子。修改文档,把完整的链接地址写进去,再次上传,耗时2分钟。
ima的回答这回完美了,直接给出了在线阅读链接。
写在最后
文档里加超链接,是再常见不过的操作,不管是PDF还是doc格式。但对当前的ima来说,它只看到了表面的文字,看不见背后的链接地址。在ima优化解决这个问题之前,只能用这种简单粗暴的方式临时处理了。
如果是Markdown格式的文件,按说ima应该能正常处理这类链接——可惜当前ima还不支持md文件格式。期待ima后续的更新吧。
