
CherryStudio知识库详细设置教程
最近,有好几位朋友问起CherryStudio知识库的设置问题。虽然此前已经聊过不少相关内容,但仔细翻看后发现,知识库的
参数设置
新建知识库
在知识库界面点击“添加”,就会弹出新建窗口。名字可以随意起;至于嵌入模型,如果一时拿不准该用哪个,先选bge系列是个稳妥的选择。
至于如何挑选嵌入模型,后续会在《知识库优化之路(三)》中详细展开,这里先按下不表,直接进入今天的正题。
知识库设置
知识库添加完成后,在模型信息区域会有一个设置按钮。点进去,就进入了知识库参数界面。
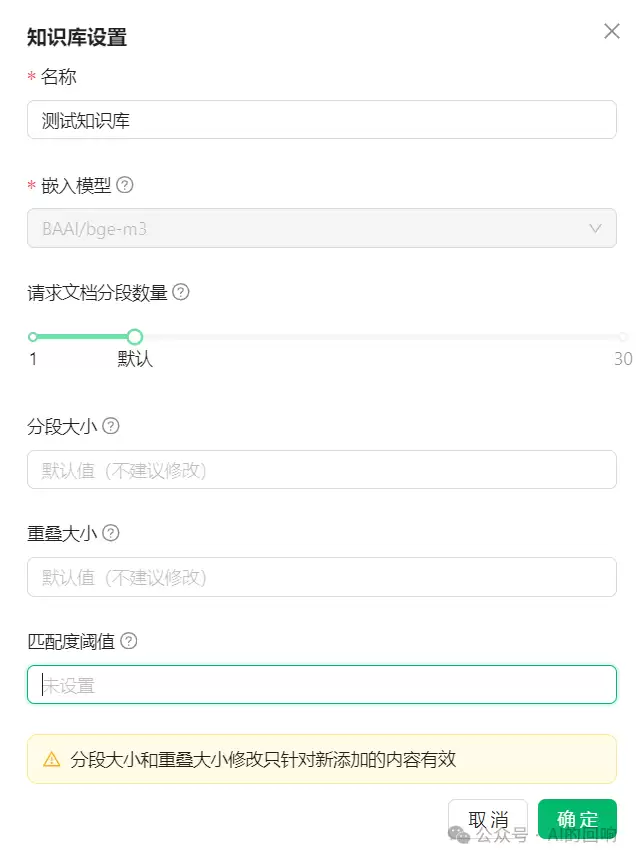
这里有一个关键点:
嵌入模型一旦选定,就无法再更改了
除了嵌入模型之外,知识库可调的参数其实并不多。下面逐一拆解。
1 请求文档分段数量
这个参数很好理解:当你向大模型提问并启用知识库时,会有几个资料片段随问题一起提交给大模型。

CherryStudio默认值是6段,最大值可以设到30。但请注意——
绝不是越多越好
第一,token消耗(也就是金钱消耗)。
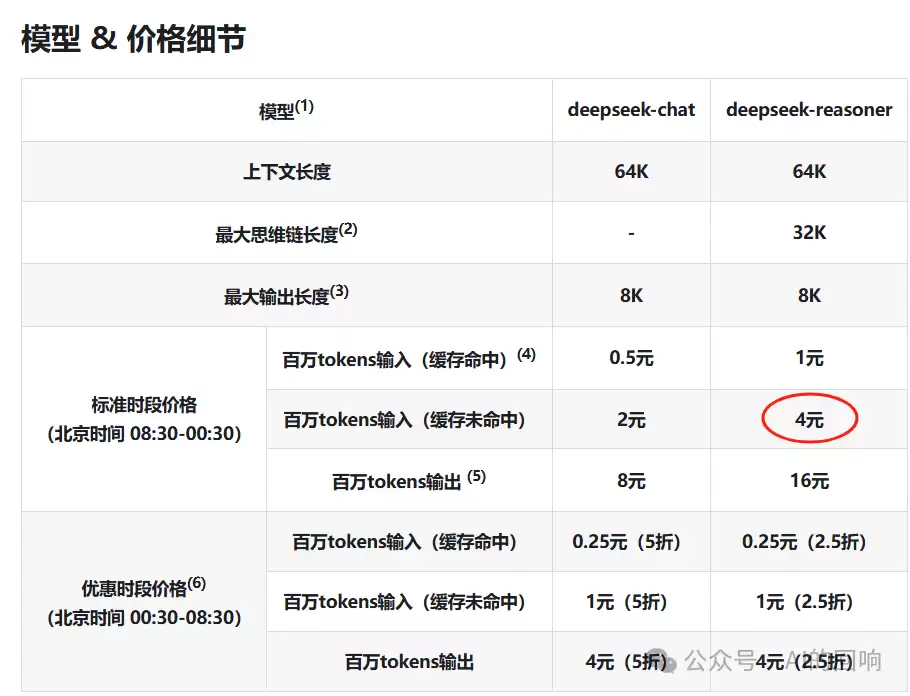
当然,对话不会只有一轮。多轮下来,就算考虑缓存命中,几毛钱的消耗也跑不掉。
第二,上下文长度限制。
第三,API接口限制。
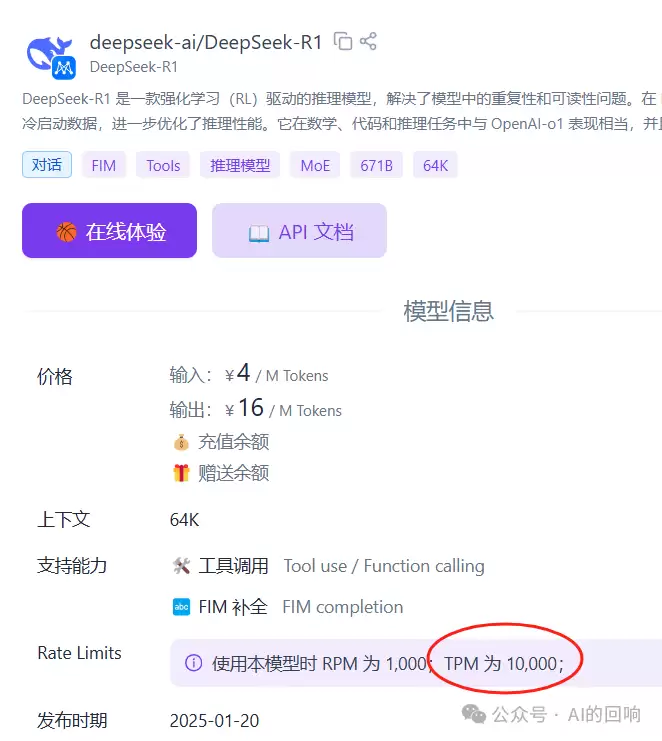
硅基流动对普通版DeepSeek-R1的TPM限制是10000,也就是每分钟最多10000个token(Pro版是每分钟100万个,可以放心用)。试想,问题附带的资料就有15000个token,你的请求还能成功发出去吗?至于其他平台是否有类似限制,暂时没逐一核实,使用时多留心准没错。
第四,匹配度的限制。
2 匹配度阈值
之所以没按照界面从上到下的顺序介绍,而是把匹配度阈值放在第二个说,是因为它和“请求文档分段数量”共同决定了最终大模型能收到几个片段。
匹配度阈值就像一个筛子:只有匹配度高于某个百分比的片段,才有资格被提交给大模型。CherryStudio官方可能没有设置默认值,但根据经验,有些匹配度只有30%多的片段也会被搜到——这种基本没有参考价值。
这个参数的范围是0到1:0.1就是10%,0.5就是50%,1就是100%。一般情况下,设置在70%(即0.7)比较合理。但如果知识库资料不够多,设70%可能一条都匹配不到,这时可以适当降到60%或50%。再低,参考价值就大打折扣,纯粹是浪费token了。
所以,
“请求文档分段数量”并不能完全决定最终提交的片段数
3 分段大小
分段的问题之前介绍过,相信大家已经理解了。不理解什么是分段、为什么要分段的,建议先去回顾一下相关内容。
分段大小指的是每个片段的字数。这个参数,
官方不建议修改,也不建议自行调整
4 重叠大小
重叠大小和分段大小密切相关。如果分段时只是简单粗暴地按每段500字直接切开,很多句子、段落都可能从中断裂,信息不完整。为了解决这个问题,允许相邻的两个片段在结尾和开头部分有一定内容重复(即重叠),从而减少被拆分的可能,优化分割效果。
在CherryStudio里,想设置重叠大小,必须先设置分段大小。既然分段大小不建议自己改,重叠大小自然也不建议手动调整。既然这两个值都没有动,官方那句“分段大小和重叠大小修改只针对新添加的内容有效”也就可以直接忽略了。

