
刚刚,阿里最强编程模型开源,4800亿参数,Agent分数碾Kimi K2,训练细节公开
深夜上线Qwen Chat,海外网友已经玩疯了
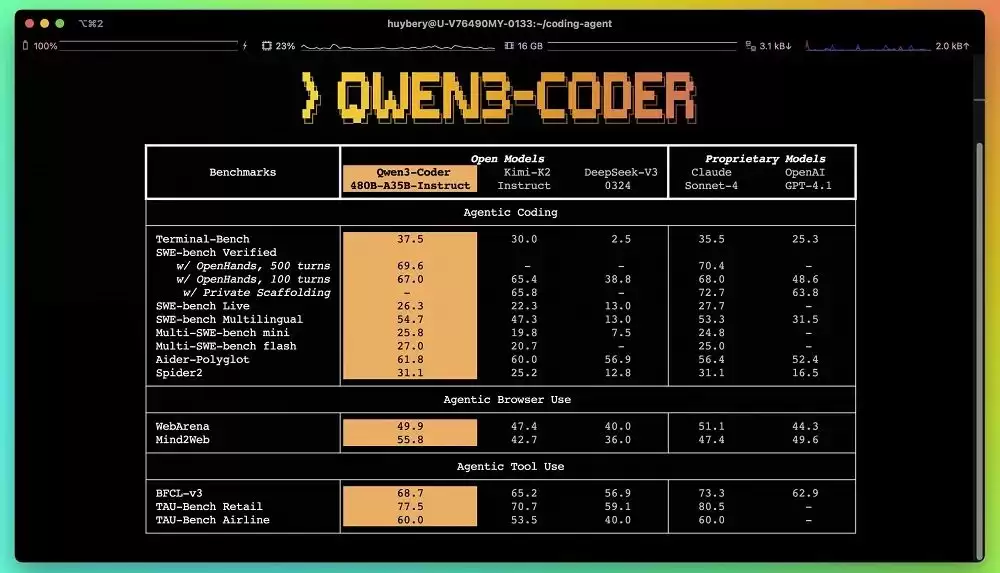
就在刚才,阿里巴巴Qwen团队悄悄放了个大招——开源了其最新一代旗舰编程模型Qwen3-Coder-480B-A35B-Instruct。用团队自己的话说,这是迄今为止他们最强大的开源智能体编程模型。参数规模达到480B,但激活参数只有35B,原生支持256K上下文,还能通过外推扩展到100万token的输入,最大输出能力是6.5万token。
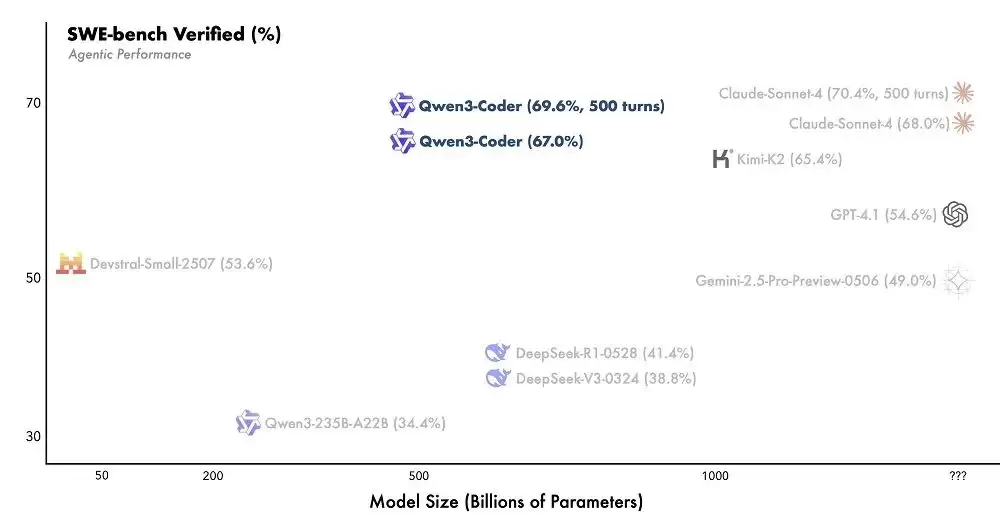
这个模型在基准测试中表现相当亮眼。在Agentic Coding(智能体编程)、Agentic Browser-Use(智能体浏览器使用)和Agentic Tool-Use(智能体工具调用)这三类任务里,它都拿到了开源模型中的最好成绩(SOTA),直接超过了Kimi K2、DeepSeek V3这些开源对手,甚至跟GPT-4.1这样的闭源模型也能掰手腕。更关键的是,它完全可以和以编程能力见长的Claude Sonnet 4一较高下。
这次开源的是Qwen3-Coder最强大的变体版本。从参数规模来看,它超过了阿里自家的旗舰模型Qwen3的235B,但远小于Kimi K2的1T。阿里官方给出了一句相当有冲击力的评价:借助Qwen3-Coder,刚入行的程序员一天就能搞定资深程序员一周的工作,生成一个品牌官网最快只需5分钟。
除了模型本身,Qwen还开源了一个很实用的工具——Qwen Code。这是一个基于Gemini Code分支而来的智能体编程命令行工具,专门为Qwen3-Coder做了定制提示和函数调用协议的适配,能充分发挥模型在智能体编程任务上的实力。
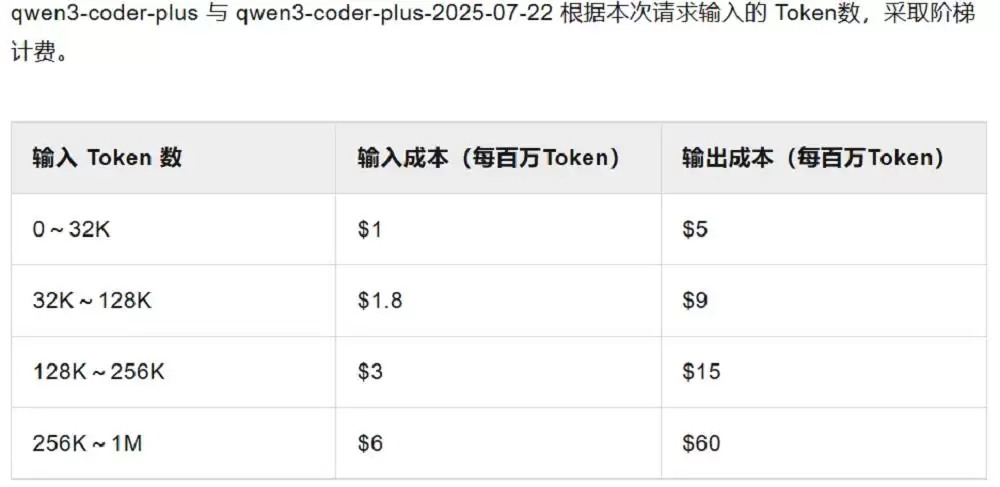
这个模型已经在阿里云旗下的百炼平台上上线了。API采用阶梯计价方式,输入token量越大,单价越便宜。在256K~1M这一档,输入价格是6美元/百万token,输出是60美元/百万token。对比一下,Claude Sonnet 4的输入输出价格分别是3美元/百万token和15美元/百万token,这个价格水平和Qwen3-Coder 128k~256k那一档差不多。
另外,Qwen Chat网页版也能直接体验Qwen3-Coder,而且完全免费。480B版本已经在Hugging Face、魔搭这些开源社区发布了,可以下载和本地部署。Qwen团队还专门发了一篇博客文章,详细分享了模型的技术细节。
在Qwen团队正式官宣之前,这个模型其实已经在Qwen Chat官网悄悄上线了。手快的海外网友们贡献了一大批实测案例。
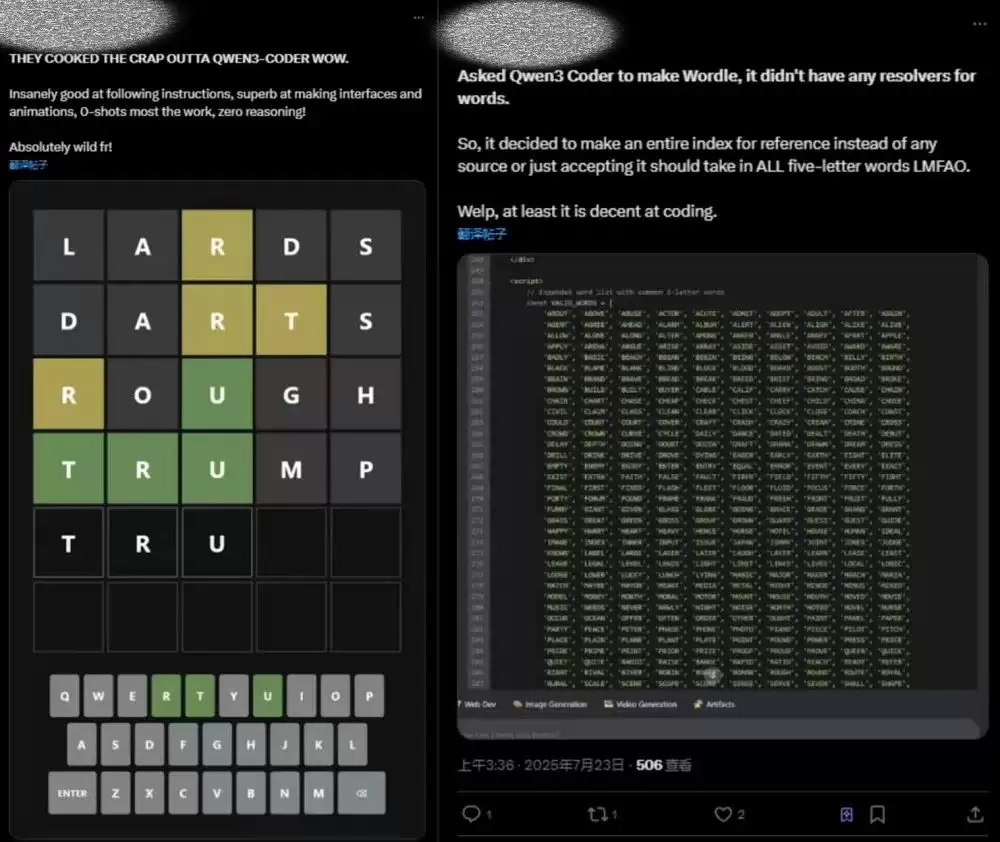
有网友让Qwen3-Coder做一个Wordle单词游戏——规则是六次尝试之内猜出一个五个字母的单词。结果呢?模型交付的页面和源代码都相当完整。这位网友的评价是:指令遵循、UI设计、动画方面的能力都“惊人”,大部分测试结果一次就跑通了,完全不需要推理。不过也有一点小遗憾:在Wordle游戏设计这个任务上,Qwen3-Coder没有使用现成的单词解析器,也没有引用来源,而是自己枚举所有五个字母的单词。
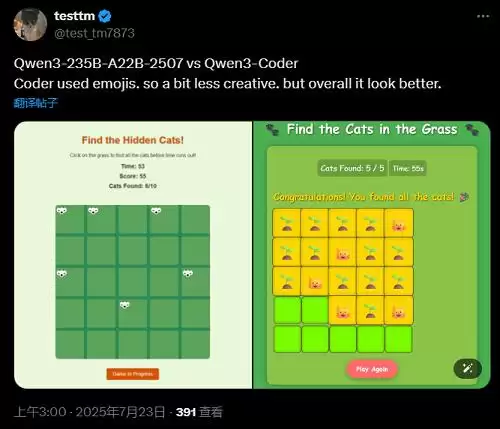
另一个找不同游戏的开发案例也很有意思。跟昨天发布的Qwen3-235B-A22B-2507相比,Qwen3-Coder在审美和完成度上明显高出一截。
智东西团队也做了一轮测试——让Qwen3-Coder开发一个中英文术语库,要求支持增删改查这些基础功能。直观感受是:因为没开启推理,开发速度快得惊人,20多秒就出了初步结果。后续修改时速度同样很快。
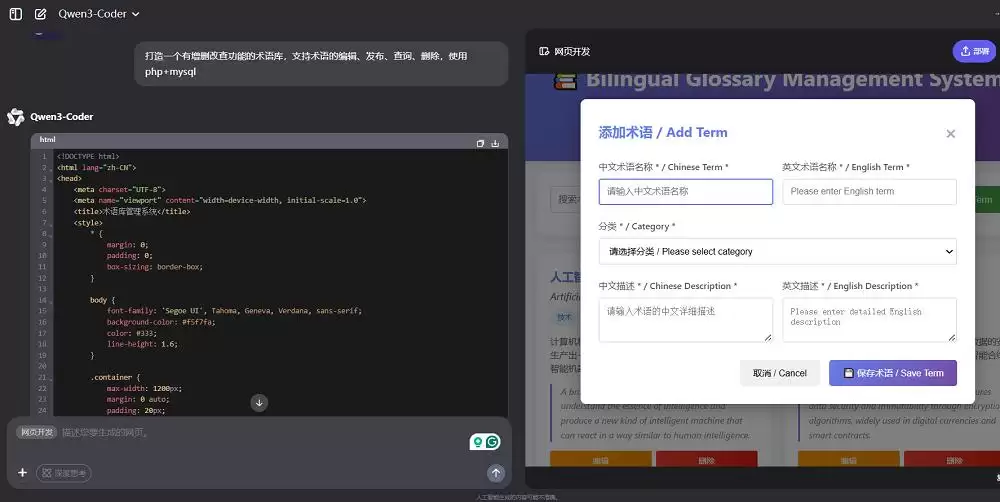
最终交付的结果从UI角度看确实美观清晰,功能运转正常。但有一点需要注意:它并没有遵循提示词里“使用PHP+MySQL进行开发”的指令。如果把这个结果当作功能演示或原型展示,那完全够用;但真要放到真实部署场景里,可扩展性还有优化空间。
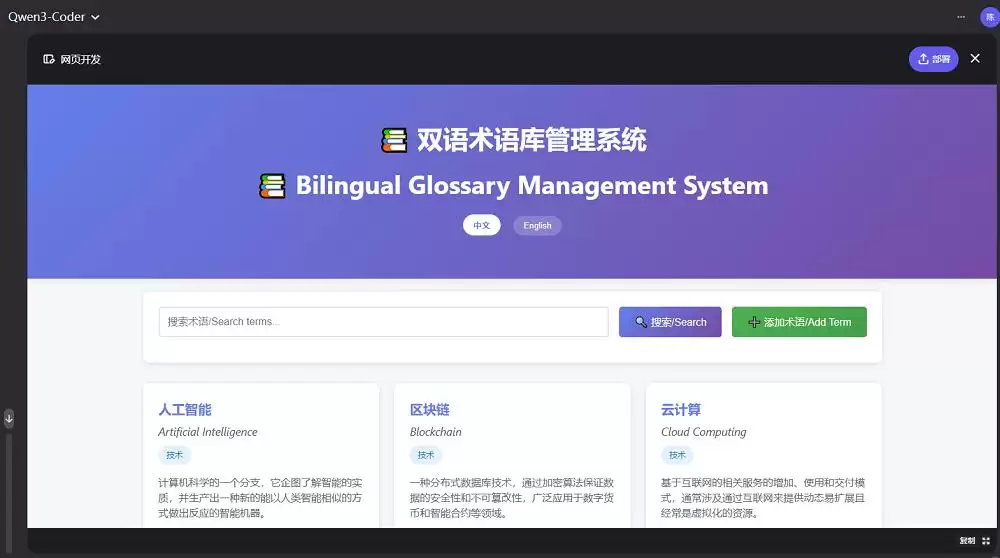
智东西还让Qwen3-Coder自己出了一道3D HTML开发题——创建一个3D旋转的立方体展示台,六个面显示不同颜色,自动旋转,还要有光照效果和阴影。结果完成度相当不错,主要功能基本实现,旋转动效和阴影处理都很到位。

编程能力之外,Qwen3-Coder还提供了不少其他玩法,包括图像生成、视频生成,还支持文档、图片、视频、音频等文件上传。这些功能应该是通过工具调用实现的。
正式发布后,Qwen官方也放出了一些实际用例。比如让它做一个基于物理的烟囱拆除模拟,带有受控爆炸效果。

又比如打造一个可互动的太阳系模拟,行星之间的关系基本准确。

开发出来的网页小游戏完成度也不错。

02 预训练仍有扩展空间,在20000个独立环境进行强化学习
Qwen团队在技术博客里分享了一些训练细节,其中一个判断很有意思:预训练目前仍有进一步提升的空间。
预训练阶段,Qwen3-Coder使用了7.5万亿token的数据,其中代码占70%。这也是为什么它在编程方面表现出色,同时还能保留通用能力和数学能力。
上下文方面,原生支持256K,通过YaRN可以扩展到1M,针对仓库规模和动态数据(比如拉取请求)做了专门优化,就是为了适配智能体编程场景。
值得注意的是,上一代模型Qwen2.5-Coder被用来扩展合成数据——具体来说,Qwen2.5清洗并重写了噪声数据,从而提升了整体数据质量。
后训练阶段,Qwen团队有一个核心观点:跟普遍关注竞赛级代码生成不同,所有代码任务都天然适合做执行驱动的大规模强化学习。所以他们在更广泛的现实世界编程任务上扩大了代码强化学习的训练规模。
通过自动扩展多样化编程任务的测试用例,团队创建了高质量的训练实例,进一步释放了强化学习的潜力。结果不仅提高了代码执行成功率,还给其他任务带来了额外收益。
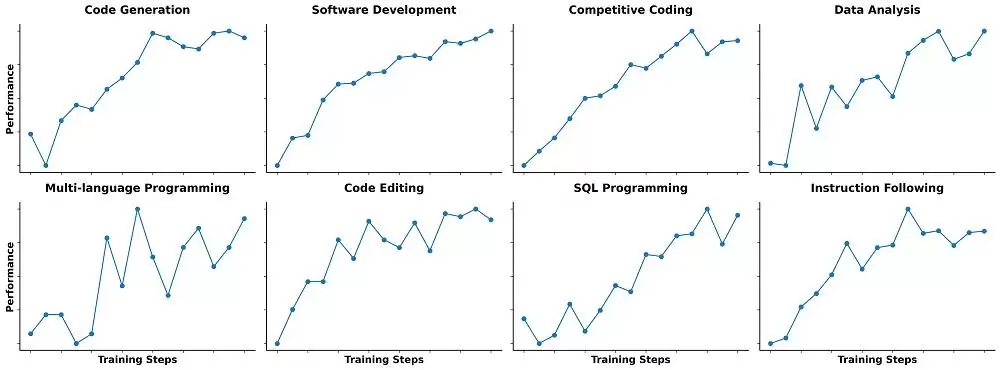
这也激发了团队进一步探索那些“难解决但易验证”的任务类型——这很可能会成为强化学习的新沃土。
在现实世界的软件工程任务(比如SWE-Bench)中,Qwen3-Coder需要与环境进行多轮交互,涉及规划、使用工具、接收反馈和做出决策。在Qwen3-Coder的后训练阶段,Qwen团队引入了长视距强化学习(也就是智能体强化学习),鼓励模型通过使用工具进行多轮交互来解决现实世界任务。
智能体强化学习的关键挑战在于环境扩展。为了解决这个问题,团队构建了一个可扩展的系统,能够并行运行20000个独立环境。这个基础设施为大规模强化学习提供了必要的反馈,也支持大规模评估。
最终,Qwen3-Coder在SWE-Bench Verified中实现了开源模型的最佳性能,而且没有使用推理(测试时扩展)。
同时开源的Qwen Code是一个供研究使用的命令行界面工具,基于Gemini CLI开发,针对Qwen-Coder模型做了增强的解析器和工具支持。另外,如果你更喜欢Claude Code,也可以用它和Qwen3-Coder一起编程——只要在Dashscope平台上申请一个API密钥,再装好Claude Code就行。
03 结语:更多尺寸即将推出,探索编程智能体自我提升
在Cursor对Claude等编程模型断供的背景下,Qwen3-Coder的开源给国内开发者提供了一个最新的替代选项。Qwen团队透露,他们还在继续提升Coding Agent的性能,目标是让它承担软件工程中那些复杂和乏味的任务,从而释放人类的生产力。
更多尺寸的Qwen3-Coder即将推出,可以在部署成本和性能之间找到更好的平衡。另外,团队也在探索一个很有意思的问题:Coding Agent能不能实现自我提升?
