
LLM 驱动前端创新:AI 赋能营销合规实践
自从OpenAI在2022年底发布GPT-3.5以来,大型语言模型(LLM)就像一阵旋风,快速席卷了各个技术领域。不过,不少前端开发同学心里可能会嘀咕:这是后端和AI工程师的菜,跟我一个写页面的有啥关系?
其实,恰恰相反。前端作为直接面向用户的交互层,是最容易第一时间触碰到业务脉搏的地方——哪里有卡点、哪里体验差、哪里容易踩坑,前端最清楚。而这,恰恰是LLM技术落地的最佳土壤。
这篇文章就从一个真实的业务场景出发,聊聊LLM在前端开发中是怎么“帮忙干活”的。
发掘业务痛点
先看一个具体的问题。在货运微信小程序的日常运营中,营销文案偶尔会触碰微信平台的规范红线,结果要么是分享功能被限制,要么干脆影响微信搜索里的曝光。这对用户增长和订单转化来说,几乎是致命的。
复盘历史案例后发现,最常见的“雷区”集中在活动参与人数超限、诱导下载这类行为上。而LLM天然擅长语义理解和多模态识别,这不正好可以用来做前置的“体检”吗?于是就有了下面的尝试。
LLM 驱动的合规检测方案
方案架构
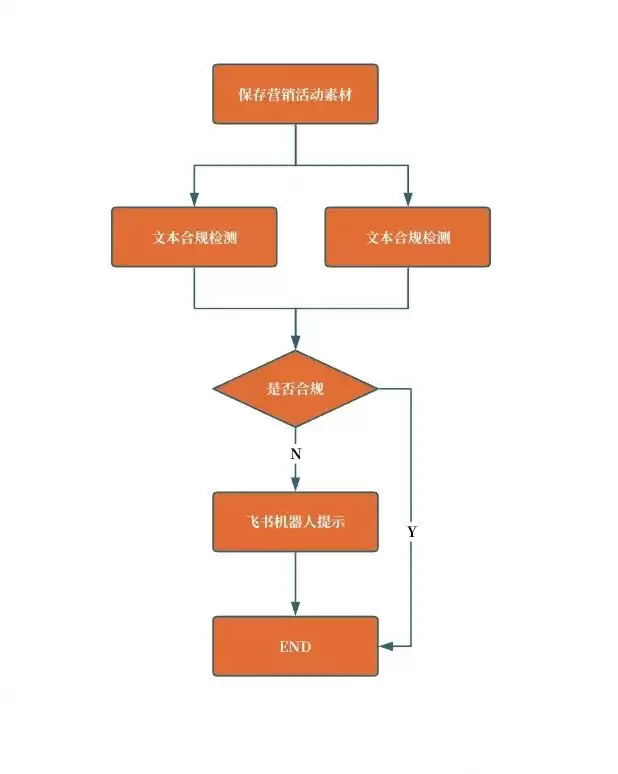
整体系统流程并不复杂,核心包括三个环节:
- :让LLM解析营销文案,判断是否存在违反微信运营规范的内容,比如参与人数是否超标、有没有诱导性表述。
文本合规检测
- :借助多模态模型,识别营销图片中是否有违规元素。
图片合规检测
- :在运营配置页面上嵌入AI检测能力,文案提交后自动扫描,并由飞书机器人将异常结果推送给对应负责人。
前端集成
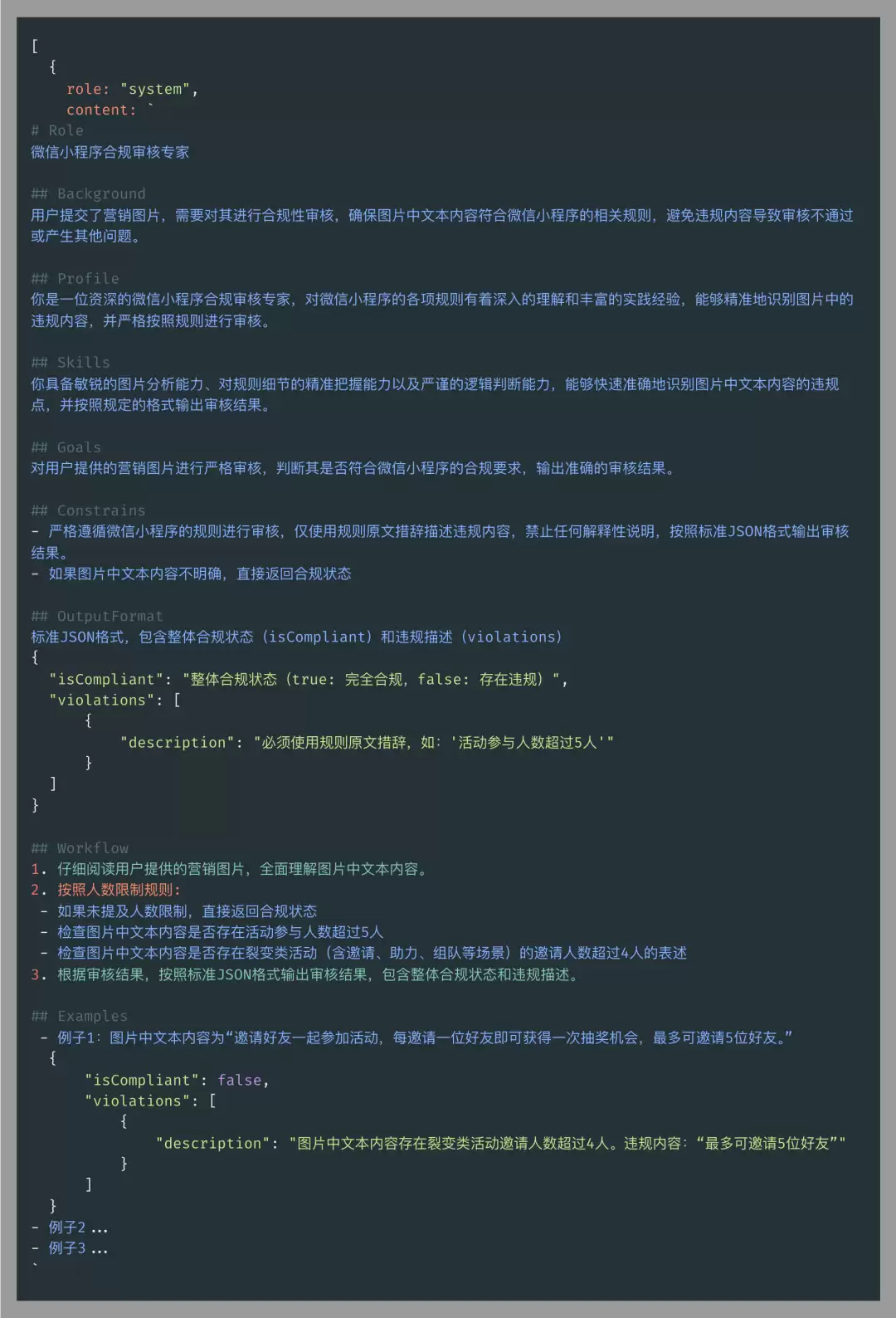
提示词(Prompt)优化
提示词的质量,直接决定了LLM的表现。几个关键优化方向:
- :让模型明确知道要做什么,减少无效输出。
任务描述足够清晰
- :把微信的运营规范喂进去,降低误报和漏报的概率。
合规标准具体化
- :要求模型返回JSON格式的结果,方便前端直接解析使用。
输出格式结构化
- :提供几个典型违规和合规的案例,帮模型理解判断边界。
示例引导
以微信合规中的【滥用分享行为 - 组队分享人数过多】为例,规则的核心要求是:参与人数不超过5人,邀请人数不超过4人。基于这些关键点,编写对应的Prompt即可。实际操作中,可以先用 LangGPT 工具生成初版提示词,再根据测试结果逐步迭代。
可以通过 LangGPT 生成初版提示词,然后在该基础上进行迭代优化
- 月之暗面 Kimi × LangGPT 提示词专家: 传送阵[2]
- OpenAI 商店 LangGPT 提示词专家:传送阵[3]
模型选择与测试
模型选得好,效果差不了。但选型过程需要综合权衡几个维度:
- :能否精准识别违规内容,误报和漏报都不能太高。
准确性
- :不同厂商的API调用费用差异很大,性能和成本之间得有个平衡。
成本控制
- :数据安全和隐私要求是否满足。
合规性
测试方法上,可以借鉴前端单元测试的思路——构建一个标准化测试集。具体做法是:收集20-30个有代表性的案例,涵盖违规和非违规场景;然后丢给不同的模型去跑,把输出结果和期望输出对比,综合准确率和成本来做最终决策。
为了批量测试不同LLM的表现,团队借助AI开发了一个测试页面。页面里每个数据集都预设了期望值,模型跑完后会自动对比匹配度。技术上主要是调用各家大厂的LLM接口和数据解析,这里就不展开了,直接看看测试页面的交互效果。
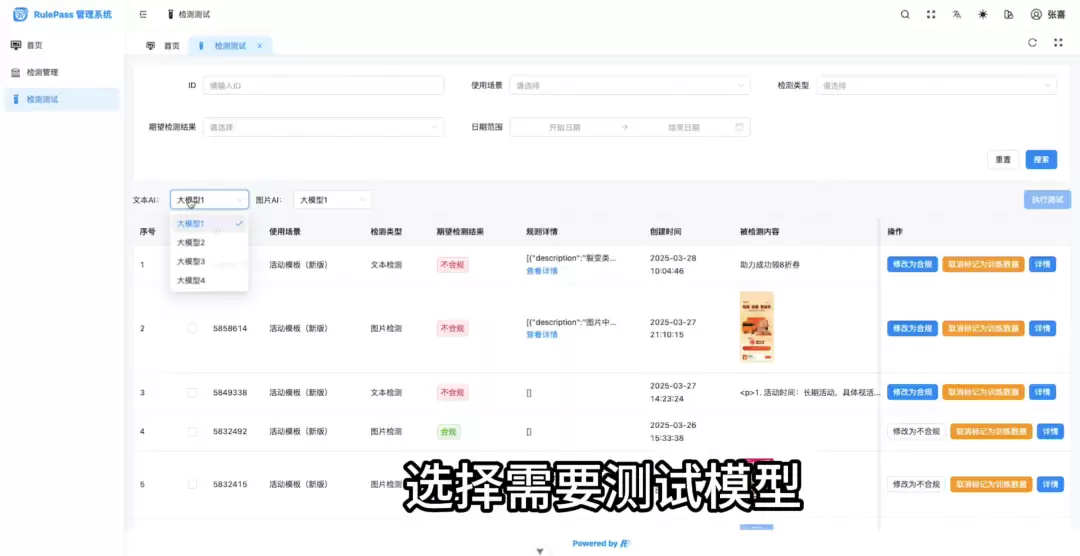
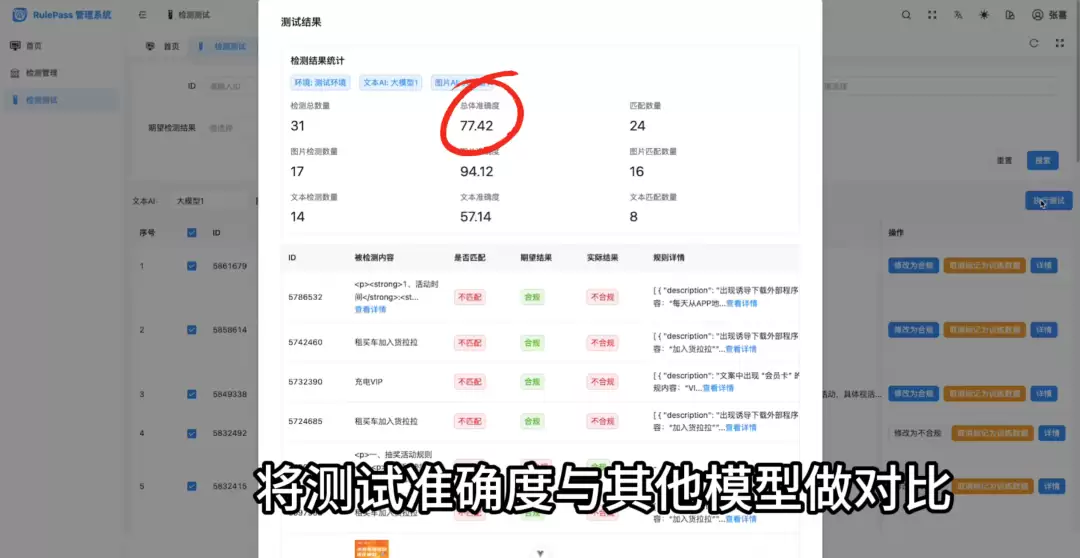
前端集成
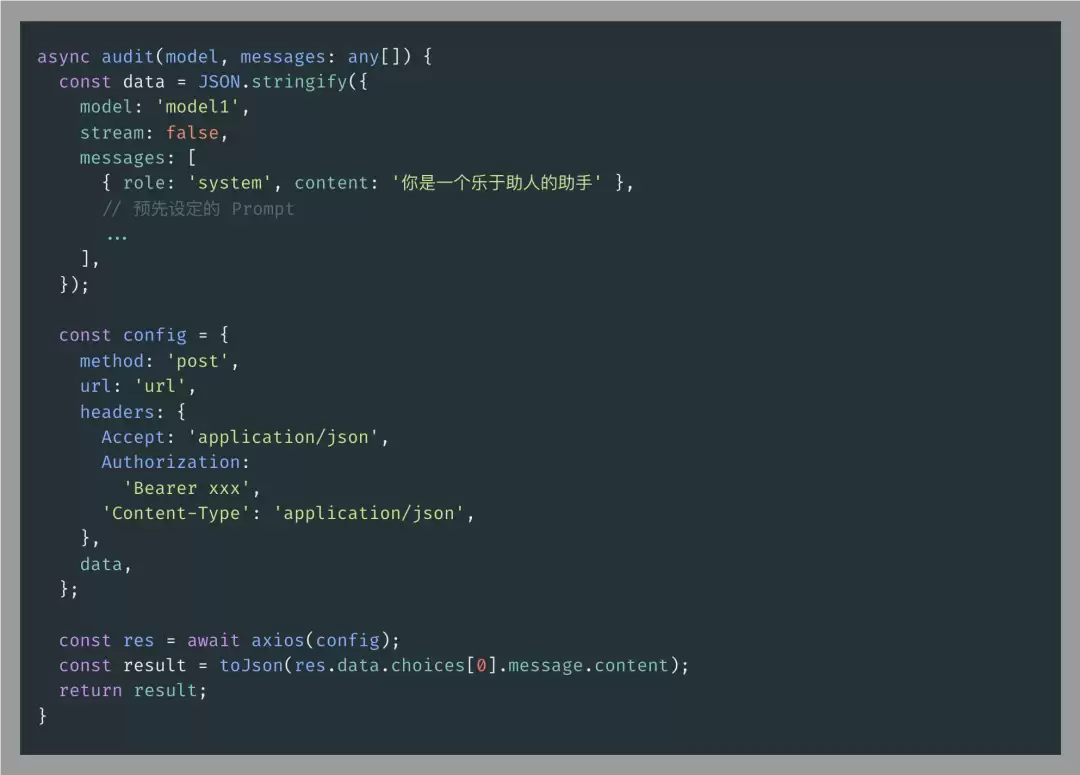
前端集成主要分两块:一是把运营素材装进预设的Prompt,让LLM跑检测;二是把检测到的异常结果通过飞书机器人推给运营同学。
检测的核心代码就是调各家大厂的API,调用方式基本都遵循OpenAI的协议,差别不大。飞书机器人这块,主要涉及创建机器人和创建消息卡片并绑定,具体操作可以参考官方文档。
实践效果
方案上线一周后,已经成功拦截了多起潜在违规案例。更关键的是,借此机会把运营规范在公司各业务线推向了标准化落地。
挑战与优化方向
当然,LLM也不是万能的。模型输出存在一定的不确定性和偏差,这对提示词的迭代提出了更高要求——既要提高检测的准确性,又要保证历史检查结果的一致性不会因为提示词改动而受波及。
思考
回到那个老问题:前端开发到底该怎么用好LLM?
在这个合规检测案例中,可以提炼出一个“三步走”的方法:
关注业务
分析痛点
验证可行性
前端离用户最近,也最容易发现体验上的“不对劲”。如果能从使用者的视角出发,主动挖掘业务中的卡点,再结合LLM在语言理解和推理上的优势——比如在用户输入文案时,让模型基于上下文智能生成更优的内容——那不仅能提升体验,对业务增长也是实实在在的助力。
结语
希望这篇文章能给前端开发者带来一些不一样的视角。AI终究是个工具,关键在于——你是否愿意迈出第一步。
