
MLLM在电商域互动内容生产的实践
探索电商领域AIGC技术的最新实践和创新成果。
作为一种新的商品表现形态,内容几乎存在于手淘用户动线全流程——从信息流种草、搜索决策到详情页种草,无处不在。过去一年,通过在视频生成、图文联合生成等核心技术上持续攻关,AIGC内容生成在手淘多个场景已经取得了规模化落地的实际价值。这篇专题算是摸索出的部分实践经验总结。

项目背景
在内容互动业务应用中,数据形式五花八门。下游应用通常需要结合多种模态输入,才能满足不同业务需求。MLLM已经在多个理解和生成任务上展现出显著优势,将其与内容互动业务结合起来,提升各方面效果,成了当务之急。

任务拆解
数据目标:
模型目标:
- 有效融合文本、视频、音频等多种模态,增强模型对信息的综合理解能力,使其能够应对多种输入模态并做出正确输出。
多模态结合:
- 通过分析学习用户的行为和偏好,调整模型输出以更好地符合人类预期。包括在生成内容时考虑用户个性化需求和期望,确保模型决策与人类意图高度一致。
人类偏好对齐:

解决方案
▐ 1. 融合人类反馈的多模态reward模型
任务背景
多模态语料库数据量庞大,噪声也不少。如果不加处理直接拿去训练模型,会带来两个问题:噪声数据会干扰学习过程,让模型跑偏;庞大的数据量也会严重拖慢训练速度,造成资源浪费。因此,先进行数据清洗和过滤,提高数据质量,是提升模型整体表现和训练效率的前提。

噪声样本分类
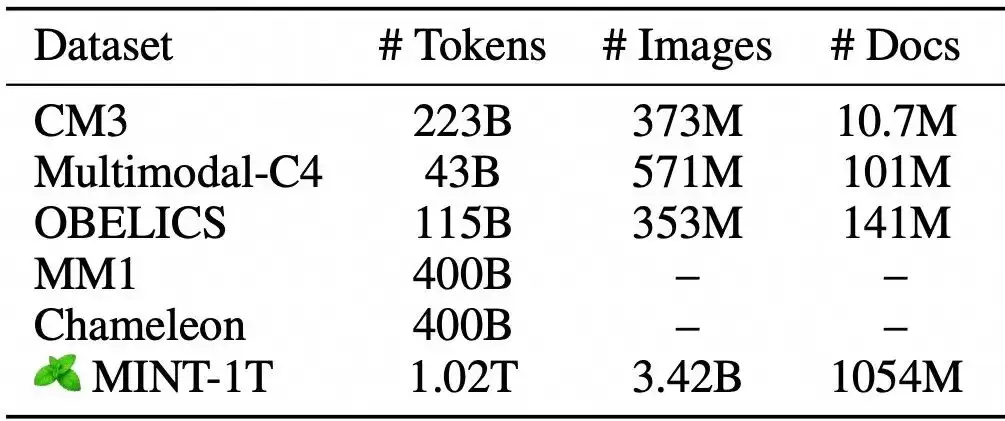
多模态数据量
解决路径
现有的方案大多依赖CLIP Score、BLIP Score这类指标——它们本身来自预训练模型,而预训练模型通常是在噪声较大的数据上训练的,这很容易让错误和不匹配的情况在筛选过的数据中延续下去。针对这个问题,我们提出了一种新算法,创新性地引入人类知识来过滤高质量的图文对齐数据,构建了一个多模态reward模型。
算法设计
Overview: 整体大图
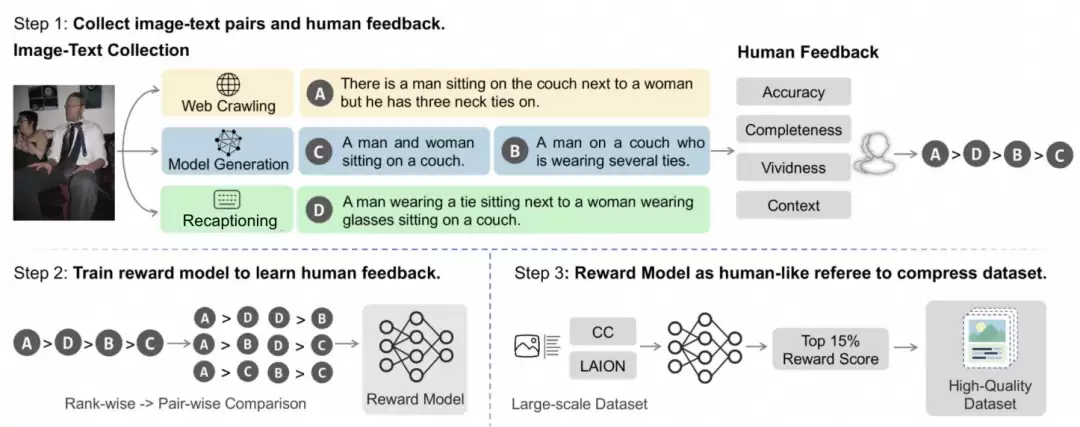
Step1. 偏好数据标注
从四个维度——准确度、完整度、细节度、背景感——来描述图像和文本的对齐性,得到人类打标的多模态偏好数据HF-dataset。具体来说,针对每个图像,需要做两件事:一是通过模型生成、人工标注等多种方式,生成不同粒度的caption;二是培训打标人员,对四个维度打分,拿到每个维度的准确分值。
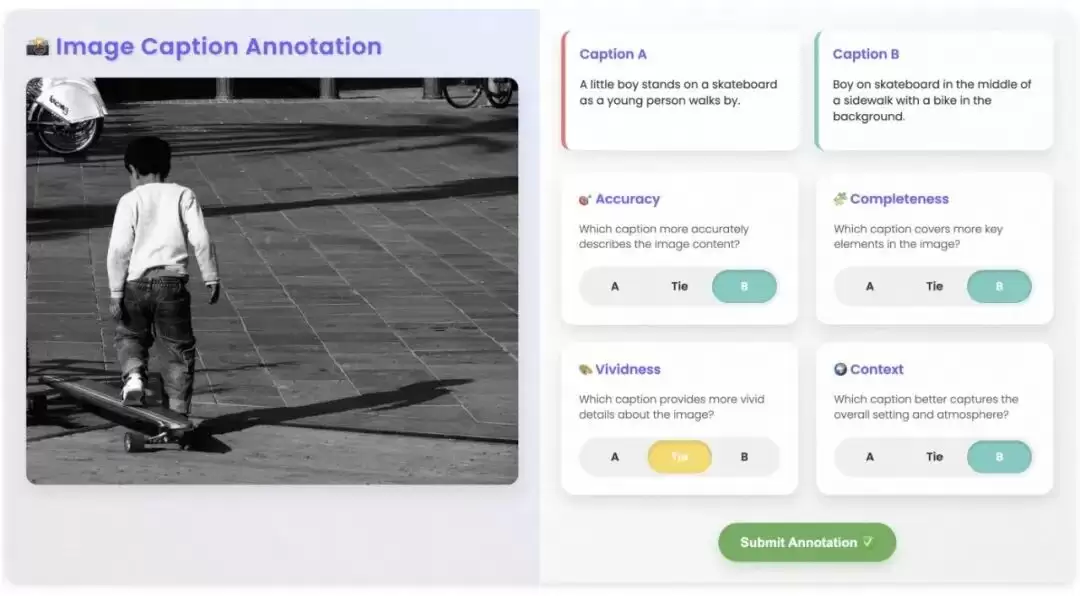
Step2. Reward Model训练
受InstructGPT的启发,训练了一个奖励模型,用来学习HF-dataset数据集中的人类标注知识。这个模型相当于一个自动化的标注工具,目的是帮助对齐图像和文本之间的对应关系。具体做法是把偏好标注转化为排名,把奖励模型的训练形式化为一个成对排名问题。对于HF-dataset中的每个图像I,会有m个由人类标注者排名的文本描述x1, x2, …, xm。如果xi优于xj,就组织成一个比较对(I, xi, xj),为每个图像生成多个比较对。再遵循Bradley-Terry模型来定义成对损失函数,优化模型拉远正负比较样本。
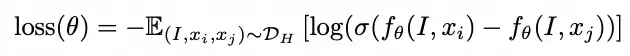
基于这个优化函数,最终得到一个细粒度理解人类打标员偏好的reward model。
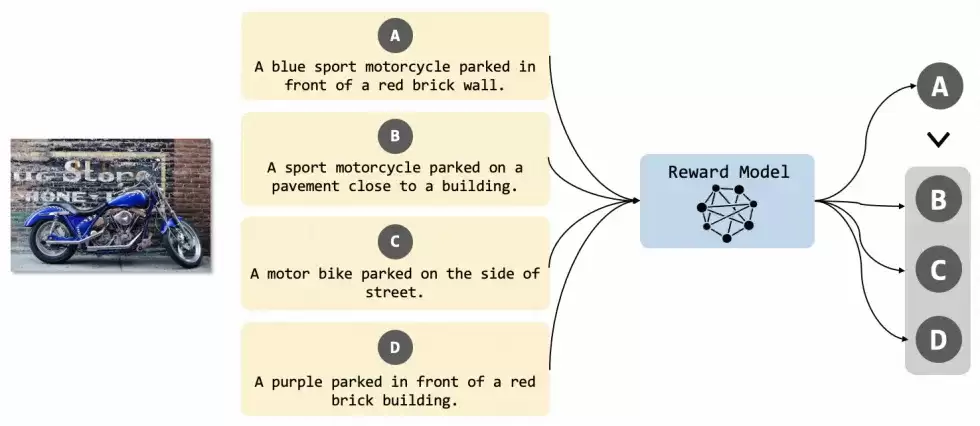
Step3. 高质量数据清洗
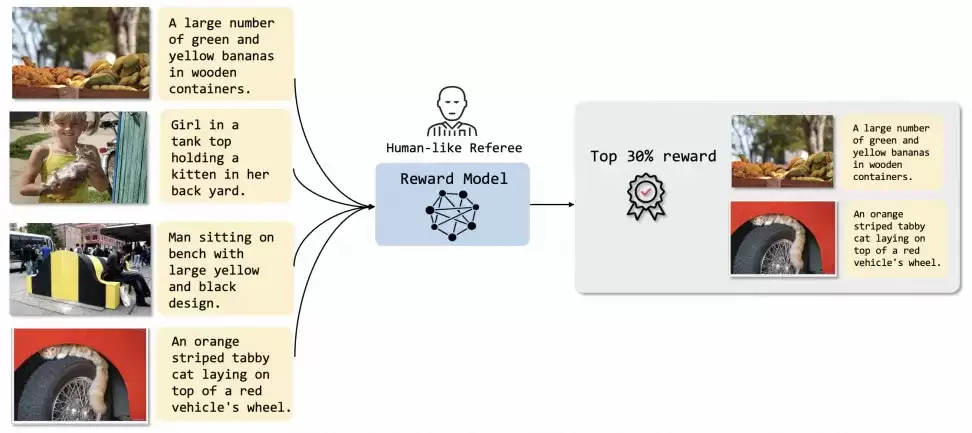
算法收益
- Reward Model清洗后的数据质量明显更好——相比全量数据训练,用清洗后的高质量数据训练,下游任务的表现有大幅提升。而且,这个Reward Model的效果也优于OpenAI CLIP等知名开源模型。
- 相关技术报告:Filter & Align: Leveraging Human Knowledge to Curate Image-Text Data
▐ 2. 音视频多模态的联合预训练
任务背景
视频本质上是多模态的——听觉和视觉信息并存。这不仅是视频的固有特征,也是人类感知和互动的基本方式。举个例子,看电影时同时接触视觉信息和听觉线索,能显著丰富观影体验,提升理解力和享受度。受这种内在体验的启发,让多模态模型同时具备理解视觉和音频的能力,可以在视频理解上带来质的飞跃。
结合音视频理解的典型case
解决路径
提出了一个音视频MLLM架构,协同对齐视觉和音频信号,实现充分的视频理解。关键点有两个:一是提出了一种模态增强方法,促进视频中视觉和音频信号的充分对齐;二是提出了一套高质量音视频指令数据生成方案,自动将视觉/音频-文本对构造为包含多轮对话和复杂推理的细致指令数据。
算法设计
Overview:整体大图
Step1. 指令数据构造
当前,音频和视频信息融合领域的指令数据还远远不够。为了解决这个问题,利用开源模型,针对视频帧和音频信号生成密集的字幕(caption),再结合GPT-4,生成音视频对齐的问答对(QA对),涵盖多轮对话、复杂推理和视频描述等内容。
Step2. 音视频模态对齐
基于第一部分的多模态reward模型,对生成的数据进行筛选,得到高相关性的百万级视频和图文评论数据,用于通用音视频的模态对齐。
Step3. 指令跟随强化
使用音视频指令数据和偏好数据,分两阶段走:一阶段用SFT提升指令跟随能力,二阶段用RLHF对齐用户偏好。
算法收益
- 所提出的方案在多个数据集上表现亮眼——视频QA: MSR-VTT-QA R1@60.4,ActivityNet-QA R1@50.6,音视频QA: MUSIC-A VQA R1@47.9,均超过Video-LLaMA和Video-LLaVA,达到了SOTA水平。
- 相关技术报告:Audio-Visual LLM for Video Understanding
▐ 3. 多模态专家模型的细粒度蒸馏
任务背景
随着业务精细化运营的需求越来越高,模型需要针对不同内容精准控制风格、字数等关键要素,这要求模型具备强大的多维度、细粒度理解和生成能力。同时,MLLM的推理成本相比传统小模型大了不少,如何在大流量场景下平衡性能和效果,也是一个绕不开的问题。
解决路径
解决方案是结合多专家机制(MOE),让每个专家负责不同的关键要素,同时引入知识蒸馏技术,以“先模仿再超越”的范式,将大模型的能力迁移到MOE小模型中,提升MOE小模型的复杂理解和幻觉消除能力。
算法设计
Overview: 整体大图
Step1. 模仿蒸馏
在模仿蒸馏阶段,MOE小模型先学会大模型里的复杂知识。这个过程包含两个阶段:通用知识和复杂知识,采用“general-to-specialized”的方式,引导MOE小模型逐步学习。
模仿蒸馏
Step2. 偏好蒸馏
MOE小模型存在比较严重的幻觉问题。通过大模型提供的关于“好”样本和“坏”样本的知识,为MOE小模型建立基础参考,提升其判断能力,使它在减少幻觉方面的能力得到大幅提升。
算法收益
- 提出的MOE小模型在复杂理解能力和幻觉消除能力上表现都很出色。相比同尺寸的MiniCPM-V、DeepSeek-VL等模型,这个方案只用了不到1%的数据,性能反而更有优势。
复杂理解能力
幻觉消除能力
- 相关技术报告:LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation
总结
在电商领域,MLLM在互动生产上已经取得了显著的阶段性成果。通过利用多种数据源和用户交互信息,MLLM在内容冷启、消费提升等方面都交出了不错的答卷。展望未来,将进一步探索如何更好地结合业务目标与用户兴趣,更精准地服务业务——比如利用用户画像及实时反馈,生成高度个性化的互动内容,切实提升用户的参与感和购买意愿。
