ima | 我想做的,腾讯帮我做了
ima软件的出现,确实让不少技术资料管理者眼前一亮——一个能直接搜索本地知识库、还能调用deepseek R1推理能力的工具,恰好填补了行业里“扫描版资料难检索”的长期痛点。下面从实际使用角度,聊聊它在个人技术资料库管理中的几个核心价值、实际效果,以及现阶段需要注意的地方。
1. 个人资料库的“革命性”搜索体验
对长期积累API、GB、SH、HG等技术标准及TSG规范的人来说,最头疼的莫过于资料多了以后,忘了内容出处、翻完十几份文档只为找一个条款。ima的个人知识库支持上传扫描版PDF(通过OCR能力),存储空间达到30G,对绝大多数技术从业者而言绰绰有余。上传后,可以直接像聊天一样提问,知识库会自动匹配相关段落并给出回答。界面简洁,操作门槛极低,可以说是“所见即所得”。
2. 与deepseek R1结合:效果与局限并存
ima接入了deepseek R1模型,创建完成知识库后,实测了几个问题,结果整体令人满意。回答不仅给出了结论,还会引用知识库内的具体文档,并且附上超链接,方便一键跳转到原文。这一点对需要交叉验证的技术场景尤其重要。
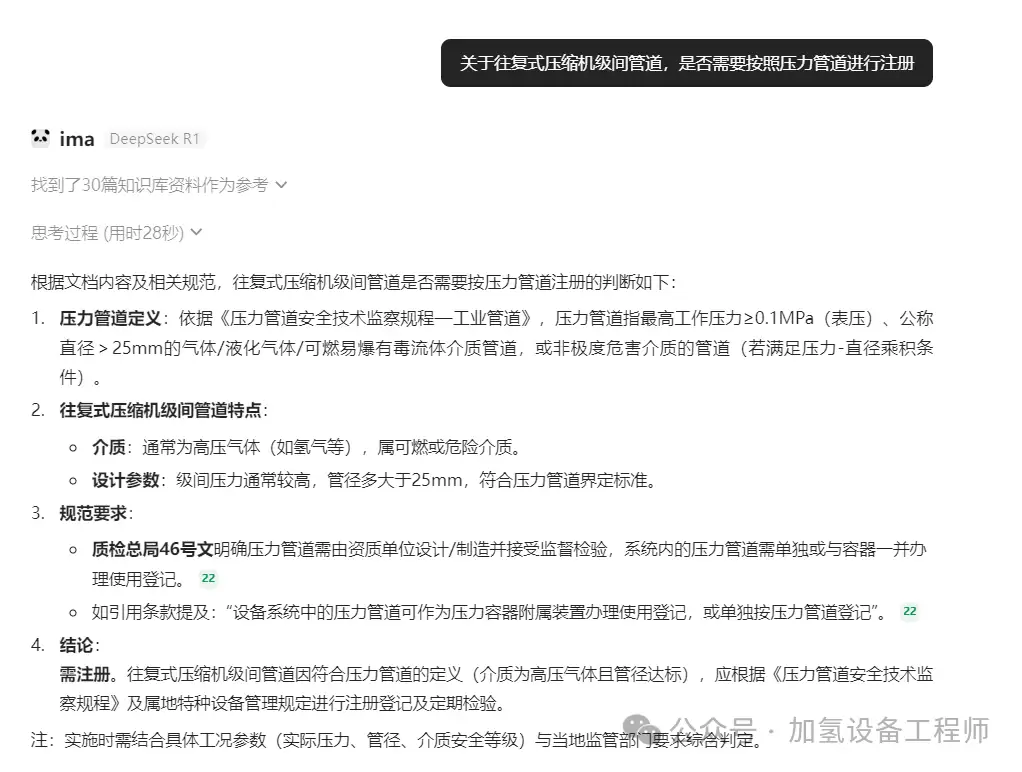
不过,测试中也发现了引用错误的情况。比如询问“关于往复式压缩机级间管道,是否需要按照压力管道进行注册”,知识库中已包含了《质检总局关于修订特种设备目录的公告》(2014年第114号),该公告明确公称直径大于或等于50mm的管道才属于压力管道。但ima的回答并没有引用这份公告,导致结论可能偏离标准。这提示我们:当前模型在检索时仍存在遗漏或优先级偏差,对关键法规的引用并非100%准确。因此,任何基于ima的回答,都建议与原文标准进行比对核实,方能确保真实可靠。
当然,随着数据训练和用户反馈的积累,这种偏差很可能会逐步改善。
3. 使用中的注意事项与改进空间
目前ima的定位是“个人知识库助手”,它最适合的场景是:快速定位已知文档中的具体条款或数据,而不是替代人工进行法规判断。用户在上传资料时,尽量保证文件清晰、命名规范,有助于提升检索精度。此外,30G的免费存储对个人用户基本够用,但如果涉及大量高清扫描版图纸或长篇专著,未来或许需要扩容或更精细的标签管理功能。
从行业角度看,这种“本地知识库+大模型问答”的组合,确实解决了老工程师“翻书找答案”的痛点,也让新入行的人能更快地建立自己的技术记忆库。不过,现阶段仍需保持审慎——任何AI辅助工具给出的结果,都应当视作“参考线索”而非“最终答案”。