
AI隐私训练时,那个最难控制的「阀门」能自动调节吗?
差分隐私训练社区又迎来了一个值得关注的新工作:SlaClip。这项来自英国南安普顿大学与广州大学研究者团队的成果,旨在为差分隐私随机梯度下降(DP-SGD)提供一种自适应的梯度剪裁方案。论文本身已被 ICML 2026 接收为 Spotlight,标题响亮——“SlaClip: Gradient Norm Slacks can be Indicator for Adaptive Clipping in DP-SGD”。

想要理解 SlaClip 的创新之处,可以先回顾一下传统的 DP-SGD 究竟是怎么运作的,以及现有自适应剪裁方法面临哪些瓶颈。
传统 DP-SGD 与自适应剪裁阈值方法
DP-SGD 是深度学习中实现差分隐私训练的经典利器。它的核心思想并不复杂:通过“逐样本梯度剪裁 + 高斯噪声”这套组合拳,限制单个样本对模型更新的影响力。其基本流程可以归纳为以下三步:
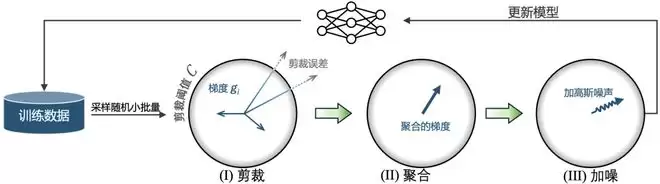


不过,固定剪裁阈值的方式局限性很明显。为了解决这个问题,此前已有研究者提出了 Adap-Clip 这类自适应剪裁阈值方法。其思路是实时追踪当前批次中未被剪裁的梯度所占比例,然后将剪裁阈值调向一个固定的目标比例——比如 50%。这种自适应裁剪的思想已经相当普及,像 Meta 的 PyTorch Opacus 和 Google 生态中的 TensorFlow Privacy 都已经将其纳入主流工具链。
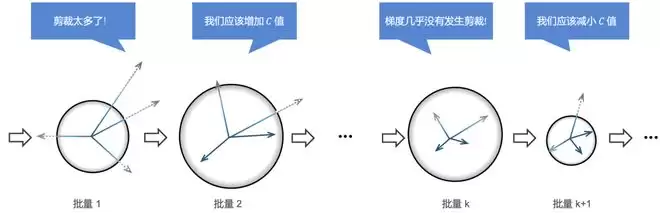
思路看似直观,但落地到差分隐私训练中,问题就来了:
首先,估计当前批次中未剪裁的比例,通常需要额外的隐私评估。这会消耗更多的隐私预算,或者被迫加入更强的噪声。其次,固定的目标未剪裁比例并不总能适应训练过程的动态变化。随着梯度范数分布不断演变,训练后期会出现大量小范数梯度,这些梯度对聚合更新的贡献很小,甚至容易被 DP 噪声淹没。如果机械地维持一个固定的未剪裁比例,剪裁阈值可能会持续下降,最终影响模型性能。
这正是 SlaClip 试图回答的难题:能否在不引入额外隐私查询的前提下,获取类似梯度范数分布的信息,用于自适应地调节剪裁阈值?
SlaClip 的核心观察:剪裁的 “slack” 不是无用信息


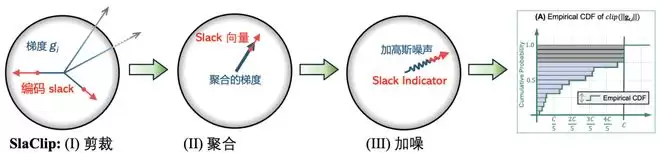
在这种设计下,SlaClip 做到了零额外隐私消耗,却能获得关于梯度范数分布的有用反馈信号。
Slack Indicator 得到的到底是什么信息?
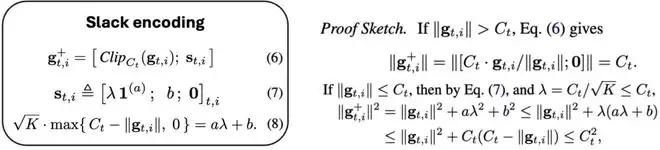
经过聚合、高斯噪声和归一化之后,SlaClip 输出的 Slack Indicator 可以理解为一个带噪声、分箱的累积分布函数(CDF)估计。具体如下:
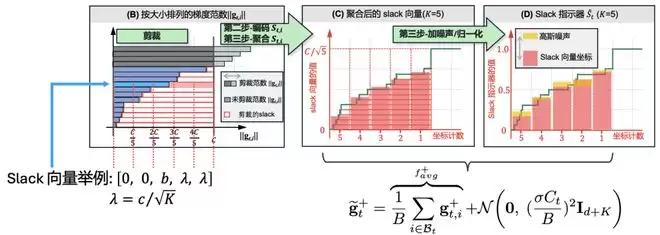
换句话说,Slack Indicator 不只是简单地告诉我们“有多少梯度被剪裁”,而是提供了更细粒度的分布信息:哪些梯度接近当前阈值,哪些梯度集中在较小的范数区域。
其中,靠近阈值的坐标可以提供类似未剪裁比例的反馈,在功能上与 Adap-Clip 使用的剪裁/未剪裁统计相接近。而 SlaClip 的独特之处在于,它额外利用了 CDF 中靠近零的坐标来估计小梯度比例,据此动态调节目标未剪裁比例,使剪裁阈值的更新更贴合当前训练阶段的梯度分布。整个过程在训练中持续进行,实现实时动态调节剪裁比例。
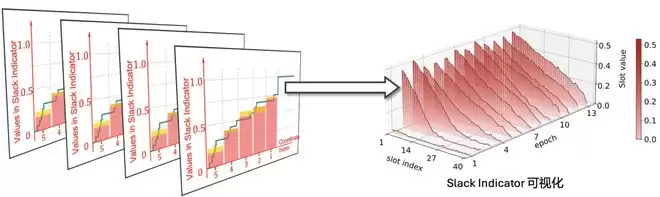
因此,SlaClip 同时克服了上文提到的现有 adaptive clipping 方法中的两个痛点:第一,无需额外的隐私评估就能获得更丰富的 CDF 信息;第二,动态调节未剪裁比例,有效避免了训练后期剪裁阈值不断下降的困境。
实验设计:相同参数池下的公平比较
为了公正地比较不同剪裁方法,论文采用了匹配相同隐私预算下的公平调参协议对比实验。对每个方法、数据集和隐私预算,都在相同的超参数池中进行网格搜索(grid search)。实验结果相当稳健:SlaClip 在多个数据集和隐私预算设置下取得了有竞争力的结果,常常能够达到最佳或第二好的差分隐私训练准确率。
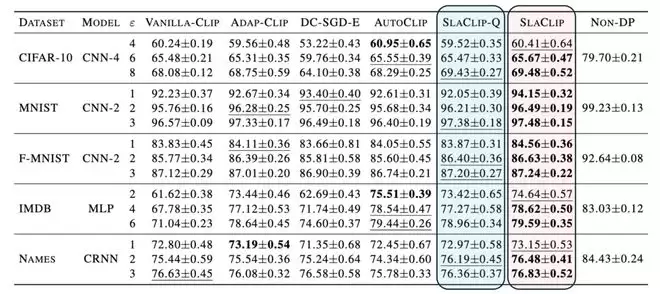

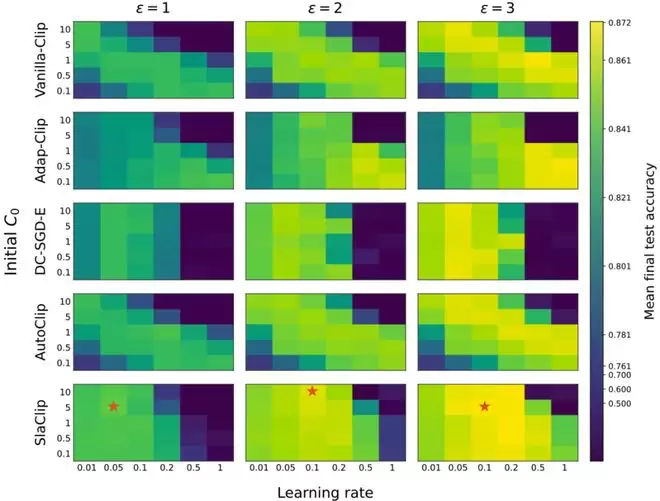

相比之下,一些传统自适应剪裁阈值方法的高精度区域更为集中,对学习率和初始阈值的组合也更加敏感。从实际效果来看,SlaClip 的 Slack Indicator 确实能够在一定程度上缓解初始剪裁阈值选择带来的不稳定性。
总结
综观全局,SlaClip 的特点可以归纳为三点:
第一,不引入任何额外隐私查询,这对隐私保护训练来说是个重要的优势;第二,它是“即插即用”式的设计,且额外计算开销很低;第三,提供了比单一剪裁/未剪裁统计更丰富、更有价值的分布信息。
