
Text2SQL零代码实战!RAGFlow 实现自然语言转 SQL 的终极指南
轻松实现自然语言到SQL的转换,无需微调大模型,RAGFlow带你走进Text2SQL的高效应用。
核心内容:
1. Text2SQL在企业级应用中的挑战与成本问题
2. RAGFlow框架:无需微调,配置少量数据实现精准SQL生成
3. 实际案例分析:多场景下的SQL查询与执行效果展示
“无需微调大模型,3步搭建企业级Text2SQL应用,让数据库‘听懂人话’!”
在企业大模型应用方面,Text2SQL一直是应用热点。大家都希望小嘴一张,就完成一系列数据提取和分析工作。
但是,使用大模型自动理解业务需求,实现SQL代码编写和代码执行一直都存在技术难点。传统的Text2SQL方案,往往依赖大模型微调,对于中小企业而言,带来非常高的应用成本。
今天,介绍一个方法,使用开源RAG框架RAGFlow,应用知识库检索与大模型推理结合,不需要对模型做任何微调,只需要配置少量结构化数据即可实现精准SQL生成,实现指定数据查询、复杂查询、计算,跨表计算等多种场景。
老习惯,先看效果,再看执行。
一、表内容和效果简单说明
数据库里存了四张表:用户表、制造商表、商品表和销售表。内容分别如下:
1- 表明细查询测试
问题:请问商品 智能手机 X 还剩多少库存。
难度分析:智能体需要理解问题所在的表,完成表格选择(商品表),字段查询(商品名称)和目标字段(库存)输出。
原表中符合要求的记录:
测试结果:通过,两条记录库存均完成识别和输出。
2- 表明细查询和合并计算
问题:请问商品 智能手机 X 还剩多少总库存。
难度分析:智能体需要理解问题所在的表,完成表格选择(商品表),字段查询(商品名称)和目标字段(库存)求和计算输出。
原表中符合要求的记录(同上):
测试结果:通过,两条记录库存均完成识别,并对库存求和输出。
3- 跨表关联
问题:请问商品 智能手机 X 的制造商是谁
难度分析:智能体需要理解问题所在的表,完成表格选择(商品表),字段查询(商品名称)和目标字段(制造商id)。并返回制造商表,使用制造商 id,提取制造商信息,再作输出。
原表中符合要求的记录:
测试结果:通过,两条智能手机 X 的制造商都是商家_001。
4- 复杂查询
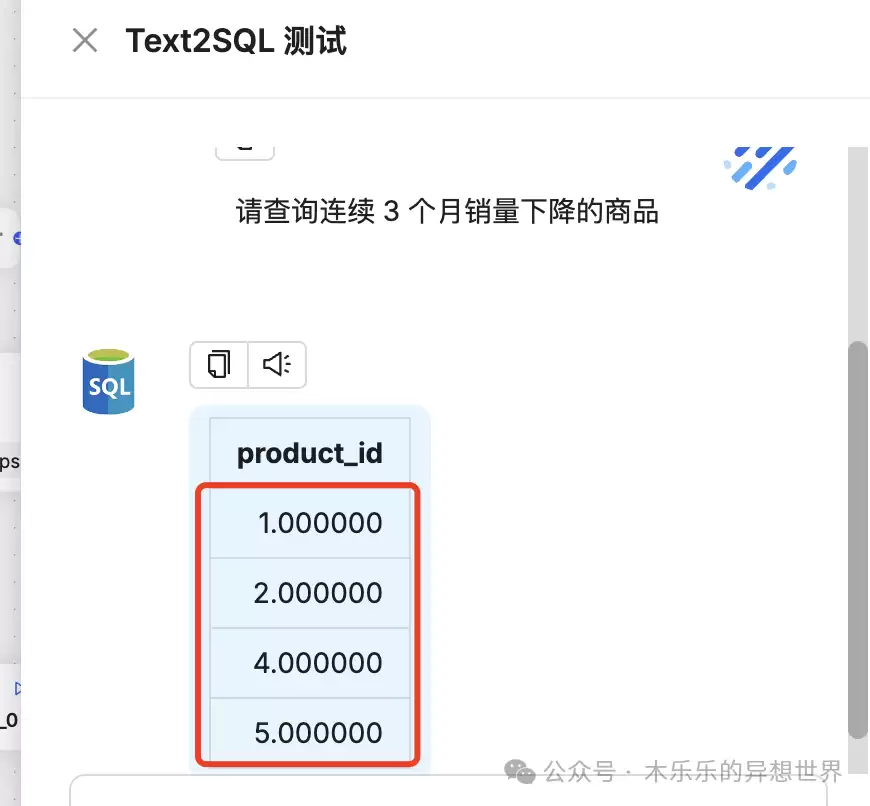
问题:查询连续 3 个月销量下降的商品
难度等级:?????
难度分析:智能体需要理解问题所在的表,完成表格选择(销售表),字段查询(商品名称)和目标字段(销量),进行复杂销量比对(连续 3 个月销量下降),并返回商品信息。
原表中符合要求的记录,分别有商品 1、2、4、5 这四个商品符合要求。
商品 1,8-10 月销量下滑。
商品 2,5-7 月销量下滑。
商品4,5-8 月销量下滑。
商品 5,4-6 月销量下滑。
测试结果:通过,4 个商品连续 3 个月销量下降,均被有效识别。
5- 指定要求复杂查询
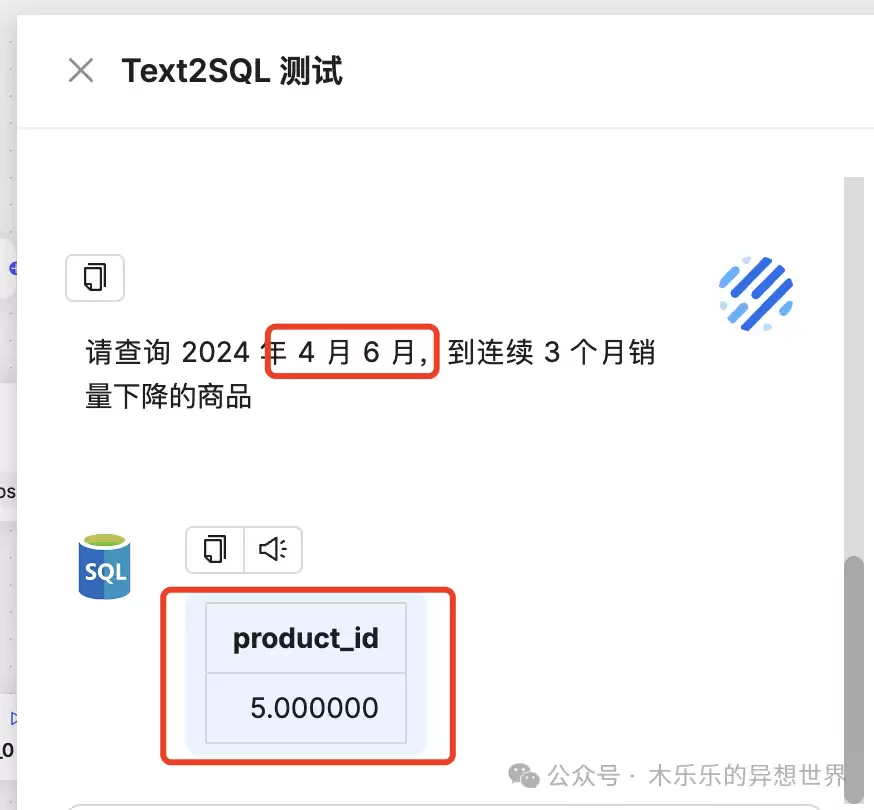
问题:查询2024 年 4-6 月,连续 3 个月销量下降的商品
难度等级:?????
难度分析:智能体需要理解问题所在的表,完成表格选择(销售表),字段查询(商品名称)和目标字段(销量),限定日期(4-6 月),进行复杂销量比对(连续 3 个月销量下降),并返回商品id。
原表中,只有商品5 符合要求。
测试结果:通过,商品5 ,被有效识别出。
6- 再上一点点难度
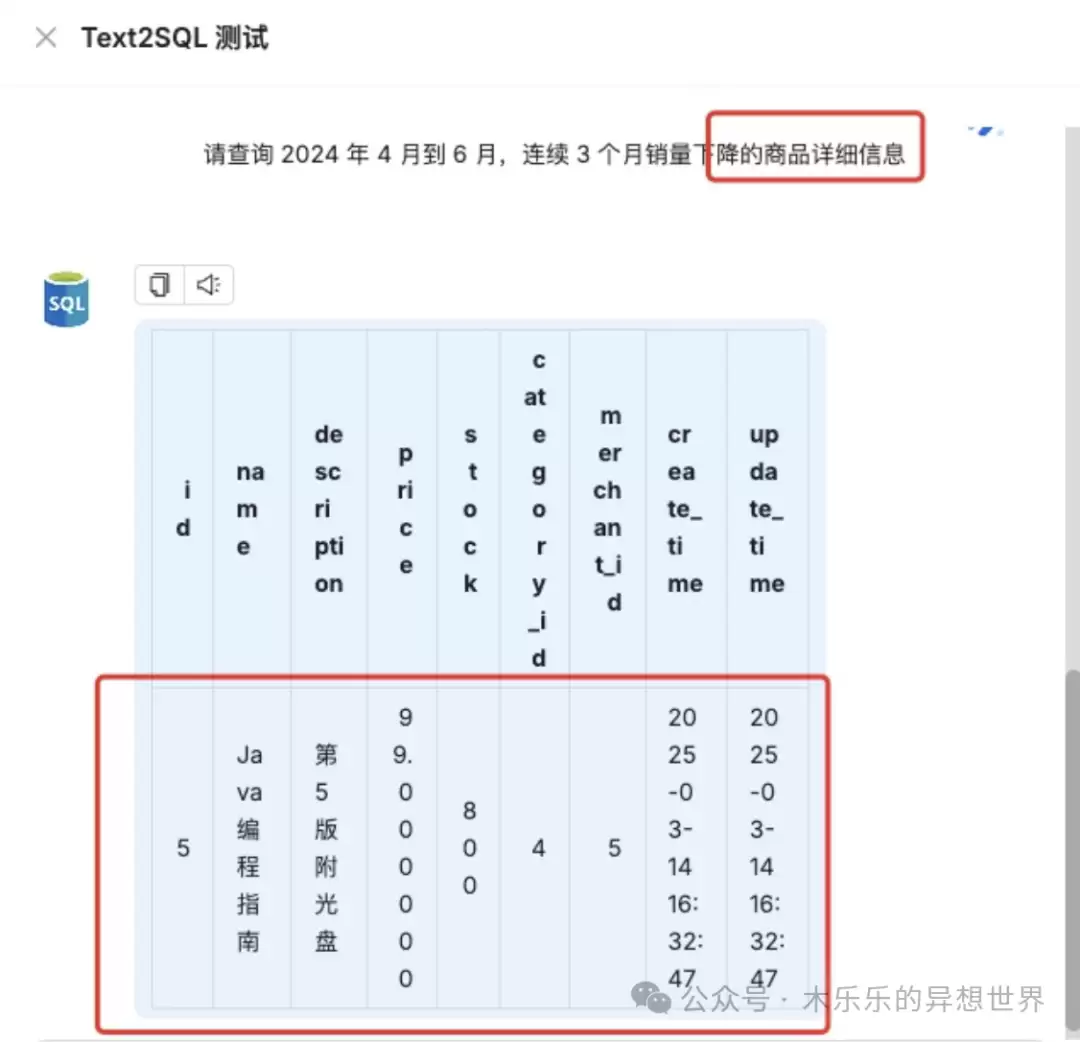
问题:查询2024 年 4-6 月,连续 3 个月销量下降的商品详细信息。
难度等级:?????
难度分析:智能体需要理解问题所在的表,完成表格选择(销售表),字段查询(商品名称)和目标字段(销量),限定日期(4-6 月),进行复杂销量比对(连续 3 个月销量下降),并返回商品id,找到商品明细。
测试结果:通过。
接下来,手把手演示如何用RAGFlow搭建一个能理解业务需求的Text2SQL智能助手。
所使用的RagFlow框架,感兴趣的可以自行安装。安装过程省略。
一、核心流程
这是官方教程提出的使用RagFlow解决Text2SQL的流程。
简单来说,就是准备好足够让大模型理解数据库内的表格、字段的知识库,以及理解从问题到SQL代表的问答方法。大模型就可以通过理解用户问题、查询知识库信息、形成SQL代码、并执行SQL,完成从指定数据库里提取相关信息的工作。
二、准备工作:3类核心知识库
关键点:Text2SQL的准确性取决于知识库质量,需提前准备以下数据(参考官方文档)
DDL知识库
作用:提供数据库表结构(如字段类型、主键约束)
CREATE TABLE `users` (
`id` INT NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) NOT NULL,
`password` VARCHAR(50) NOT NULL,
`email` VARCHAR(100),
`mobile` VARCHAR(20),
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_username` (`username`),
UNIQUE KEY `uk_email` (`email`),
UNIQUE KEY `uk_mobile` (`mobile`)
);数据来源:从HuggingFace下载标准模板
DB Description知识库
作用:解释字段业务含义(如“order_date”代表订单创建时间)
### 用户表(users)
用户表用于存储网站或应用的用户信息。以下是该表中每个字段的含义:
- `id`: 这是一个整数类型的自增字段,作为用户的唯一标识符(主键)。每次添加新用户时,该字段会自动增加,确保每个用户都有一个唯一的ID。
- `username`: 字符串类型,用于存储用户的用户名。用户名通常是用户登录时使用的唯一标识符。
- `password`: 字符串类型,用于存储用户的密码。出于安全考虑,密码在存储前应进行加密处理。
- `email`: 字符串类型,用于存储用户的电子邮件地址。电子邮件地址可以是用户的另一个登录凭证,并且用于接收通知或重置密码。
- `mobile`: 字符串类型,用于存储用户的手机号码。手机号码可用于登录、接收信息通知或进行身份验证。
- `create_time`: 时间戳类型,记录用户账户创建的时间。默认值为当前时间。
- `update_time`: 时间戳类型,记录用户信息最后更新的时间。每次更新用户信息时,该字段都会自动更新为当前时间。数据来源:从HuggingFace下载标准模板
Q->SQL知识库
作用:存储自然语言与SQL的映射样本,对最终SQL代码的可执行性影响至关重要。
示例:
- 用户问题:“查询2023年销量TOP10商品”
- 对应SQL:SELECT product, SUM(quantity) FROM sales WHERE YEAR(order_date)=2023 GROUP BY product ORDER BY SUM(quantity) DESC LIMIT 10;
数据来源:从HuggingFace下载标准模板
三、配置步骤
步骤1:创建DB Assistant Agent
- 进入RAGFlow Agent工作台,选择内置DB Assistant模板
- 绑定目标数据库(支持MySQL/PostgreSQL等)
步骤2:配置知识库参数(核心!)
DDL知识库配置:
使用General切割,块Token数选择8,分段标识符为;。当看到知识库内的分块已经实现一个表的建表语句一个块时,就代表配置成功。
DSL知识库配置:
同样使用General切割,但块Token数选择128,分段标识符为#。当看到知识库内的分块已经实现一个表的表及字段说明一个块时,就代表配置成功。
Q->SQL知识库配置:
这部分内容比较特殊,因为导入格式是csv,csv里有两列内容,分别是query和sql。例如:
所以,配置方法需要选择Q&A。当看到知识库内的分块已经实现Question和Answer这样规律问答对的时候,就代表配置成功。
步骤3:Agent配置知识库
Agent中的DDL选择数据库配置。接下来,依次如法炮制。
步骤4:测试与优化
进入Agent平台,点击“运行”按钮,就可以进行问答测试了。
案例:用户提问“我们现在有多少个用户”
好的,以上就是所有的执行步骤和过程了。
如果有不了解的地方,欢迎评论区留言交流。
附录:
1-用户表
用户表用于存储网站或应用的用户信息。以下是该表中每个字段的含义:
- id: 这是一个整数类型的自增字段,作为用户的唯一标识符(主键)。每次添加新用户时,该字段会自动增加,确保每个用户都有一个唯一的ID。
- username: 字符串类型,用于存储用户的用户名。用户名通常是用户登录时使用的唯一标识符。
- password: 字符串类型,用于存储用户的密码。出于安全考虑,密码在存储前应进行加密处理。
- email: 字符串类型,用于存储用户的电子邮件地址。电子邮件地址可以是用户的另一个登录凭证,并且用于接收通知或重置密码。
- mobile: 字符串类型,用于存储用户的手机号码。手机号码可用于登录、接收信息通知或进行身份验证。
- create_time: 时间戳类型,记录用户账户创建的时间。默认值为当前时间。
- update_time: 时间戳类型,记录用户信息最后更新的时间。每次更新用户信息时,该字段都会自动更新为当前时间。
2-商家表
商家表用于存储销售商品的商家信息。以下是该表中每个字段的含义:
- id: 这是一个整数类型的自增字段,作为商家的唯一标识符(主键)。
- name: 字符串类型,用于存储商家的名称或品牌名。
- description: 文本类型,用于存储商家的详细描述,可能包括商家简介、服务内容、联系方式等。
- email: 字符串类型,用于存储商家的电子邮件地址,可以用于联系商家。
- mobile: 字符串类型,用于存储商家的联系电话。
- address: 字符串类型,用于存储商家的地址信息。
- create_time: 时间戳类型,记录商家账户创建的时间。
- update_time: 时间戳类型,记录商家信息最后更新的时间。
这些表的设计是相互关联的,例如,商品表中的merchant_id字段将商品与商家表中的特定商家关联起来。
3-商品表
商品表用于存储可供购买的商品信息。
- id: 这是一个整数类型的自增字段,作为商品的唯一标识符(主键)。
- name: 字符串类型,用于存储商品的名称。
- description: 文本类型,用于存储商品的详细描述,可能包括规格、特点、使用说明等。
- price: 小数类型,用于存储商品的价格。这里的格式设置为最多10位数字,其中2位是小数。
- stock: 整数类型,用于存储商品的库存数量。
- category_id: 整数类型,用于存储商品所属类别的ID。这个字段可以与一个商品分类表关联,以实现商品分类。
- merchant_id: 整数类型,用于存储销售该商品的商家的ID。该字段是一个外键,指向商家表中的相应记录。
- create_time: 时间戳类型,记录商品创建的时间。
- update_time: 时间戳类型,记录商品信息最后更新的时间。
4-销售表
销售表(sales)是电商系统的核心业务表,用于记录所有交易行为并支撑销售分析。
该表采用InnoDB引擎确保事务完整性,以下是各字段的详细说明:
- 主键与标识字段 id:自增主键(INT类型),唯一标识每笔销售记录。AUTO_INCREMENT属性确保每次插入新记录时自动生成连续编号,形成天然的时间序列标识
- user_id:用户关联标识(INT类型),通过外键约束FOREIGN KEY关联users表主键,确保销售记录必须对应有效用户
- product_id:商品关联标识(INT类型),通过外键约束关联products表主键,强制每笔交易必须对应有效商品库存
- sale_date:销售日期(DATE类型),精确到天的交易时间戳,用于时间维度分析。建议配合sale_date字段建立复合索引提升查询效率
- quantity:销售数量(INT类型),记录单次交易商品件数,正整数值域限制确保业务逻辑正确性
- unit_price:成交单价(DECIMAL(10,2)),固定两位小数的精确数值存储,避免浮点计算误差。与products表价格字段解耦,保留历史价格快照
- total_amount:自动计算金额(GENERATED ALWAYS AS),通过quantity * unit_price公式实时计算交易总额,STORED类型将计算结果物化存储以提升查询性能
- create_time:记录创建时间(TIMESTAMP类型),DEFAULT CURRENT_TIMESTAMP自动记录数据插入时间,构成不可变审计日志
- update_time:记录更新时间(TIMESTAMP类型)
