
刚刚,英伟达CUDA迎来史上最大更新!
先聊聊大家最关心的工具链更新——Nsight Systems。这次CUDA Toolkit 13.1同步发布的Nsight Systems 2025.6.1,在追踪能力上做了几个很实在的增强。系统级CUDA追踪方面,cuda-trace-scope这个参数一开,就能追踪到跨进程甚至整个系统的行为,debug的视野一下子就打开了。主机函数追踪也补上了,现在cudaGraph里的主机函数节点和cudaLaunchHostFunc()都能被追踪到——这些函数在主机上执行,并且会阻塞stream,追踪它们对理解异步逻辑至关重要。CUDA硬件追踪在支持的环境下已经成了默认模式,想切回软件模式的话,加个--trace=cuda-sw就行。另外,Green Context时间轴行现在会在tooltip里显示SM的分配情况,GPU的资源到底有没有喂饱,看一眼就清楚多了。
数学库
CUDA工具箱里的几个核心数学库,这次也都有新料。
cuBLAS
cuSPARSE
SpMVOp。相比之下,原来的CsrMV API性能已经被它甩开了。它支持CSR格式、32位索引、双精度,还允许用户自定义后缀操作。cuFFT
cuBLAS Blackwell 性能
说到黑威尔架构,最早在CUDA 12.9里就引入了块缩放的FP4和FP8矩阵乘法。到了CUDA 13.1,这些数据类型加上BF16的性能支持已经全面铺开了。图2就是Blackwell和Hopper平台上的加速比实测结果,数值很直观。
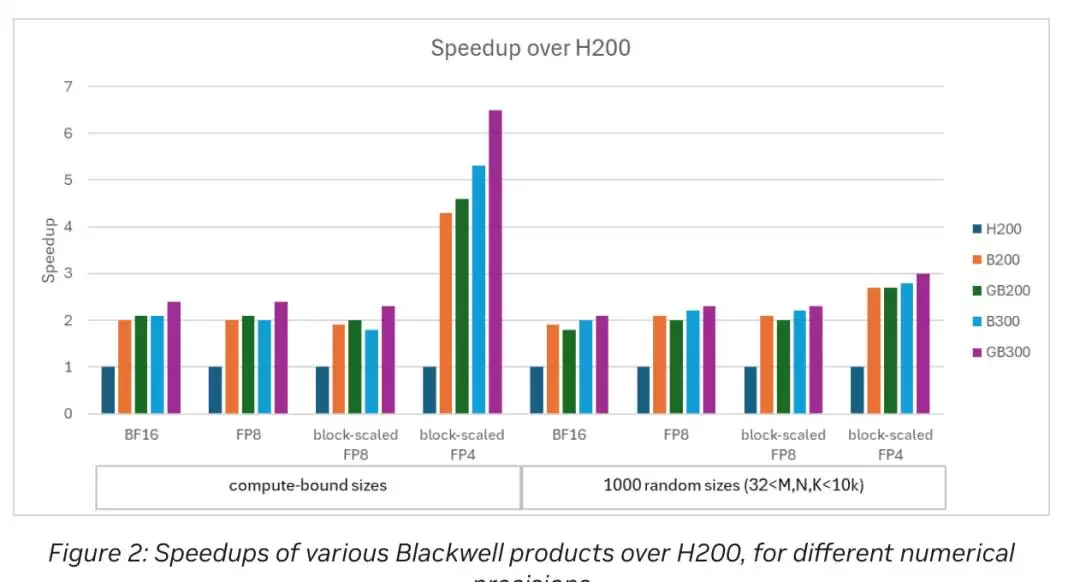
在 NVIDIA Blackwell 和 Hopper 平台上的加速比
cuSOLVER Blackwell 性能
cuSOLVER在CUDA 13.1里继续打磨它的批处理特征分解API,主要是SYEVD和GEEV,性能提升很明显。
批处理SYEV(全称 cusolverDnXsyevBatched)专治那种大量小矩阵的并行求解问题。图3的测试是在批大小5000、矩阵行数24到256的条件下跑的。和NVIDIA L40S比起来,Blackwell RTX Pro 6000 Server Edition差不多快了一倍,这个加速比基本和内存带宽的提升是吻合的。
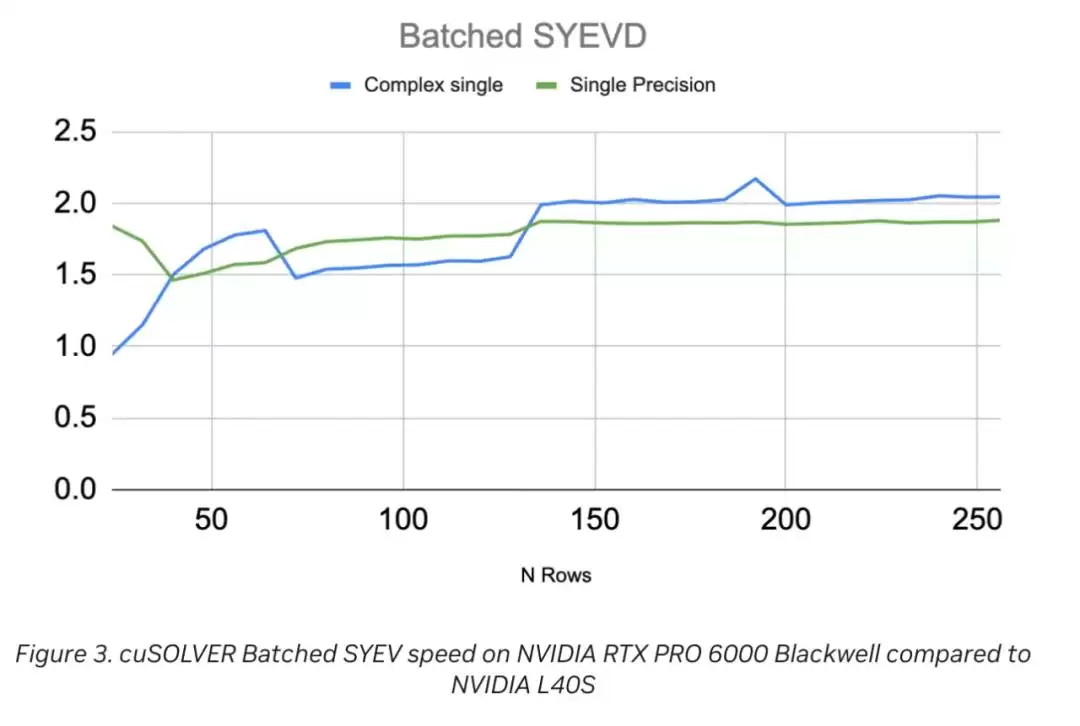
在批大小为 5000(矩阵行数 24–256)的测试结果
具体到数据细节:不管是复数单精度还是实数单精度,当矩阵行数N=5时,加速比大概是1.5倍,然后随着行数增大持续走高,到N=250时稳稳达到2.0倍。
再来看看cusolverDnXgeev(GEEV),这个函数处理的是非对称稠密矩阵的特征值和特征向量。它是个CPU/GPU混合算法,CPU单线程负责QR算法里早期降阶那种高效处理,GPU干剩下的脏活累活。图4给出了矩阵大小从1024到32768的相对加速比。
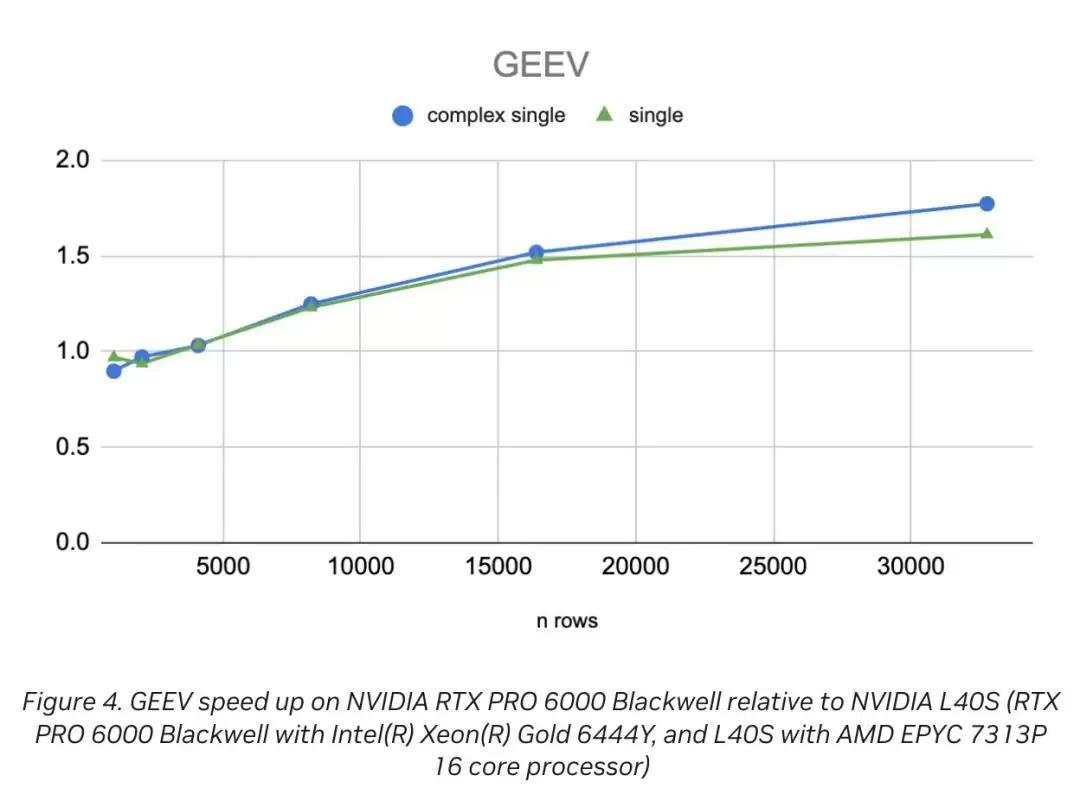
cusolverDnXgeev(GEEV) 的性能加速比
数据很实在:矩阵行数n=5000时,加速比刚好1.0,随着规模扩大逐渐攀升,到n=30000时达到约1.7倍。
NVIDIA CUDA 核心计算库
CCCL这次给CUB带来了两个非常实用的更新。
确定性浮点运算简化
浮点数加法不满足结合律这件事,会导致什么后果呢?历史上cub::DeviceReduce为了保证同一GPU每次运行结果逐位一致,被迫采用了两遍算法。CUDA 13.1搭载的CCCL 3.1现在给了你三个选项,让你在确定性和性能之间自己挑:
- :用原子操作做单次归约,结果不会逐位相同。
不保证
- :基于NVIDIA GTC 2024大会上Kate Clark的演讲成果。结果保证逐位一致。
GPU间
通过一个标志位就能切换这些模式,代码写起来非常直接。
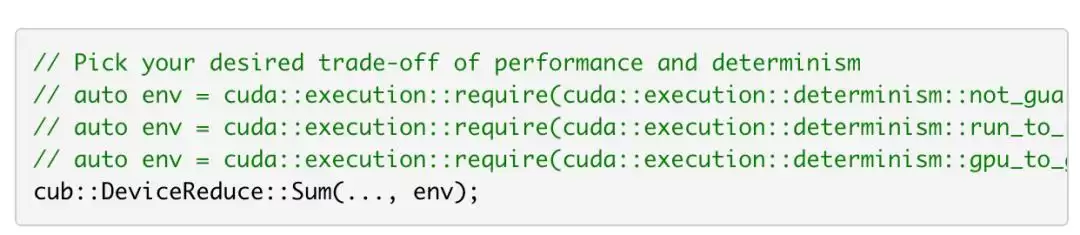
演示代码
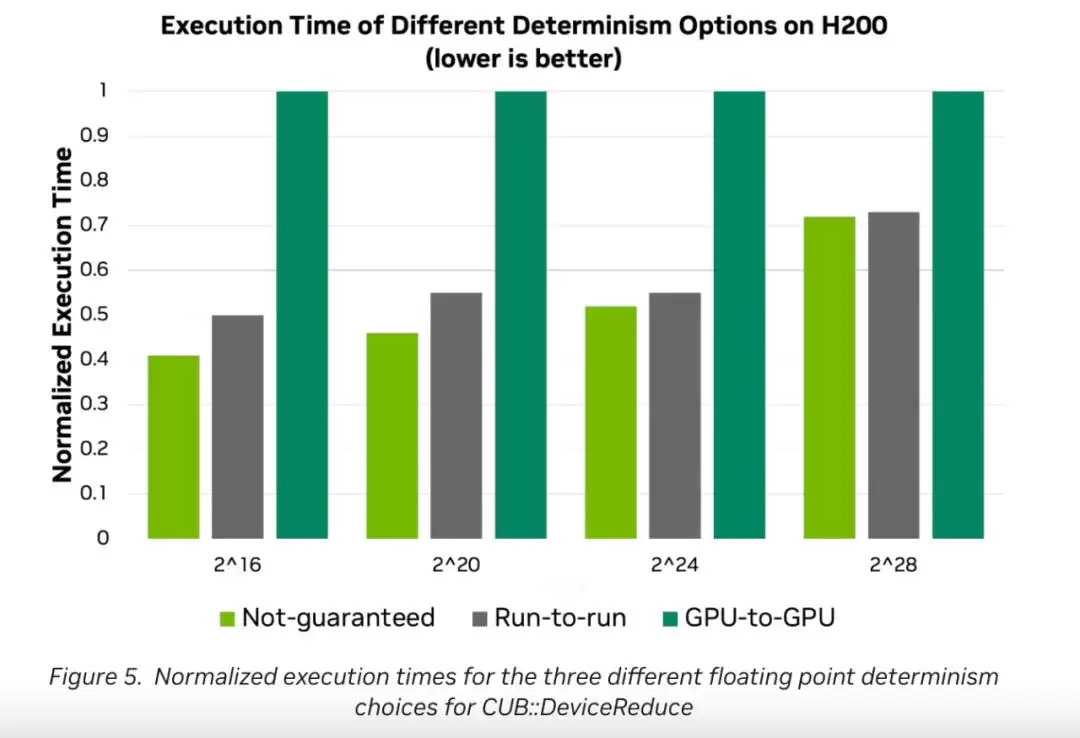
数据对比
更便捷的单相 CUB API
另一个痛点也得到了解决。几乎所有CUB算法都需要临时存储空间,过去开发者必须走一套两阶段模式:先查询临时存储大小,再分配空间,最后释放。这套流程复杂且容易出错——两次调用之间参数稍微对不上,就会出问题。CCCL 3.1为接受内存资源的CUB算法加上了新的重载,直接把临时存储的查询、分配、释放串成了一个步骤,这才是真正的“一次搞定”。

演示代码
