
大模型+数据分析:下一代智能查询优化体系的先行探索
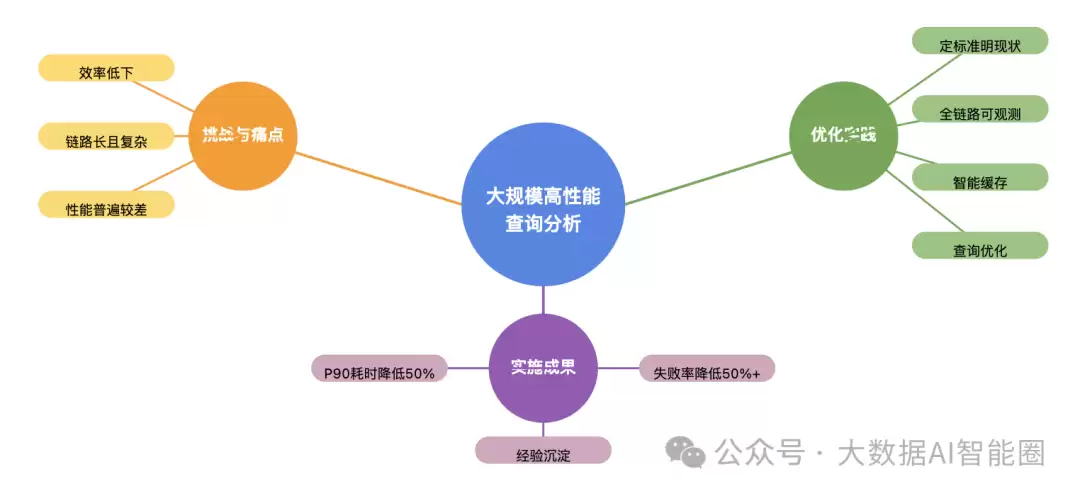
告别AI的定制化表达,我们来聊聊真实的优化实践。当你每天面对万亿级数据、日均百万次查询请求时,你会怎么做?
处理海量数据查询,就像在浓雾中找路——方向拿不准,随时可能迷失。数据负载高到屏幕只显示超时,查询速度慢到你有充裕的时间去泡杯咖啡,再慢悠悠回来检查结果。在这个数据井喷的时代,高效查询分析已经不是可选项,而是数据团队的必修课。
迷雾中的困境
想象一下,你的团队每天要面对百级集群、万级表、数百兆行数的数据,日均数百万次逻辑查询,覆盖数十个业务线。用户那边一边催着“数据出来了吗”,一边默默打开了游戏,等着漫长的查询结果。

查询链路复杂得像迷宫:从产品应用层到平台工具层,再到数据模型层和分析引擎层。用户只是轻点了一个按钮,后台却要在几十个环节里辗转腾挪。一出错,排查就是一场噩梦——是应用有bug?还是模型设计不合理?又或者只是引擎负载过高?
多数查询平台容易陷入两个极端:要么只有少数重点应用性能尚可,大部分场景响应缓慢;要么流畅与深度不可兼得——快则数据浅,深则等到天荒地老。一位分析师坦言:“一个简单查询需要10秒才出结果,复杂一点的直接超时,我的工作效率严重受限。”
迷雾中的指南针
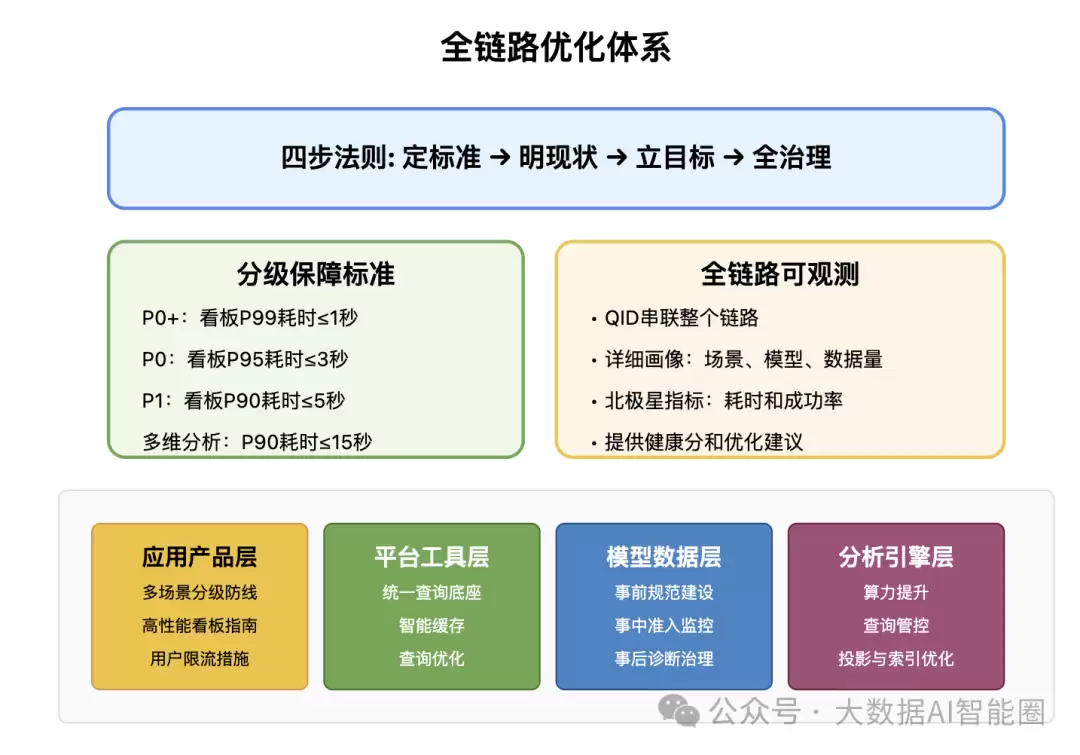
遇到海量数据查询的难题,我们建立了一套全链路优化体系——从应用到引擎,层层突破。这不是简单的修修补补,而是一次全面的系统升级。
首先,建立分级保障标准,区分查询场景的重要性。毕竟,看板和多维分析对性能的要求本就不同——灵活的多维分析自然比固定看板更吃资源。关键业务看板,目标是要做到P99耗时≤1秒的极致体验;多维分析场景,P90耗时≤15秒就算良好。
全链路可观测是打破困局的关键。正如那句老话:"if you cannot measure it, you cannot improve it"。通过唯一的QID串联整个链路,从应用到引擎层层埋点,建立观测看板——不仅显示耗时和成功率,还提供健康分和优化建议,支持多维下钻分析。举个例子,有一次通过看板发现某业务性能瓶颈卡在DB1的table1上,扫描数据量巨大且包含复杂表达式,优化后查询时间直接从12秒降到3秒。
优化的实践从四个层面同步推进:
应用产品层
平台工具层
数据模型层
分析引擎层
一位资深架构师评价得很到位:“这套优化体系的精妙之处在于全链路协同——任何一个环节单独优化,都难以达到这样的效果。”
拨云见日的成果
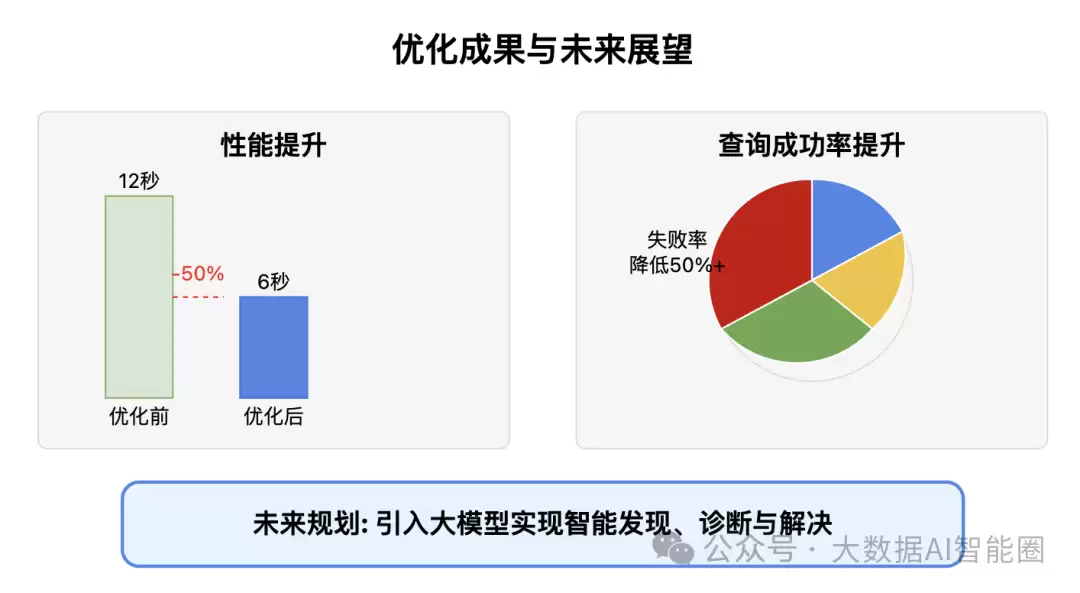
全链路优化的成果令人振奋:查询耗时的P90降低了50%,失败率更是降低了50%以上。性能提升是全方位的——用户日常使用的看板,从平均8秒响应优化到2秒内;多维分析场景,从动辄超时变为15秒内完成。分析师的工作效率因此大幅提升,一位分析师感慨:“以前一天能做5个数据分析场景,现在能做15个,效率提升了200%。”
成功率的提升更是划时代的。用户不再被卡在加载界面,不再面对莫名其妙的超时错误,分析工作流变得流畅自然。技术团队的工作重点,也从疲于应付故障转向了业务优化——这种质变,带来的是整个数据生态的良性循环。
经验的沉淀也是宝贵财富。团队建立了从应用到引擎的全链路治理体系,以及完善的业务服务标准,这些都将持续为后续优化提供指导。
未来,我们计划借助大模型技术,让整套系统更加智能化——包括智能发现、智能诊断和智能解决,逐步实现“自愈能力”。当查询遇到性能问题时,系统能主动识别瓶颈并提供解决方案,甚至自动优化。
就像经历了迷雾的旅人终于看到晴朗天空,大规模数据分析不再是效率杀手,而是成为业务增长的助推器。面对万亿级数据洪流,我们不仅找到了破局之道,更开启了数据智能分析的新篇章。
