
搜索茧房,自由还是陷阱?
相信不少朋友最近都发现了一个有趣的现象:问AI同一个问题,但不同工具给出的答案却千差万别。
前几天,群里有人玩起了“量子速读”,向AI提问:人类最伟大的地方是什么?请用四个字概括。于是大家纷纷晒出自己的答案,五花八门,从“仁者见智”到“不断超越”,再到“爱与和平”。我自己也试了一下,回答是“知行合一”。为了验证是不是工具的问题,又换豆包、Kimi、腾讯元宝问了一圈,果然,每个AI给出的四个字都不重样。
这么一对比,一个念头就冒出来了:都是AI,面对同一个问题,为什么会给出完全不同的答案?是因为模型架构不同,还是训练数据的差异,抑或是对问题的理解逻辑根本不在一个频道上?
反复琢磨之后,隐约觉得,每个AI似乎都带了一套自己的“价值观”或者“视角”在回答问题,就像不同的人,看待同一件事,落脚点总是不一样的。这种差异,很容易让人联想到那个老生常谈的概念——信息茧房。
只不过,以前我们说的信息茧房,是推荐算法的锅。你在哪个视频平台多刷了会儿美食,下次开屏满屏都是探店;你在购物软件上多看了两眼大衣,接下来整整一个星期推荐页都是各种大衣。这种“投其所好”的推荐,看似贴心,实则不知不觉就把人圈在了一个封闭的认知圈里。
但AI搜索工具的普及,让信息茧房换了一张新面孔。当我们在用ChatGPT、Perplexity或是DeepSeek、Kimi这类工具时,信息的获取方式变了。不再是被动的“被推荐”,而是通过自己的“搜索行为”和“提问方式”来主动定制答案。你搜什么、怎么问、愿意接受哪些方向的回答,直接决定了你最终能看到什么。这种新的茧房形式,或许可以称为——「搜索茧房」,或者更形象一点,叫「生成式幻觉茧房」。
那么,这个新东西跟传统的信息茧房比,区别到底在哪儿?
形式上的区别很直观。
传统信息茧房是被动的。坐在沙发上刷视频、刷新闻,都是算法在后台默默观察:你点了什么、看了多久、收藏了什么,然后它来给你“喂”内容。你基本不用自己动手去“找”,就已经被温柔地框在一个圈里了。
搜索茧房更像是自己主动走进圈子的。你输入什么关键词,AI就给你生成什么答案。这个过程里,AI有没有偷偷看你的手机习惯?不太确定。但有一点很明显:你和你选的工具在一个对话框里聊久了,它会越来越懂你,越来越顺着你的喜好来回应。它用它那高大上的推理模型,悄无声息地就把你给“圈养”了。
内容生成的机制完全不同。
传统茧房里的内容,是平台上已经存在的。你翻来覆去看到的,都是别人已经发布过的同质化内容。
搜索茧房的核心是“生成”。答案并不存在,它是AI当下根据训练数据和算法现场“捏”出来的。这过程你完全看不见,就算它标个引用来源,但它结合上下文“造”出来的那部分,仍然无法摆脱它学过的知识和它的理解偏好。所以,拿到手的答案,很可能只是某种“特定版本”的真相。
参与感和隐蔽性的巨大差异。
传统信息茧房里,用户最多就是点个赞、刷个屏,参与感有限。而且当内容高度重复、你感到厌烦时,往往能意识到自己被困住了,产生反感,甚至开始警觉。
搜索茧房看起来把主动权交给了你——提问的权力在你手中。但真相是,这个主动权并没有完全在你手里。你的提问方式、用词习惯,甚至选择哪个工具,都在隐形地筛选答案。这些限制是隐藏的,很难察觉。一个更隐蔽的问题是:当你提出一个问题并立刻得到一个答案时,很容易误认为“我选的是对的”,而不会怀疑自己其实正被带向一条狭窄的路径。比如,你问AI一个新闻事件,它给了你一个答案,你可能就以为这代表了全部事实,殊不知那可能只是按某种逻辑重构的“切片”。
说白了,这两种茧房在时间维度和依赖性的培养上也不一样。传统算法推荐是“养成系”,慢慢把你养在舒适圈里;主动搜索则是“定制系”,你有需求它就马上量身定做。这种定制每次都能快速给出答案,但用的时间越长,你就越依赖它,最后连多找几个资料核实的耐心都没了。
举个例子,有一次我在小红书上看到“CDPP”这个缩写,完全不知道是什么,顺手用某个AI搜了一下,结果说是“处对象”。我觉得挺潮,就这么认了。后来好奇,又用百度搜,结果出来“彩带飘飘”。两个答案完全不一样!这种快速得到答案的体验,会让人越来越懒,甚至连“这到底对不对”的疑问都懒得提了。
所以归根结底,搜索茧房是传统信息茧房的一次升级。它披着“聪明”和“主动”的外衣,表面上是你自己在掌控,实际上悄悄把你框在了一个小世界里。
说起来,AI为什么会产生搜索茧房?这背后有几个绕不开的原因。
首先是AI自身的“性格”。
从用户的角度看,AI的核心任务就是提供“最好的答案”。每次用它搜索,它都靠算法和数据给你一个看起来很满意的答复。问题是,AI的知识和处理方式,本身就是有“性格”的。好比同样是推理模型,DeepSeek的答案很理论、很专业,像个学院派专家;而Kimi的回答就比较口语化、接地气,像个聊天高手。这种差异,来源于它们训练数据的侧重和模型设计的差异。你习惯用哪一种,你的信息视角就可能被固定在哪个方向上。
其次,用户自己也在“帮倒忙”。
很多人有个习惯,如果AI的回答不是自己想要的,会直接告诉它“这不是我想要的”。久而久之,在同一个对话框里,AI会根据你的反馈不断调整答案。双方在持续互动中互相强化,茧房的墙就越来越厚了。
最后,绕不开的商业逻辑。
AI工具不会永久免费,怎么赚钱?当然是希望用户用得越多越好,最好离不开了。Perplexity每月要收订阅费,免费用户会看到植入广告。这股力量驱动着AI搜索走向“千人千面”的设计。虽然国内大部分产品还没收费,但它们在隐性地收集语料。记得OpenAI的创始人奥特曼说过,要实现通用人工智能(AGI),AI得像自动驾驶一样,根据不同人的需求提供定制化服务。换句话说,AI必须满足每个人的独特需求。所以,“搜索茧房”这件事,是技术特性、使用习惯和商业逻辑共同作用的结果。
那么问题来了,搜索茧房一定是坏事吗?其实也不一定。
从商业视角看,它可能打开一种全新的“效率”。“前两天刷抖音,看到小米的王腾和许斐被人调侃像夫妻。我挺好奇,就搜了一下。抖音搜索说他们是夫妻,我还有点惊讶。结果用豆包一搜,说俩人只是同事。我把这事儿发到群里,有字节的朋友转发给了内部处理。”
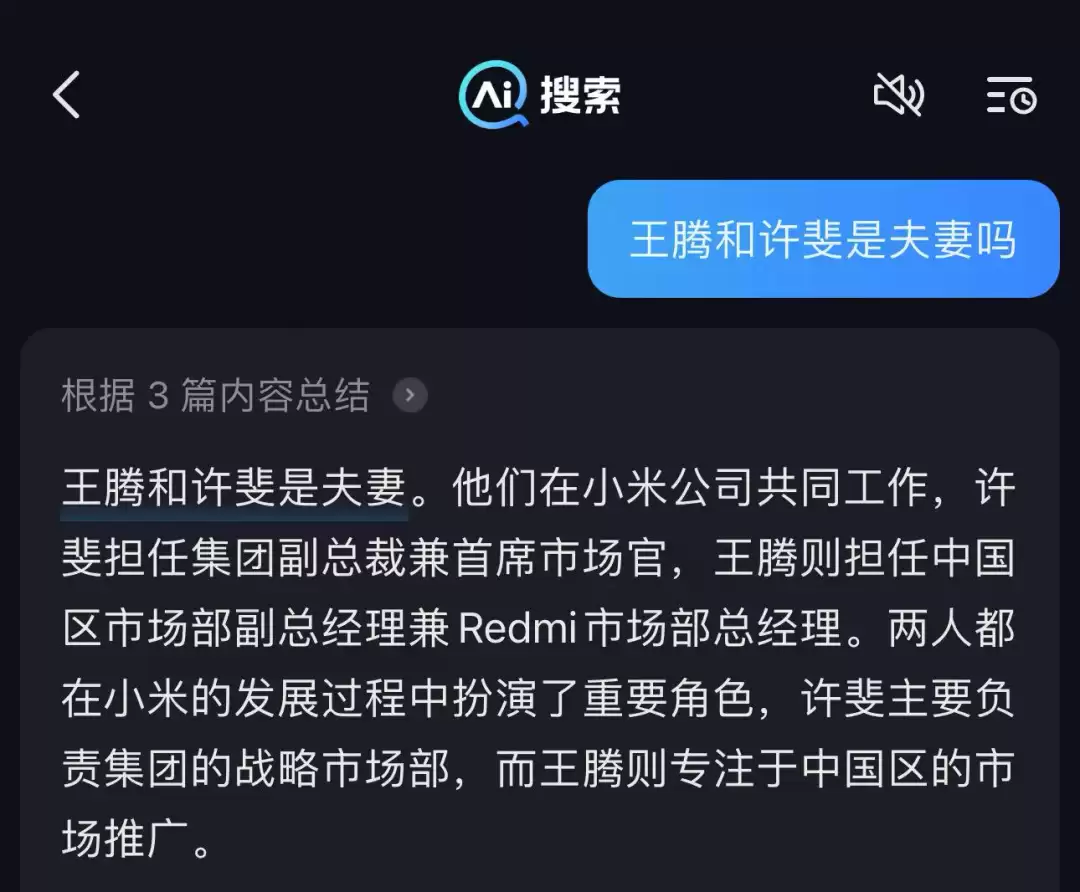
说到底,这是AI学的语料被污染了。但换个角度,从品牌方、营销方的立场看,这事儿太常见了。他们会批量生产关于自家品牌的内容,通过各种渠道喂给AI。这样一来,别人搜相关问题,看到的就是定制化的答案,就像一种软性植入。对商业来说,这是精准找到目标用户、提升效率的好方法;但对用户来说,感觉就像被困在一个“定制化”的信息茧房里。
前阵子有朋友跟我说,给AI做SEO最好的办法,是在一篇文章里埋入大量关键词,或者频繁提及某些东西,让AI抓取效率变高。还有人说,多生产长内容,因为AI会判定这些内容质量高。从商业角度看,这些操作确实能搞定精准流量,但对终端用户而言,信息的丰富性和多样性就打了折扣。
不管怎么说,还是要小心别被AI搜索“茧房”给困住了。实践中总结了一些方法,可以试试看。
初级实操:建立基础防弹衣。
- 别只用单一工具。今天用Kimi,明天试试腾讯元宝,后天换豆包。不同AI有不同“性格”,一个问题多问几个AI,答案会更丰富。
- 多反问。想知道“为什么AI好”,也可以反过来问“为什么AI不好”。让AI帮你反思,它会从不同视角给出答案。
- 别只看AI给的答案。你想让AI验证新闻的真伪或数据出处,不妨自己手动去查一下,避免被误导。
中级玩法:玩转提问策略,跟AI“斗智斗勇”。
试着换着花样更新提问方式。比如别总用黄金圈法则、5W2H法则,可以组合着用,甚至自创一套提问方式。提问时,不妨让AI把商业、心理、伦理这几个角度揉到一起,这样答案的视角就完全变了。因为AI学的内容多少是按学科分类的,交叉着问,有点像打破了规则,逼它从不同方向给你讲明白,答案自然就丰富了。
还有就是换着花样问问题。想知道“AI怎么改变生活”,可以换成“AI在哪些意想不到的地方影响了我们?”或者“AI给普通人添了什么麻烦?”这么一调整,问题维度就变了,更像多维探索,而不是正向思考。
高阶阶段:人工核查依然是王牌。
有些东西,AI在短问短答时还能答对,但一旦连着问好几轮,就容易出现幻觉,尤其是人名、日期这类细节。所以,多核实信息,甚至故意找找对立面的材料,穿插着用。这样,就不容易被AI套牢了。
最重要的一点:建立起一个重新认识搜索茧房的思维方式。毕竟,你看到的,才是你的世界。就像王阳明所说的“心外无物”——我们所感知的世界,很大程度上是由内心认知决定的。只有主动去拓宽视野,多方对比,交叉验证,才能真正打破搜索茧房带来的局限。
